




 本文详细介绍了逻辑斯蒂回归的基本概念及其应用,包括sigmod函数的意义、决策边界、代价函数的推导及优化方法,并探讨了如何将逻辑斯蒂回归应用于多分类问题。
本文详细介绍了逻辑斯蒂回归的基本概念及其应用,包括sigmod函数的意义、决策边界、代价函数的推导及优化方法,并探讨了如何将逻辑斯蒂回归应用于多分类问题。
文章目录
因为有各位大佬的珠玉笔记在前,我的笔记只记录自己觉得要记的点
资料:
视频地址:
https://study.163.com/course/courseMain.htm?courseId=1004570029
觉得不错的大佬笔记:
http://www.ai-start.com/ml2014/
https://blog.youkuaiyun.com/malele4th/article/category/7394558
课时46分类08:08
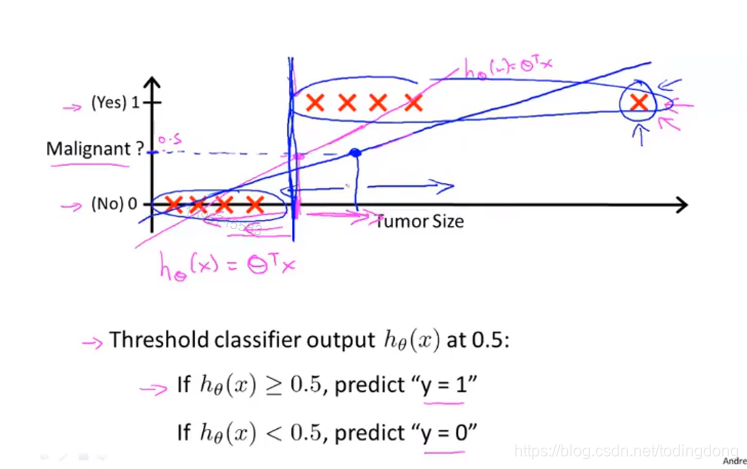
为什么设立一个阈值,继续用线性回归来解决分类问题是不行的?
因为如果有很远处的×点,会导致阈值非常偏右,但是我们知道阈值应该在中间
课时47假设陈述07:24
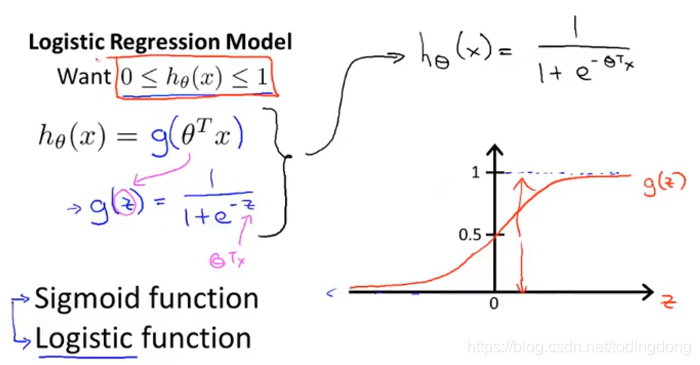
sigmod函数=logistic函数

❤逻辑斯蒂函数的意义:表示x=1的概率
课时48决策界限14:49
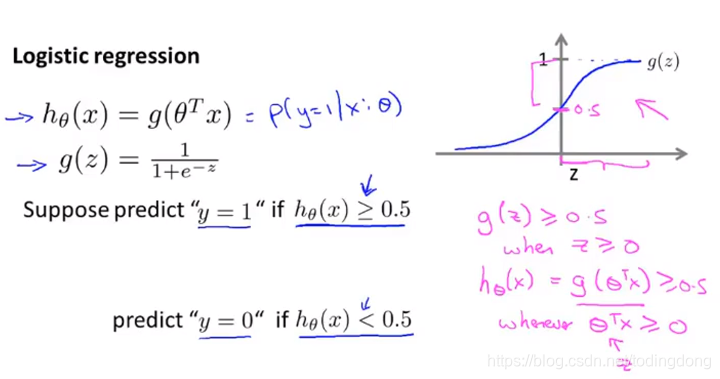
h≥0.5就预测y=1,也就是 θ转置x ≥0就预测y=1

