




 该篇博客主要讲解了吴恩达机器学习课程中关于过拟合的问题和正则化的概念。过拟合表现为模型在训练数据上表现良好,但在新数据上泛化能力差。解决过拟合的方法包括减少特征数量和使用正则化。正则化通过添加惩罚项使模型参数变小,防止模型复杂度过高。在正则化线性回归中,梯度下降和正规方程被用来求解最小化带正则化的代价函数。此外,逻辑回归的正则化与线性回归类似,也是在损失函数中添加正则化项。
该篇博客主要讲解了吴恩达机器学习课程中关于过拟合的问题和正则化的概念。过拟合表现为模型在训练数据上表现良好,但在新数据上泛化能力差。解决过拟合的方法包括减少特征数量和使用正则化。正则化通过添加惩罚项使模型参数变小,防止模型复杂度过高。在正则化线性回归中,梯度下降和正规方程被用来求解最小化带正则化的代价函数。此外,逻辑回归的正则化与线性回归类似,也是在损失函数中添加正则化项。
文章目录
课时55过拟合问题09:42

1欠拟合:高偏差,有偏见,枉顾数据强行认为是线性
3过拟合:不停上下波动 算法具有“高方差”,难以泛化


后面讲到调试和诊断导致算法出错时,会讲专门工具识别是否过拟合欠拟合
一二维数据可以画图来判断拟合几次多项式—画图是一个方法
缺点:很多变量时画图难、通过可视化来判断保留哪些特征也难。
如果特征多而数据少就会过拟合。
解决办法:
①减少特征数量:人工观察
缺点:舍弃变量也可能舍弃信息
②正则化:保留所有特征,但减少量级或者参数大小
课时56代价函数10:10
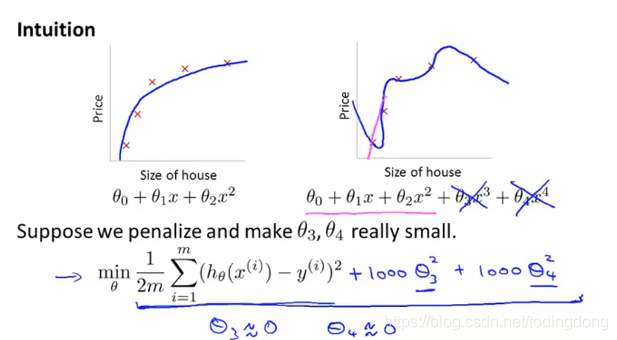
让某些系数变小的方法:加入惩罚项
❤使模型参数尽量小就能简化模型(我知道你现在不太理解,除非你去实现观察一下)
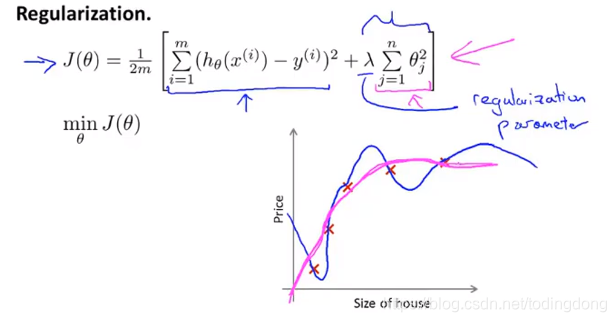
❤注意:
①惯例不对θ0进行惩罚
②正则化参数λ太大会导致参数太小,导致θ趋于0得到一条平行于x轴曲线,→欠拟合
③J(θ)前的1/2主要为了求导方便
课时57线性回归的正则化10:40
线性回归求解方法: ①梯度下降 ②正规方程(β=(X转X)逆 X转 y)用梯度下降法使正则化线性回归的代价函数最小
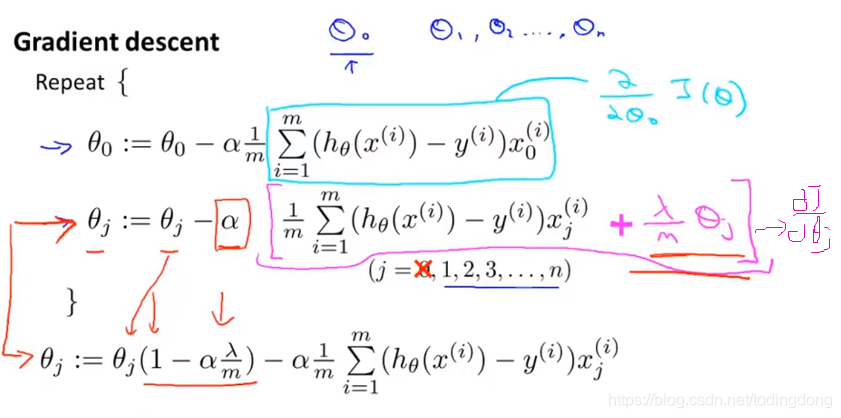
独列出θ0因为θ0不作惩罚
结果:
正则化对比不正则化就是:令θj(j≥1)减少了一个额外的值 αλ/m*θj,或者说是θj迭代前乘了一个比1略小的值(1-αλ/m)
一般来说学习率α会比较小,m会比较大,所以(1-αλ/m)只比1略小一点
正规方程求解线性回归结果如下:

E的左上角是0,还是因为θ0不惩罚。
结果就是逆里加个 λ E变形(左上角是0的)
选修:当m是样本总数<特征数n
则X转置X是奇异矩阵(不可逆)
但是正则化考虑到了这个问题
只要λ严格0则(X转X+λE变形)一点是可逆的
课时59本章课程总结
- 什么是过拟合,欠拟合
- 画图可以判断过拟合还是欠拟合
- 有2种可以解决过拟合的方法:减少特征数,或者减小θ
- 线性回归的过拟合解决方法:损失函数加正则化项(属于减小θ的方法)
- 正则化线性回归的算法:梯度下降→θj迭代之前乘以一个比1小点的数,正规方程→[X转X+λE变形(左上角为0)]的逆 x转y
- 特别地,如果λ>0,即使样本数m<特征数n,也能保证[]括号内可逆
课时60编程作业:Logistic 回归(略,作业单独开博)
课时61Logistic 回归的正则化08:33
改价梯度下降和另一种更优化的算法
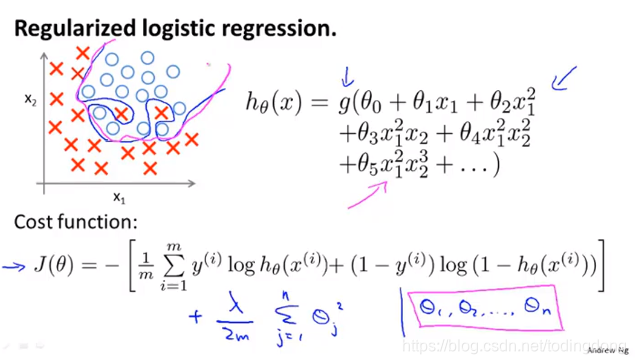
正则化逻辑斯蒂回归的损失函数是加一项,和线性的一样=λ/(2m) Σθ^2,θ从1开始

梯度下降原理仍然是 θj=θj-αJ’,只是J不同而已。结果看起来和线性的一样,θ0仍旧不参与正则化。
但是我们知道:
线性的h(x)=θ转X
而逻辑斯蒂回归的h(x)=g(θ转x)

这个是吴恩达的软件代码。costfunction表示无约束条件小最小值,主要展现梯度下降的流程。
自我小结:
每一步 我们都要轮换j,求J对θj的偏导 ,代入θj=θj-αJ’对θj进行更新。所有θj都求完了就得到这一步的θ
然后又开始下一步(迭代公式里的h与θ有关,所以更新某个 θj系数 其实也要用到其他的θj的上一步迭代结果)
正则化的线性或者逻辑回归模型第j个x的系数迭代公式为:
θj= θj(1-αλ/m)-α/m Σ[ (h-y)xj ]
Σ里面是对样本 i 进行轮换
注意: h与θ有关
i从1到m,表示样本数,一行一个样本(样本数增加行数增加)
j从1到n,表示特征数,一列一个特征(样本数增加列数不变)
xj表示第j个x
xij表示第i个样本的第j个特征
(注意:线性回归的数据矩阵是有x0的,也就是从0开始,第一列 Xi0 都是1)
一个特征在一列
一个样本在一行

















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









