



回归:有一些数据点,我们利用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称回归
Logistic回归的一般过程
(1) 收集数据:采用任意方法收集数据。
(2) 准备数据:由于需要进行距离计算,因此要求数据类型为数值型。结构化数据格式则最佳。
(3) 分析数据:采用任意方法对数据进行分析。
(4) 训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。
(5) 测试算法:一旦训练步骤完成,分类将会很快。
(6) 使用算法:首先,我们需要输入一些数据,并将其转换成对应的结构化数值;接着,基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
5.1 基于 Logistic 回归和 Sigmoid 函数的分类
Logistic回归:寻找一个非线性函数Sigmoid的最佳拟合参数。
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
适用数据类型:数值型和标称型数据。
Logistic回归分类器:在每个特征上都乘以一个回归系数,然后把所有的结果值相加,将这个总和代入Sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5即被归入0类。Logistic回归是利用Sigmoid函数阈值在[0,1]这个特性。
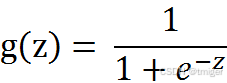
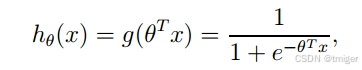
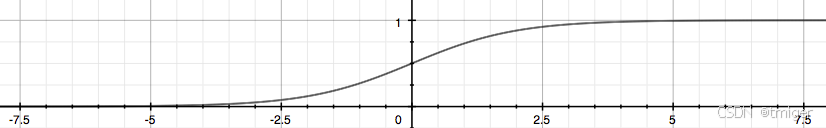
5.2 梯度上升法
Sigmoid函数的输入记为z,由下面公式得出:
z=w0x0+w1x1+w2x2+...+wnxn
采用向量的写法,向量x是分类器的输入数据,向量w也就是我们要找到的最佳参数(系数)
梯度上升法基于的思想是:要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为∇,则函数f(x,y)的梯度由下式表示: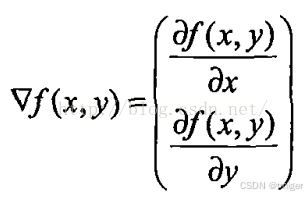
其中,函数f (x,y)必须要在待计算的点上有定义并且可微。
梯度算子总是指向函数值增长最快的方向。移动量的大小称为步长,记做α,梯度上升算法的迭代公式如下: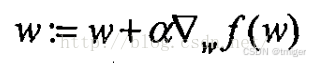
5.3 训练算法:找到最佳回归系数
使用梯度上升法找到最佳回归系数,也就是拟合出Logistic回归模型的最佳参数。
梯度上升法的伪代码如下:
每个回归系数初始化为1
重复R次:
计算整个数据集的梯度
使用alpha × gradient更新回归系数的向量
返回回归系数
5.4 训练算法:随机梯度上升
梯度上升算法在每次更新回归系数时都需要遍历整个数据集,数据集多时计算复杂度太高。改进方法是一次仅用一个样本点来更新回归系数,该方法称为随机梯度上升算法。随机梯度上升算法可以写成如下的伪代码:
所有回归系数初始化为1
对数据集中每个样本
计算该样本的梯度
使用alpha × gradient更新回归系数值
返回回归系数值

















 5431
5431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