- 而 θ转置x ≥0表示的是一条直线,所以如果我们估计出了θ,就相当于用一条直线作为决策边界
- 直线是假设函数的属性,不是数据集的属性。我们通过训练集找θ的时候其实不用把训练集数据点画出来(下一节会讲怎么估计θ)
边看边提问:似乎还是没说这样能否解决异常远的点造成的问题?
思考:可以,如果有一个数据点的xi=+∞且θi>0,就会导致h(x)=∞,肯定会判到y=1那边。或者说是我们先把θX 压缩到0-1空间上变成h(θX)再与y进行线性回归,应该是一种广义线性回归,那么无论多遥远趋于无穷大的值都变到1附近,对我们的回归影响就没有那么大了,也就是说,大到一定程度的点再变大也对判断没有啥作用,相近的点作用大

- 当数据点的图是这样的咋分?
- 答案:添加额外的高阶项——参考前面的多项式回归
可能还是要补看前面的多项式回归,跳着看不连贯
❤得到的边界可能是个圆形,甚至是非常复杂形状
课时49代价函数10:23

附带一张李宏毅老师讲分类问题时的图,也就是我们可以定义不同的损失函数产生其他的分类方法

❤对逻辑斯蒂损失函数用极大似然估计来求θ (而不是最小二乘法)
❤它是凸的
个人思考:
❀h(x)如果≥0.5,比如是0.8就会判定y=1,
如果正确,损失函数-log(h)=log1.25。
如果判错,损失函数-log(1-h)=-log0.2=log5,比判断正确要大。
❀h(x)如果≤0.5,比如是0.2就会判定y=0,
如果正确,损失函数-log(1-h)=-log0.8=log1.25。
如果判错,损失函数-log(h)=-log0.2=log5,比判断正确要大。
换个角度总结:
❤h=0.5时,不管判断正误,cost都=log2
❤h判断正确的cost都≤log2,错误的cost都>log2
换个角度总结:
❀y=1时,我们看y=1的概率h,h越大则cos=-logh越小【减】
❀y=0时,我们看y=0的概率,h越大(1-h越小)则cos=-log(1-h)越大【增】
❤使得真实事件发生概率大的h,cost比较小

❤损失函数J(θ)表达式如上

❤梯度下降法迭代公式
h是sigmod函数,它有个很好的性质:
❤对狗求导:h’(狗)=h(1-h)
当狗=θ转置x,对θj求导时h’=h(1-h)xj
特征放缩可以提高梯度下降法的速度,不仅在前面线性回归可以用到,逻辑斯蒂回归也可以用
补充特征放缩知识
课时50简化代价函数与梯度下降10:14
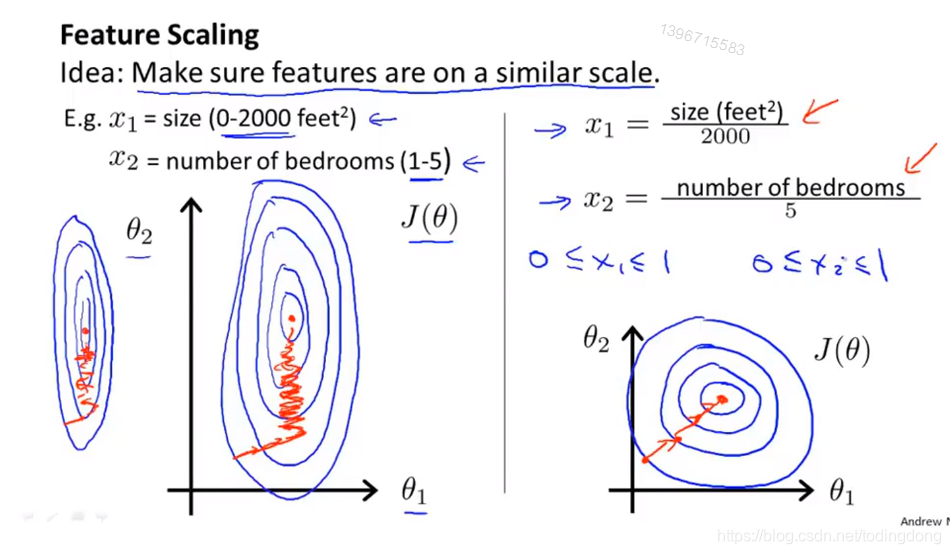
假设有2个特征x1和x2,如果x1的范围比x2大很多,是它的n倍,那么等高线如左图所示是个长椭圆,会导致梯度下降法在走弯弯曲曲的折线。
如果通过右边的放缩,把x1与x2的范围调到相近,那么等高线会比较像一个圆,梯度下降法就会走接近直线了
自问自答:为啥呢?
因为梯度下降的方向与等高线的切线方向垂直,我们看椭圆上一点的法向量并不
指向椭圆心(特殊4点除外),会有所偏离,椭圆越长可能这种偏离就越厉害,造成梯度下降法弯弯曲曲。

所以我们先把特征们放到-1到1的范围,当然也不要完全严格,-3到3可以。
-1/3到1/3也可以。只要差距不是太大就可以,这样梯度下降法就能很好地工作
课时51高级优化14:06

这些算法其实不用深入理解就可以用,吴大大也是用了十年最近才深入理解。
缺点:比梯度下降法复杂
除非你是数值计算方面的专家,否则不要自己去实现
比如计算根号2,直接调用软件库,不要自己搞
用C++或者java的话可以多试几个库,因为不同的库实现这些算法的表现是不一样的
参考:
❀最速梯度法(每一条路径与上一条垂直,步长靠搜索或者一些算法比如Goldstein-Armijo ,Barzilai-Borwen等)
❀共轭梯度法(每一条路径与上面所有条施密特正交化后的路劲垂直,N维空间最多N步结束迭代)
❀DFP算法(拟牛顿,用Gk矩阵(正定)作为牛顿法中海塞矩阵Hk逆 的近似,有公式保证每一步Gk都正定)
❀BFGS算法(拟牛顿法(找其他矩阵Bk近似还塞矩阵Hk)的一种,同理初始B0正定则每个Bk正定)
❀LBFGS(BFGS每次都要存储Dk,需要内存大,此法通过存储最近m次迭代的少量数据来替代海赛矩阵,D初值还是单位矩阵)
❀迭代尺度法(类似em算法,最大熵模型常用)
❀Broyden类算法(Gk+1=a G(DFP)+(1-a)G(BFGS),也就是用 由DFP法得到的Gk+1 和 BFGS法得到的Gk+1 的线性组合
(仍满足拟牛顿法条件)来作为替换 海赛矩阵的逆 的Gk+1)
课时52多元分类:一对多06:15
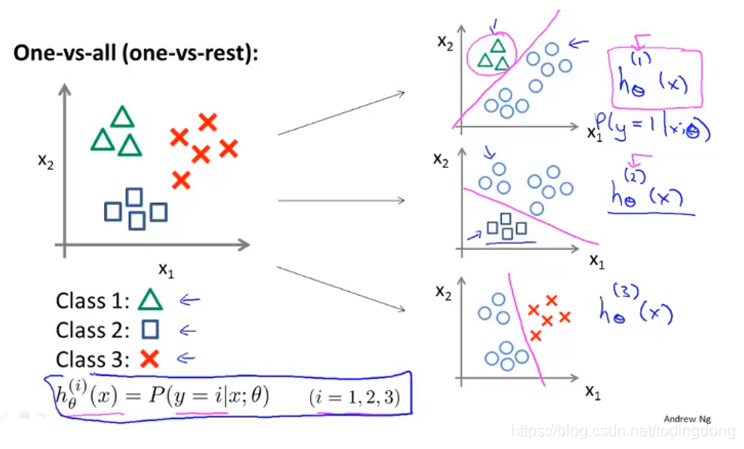
把分3类问题转化为3个分两类问题
每个小图 h1(x)表示x是class 1三角形的概率,h2=正方形概率,h3=×的概率

那么回到分3三类问题
输入x,看hi(x)哪个大,x就是第i类的
这样就可以将逻辑斯蒂回归用到多分类问题上
课时53本章课程总结
本章讲述了
-
分类问题就是找决策边界(还不一定是直线)
-
逻辑斯蒂回归模型(对θ转X 进行sigmod函数化,再与y线性回归)
- h是y的预测函数(逻辑斯蒂回归里也就是分到1类的概率)=g(θ转x)
-
损失函数(=负的交叉熵)=-ylogh-(1-y)log(1-h)
-
使损失函数最小的参数就是模型估计参数,h含有参数θ,我们要求的是θ使损失函数最小
-
梯度下降法θj=θj-αJ’ ,J’是代价函数对xj求偏导
- 特征放缩:特征x1与x2取值范围差距太大就要放缩到近似的范围内
- 逻辑斯蒂回归的梯度下降法结果:θj=θj-α/m Σ【(h-y)xj】
- 其中Σ加和的是样本i,(i一般加括号写在右上角),i从1到m,
-
其他算法:建议直接调包,不要自己懂原理了来造出来
-
如何把逻辑斯蒂回归用到多分类问题上:
- 分k类问题先拆分成 k个二分类问题
- 用上面的方法求每个问题的θ,确定好每类的hi
- i=arg max hi(x),就是把x分到第i类

















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









