



元算法:将不同的分类器组合起来,通过组合多个学习器来完成学习任务,这种组合结果被称为集成方法或者元算法
7.1 基于数据集多重抽样的分类器
1、Bagging
Bagging即自举汇聚法(bootstrap aggregating),Bagging对训练数据采用自举采样(boostrap sampling),即有放回地采样数据,是在从原始数据集选择S次后得到S个新数据集的一种技术。每个数据集都是通过在原始数据集中随机选择一个样本来进行替换而得到。
每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
每次使用一个训练集得到一个模型,k个训练集共得到k个模型。
对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
2、Boosting
Boosting是采用重赋权(re-weighting)法迭代地训练基分类器。通过集中关注被已有分类器错分的那些数据来获得新的分类器。
每一轮的训练数据样本赋予一个权重,并且每一轮样本的权值分布依赖上一轮的分类结果。
基分类器之间采用序列式的线性加权方式进行组合。
AdaBoost算法是基于Boosting思想的机器学习算法,AdaBoost是adaptive boosting(自适应boosting)的缩写。
AdaBoost的一般流程:
(1) 收集数据:可以使用任意方法。
(2) 准备数据:依赖于所使用的弱分类器类型,本章使用的是单层决策树,这种分类器可
以处理任何数据类型。当然也可以使用任意分类器作为弱分类器,第2章到第6章中的
任一分类器都可以充当弱分类器。作为弱分类器,简单分类器的效果更好。
(3) 分析数据:可以使用任意方法。
(4) 训练算法:AdaBoost的大部分时间都用在训练上,分类器将多次在同一数据集上训练
弱分类器。
(5) 测试算法:计算分类的错误率。
(6) 使用算法:同SVM一样,AdaBoost预测两个类别中的一个。如果想把它应用到多个类
别的场合,那么就要像多类SVM中的做法一样对AdaBoost进行修改
7.2 AdaBoost:基于错误提升分类器的性能
AdaBoost运行过程:
1、计算样本权重
训练数据中的每个样本,赋予其权重,即样本权重,用向量D表示,这些权重都初始化成相等值。
2、计算错误率
利用第一个弱学习算法h1对其进行学习,学习完成后进行错误率ε的统计:

3、计算弱学习算法权重
弱学习算法也有一个权重,用向量α表示,利用错误率计算权重α:
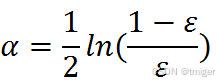
4、更新样本权重
在第一次学习完成后,需要重新调整样本的权重,以使得在第一分类中被错分的样本的权重,在接下来的学习中可以重点对其进行学习:
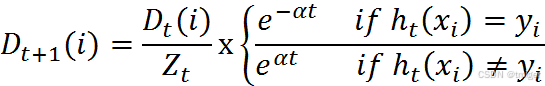
其中,ht(xi) = yi表示对第i个样本训练正确,不等于则表示分类错误。Zt是一个归一化因子:Zt=sum(D),化简得:
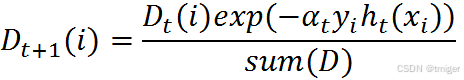
5、AdaBoost算法迭代
重复进行学习,这样经过t轮的学习后,就会得到t个弱学习算法、权重、弱分类器的输出以及最终的AdaBoost算法的输出
7.3 基于单层决策树构建弱分类器
建立AdaBoost算法之前,我们必须先建立弱分类器,并保存样本的权重。弱分类器使用单层决策树(decision stump),也称决策树桩,它是一种简单的决策树,通过给定的阈值,进行分类。
1、数据集可视化
为了训练单层决策树,我们需要创建一个训练集。
2、构建单层决策树
通过构建多个函数来建立单层决策树,设置一个分类阈值,第一个函数将用于测试是否有某个值小于或者大于我们正在测试的阈值。第二个函数则更加复杂一些,它会在一个加权数据集中循环,并找到具有最低错误率的单层决策树。通过遍历,改变不同的阈值,计算最终的分类误差,找到分类误差最小的分类方式,即为我们要找的最佳单层决策树。
这个程序的伪代码大致如下:
将最小错误率minError设为+∞
对数据集中的每一个特征(第一层循环):
对每个步长(第二层循环):
对每个不等号(第三层循环):
建立一棵单层决策树并利用加权数据集对它进行测试
如果错误率低于minError,则将当前单层决策树设为最佳单层决策树
返回最佳单层决策树
7.4 完整 AdaBoost 算法的实现
整个实现的伪代码如下:
对每次迭代:
利用buildStump()函数找到最佳的单层决策树
将最佳单层决策树加入到单层决策树数组
计算alpha
计算新的权重向量D
更新累计类别估计值
如果错误率等于0.0,则退出循环
AdaBoost算法的输入参数包括数据集、类别标签以及迭代次数numIt,其中numIt是在整个AdaBoost算法中唯一需要用户指定的参数。
向量D非常重要,它包含了每个数据点的权重。一开始,这些权重都赋予了相等的值。在后续的迭代中,AdaBoost算法会在增加错分数据的权重的同时,降低正确分类数据的权重。D是一个概率分布向量,因此其所有的元素之和为1.0。
AdaBoost算法的核心在于for循环,该循环运行numIt次或者直到训练错误率为0为止。循环中的第一件事就是利用buildStump()函数建立一个单层决策树。该函数的输入为权重向量D,返回的则是利用D得到的具有最小错误率的单层决策树,同时返回的还有最小的错误率以及估计的类别向量。
alpha值会告诉总分类器本次单层决策树输出结果的权重。
7.5 分类器性能评价
1、混淆矩阵
错误率指的是在所有测试样例中错分的样例比例。实际上,这样的度量错误掩盖了样例如何被分错的事实。利用混淆矩阵就可以更好地理解分类中的错误,如果矩阵中的非对角元素均为0,就会得到一个完美的分类器。

对一个简单的二类问题,如果将一个正例判为正例,那么就可以认为产生了一个真正例(True Positive,TP,也称真阳);如果对一个反例正确地判为反例,则认为产生了一个真反例(True Negative,TN,也称真阴)。相应地,另外两种情况则分别称为伪反例(False Negative,FN,也称假阴)和伪正例(False Positive,FP,也称假阳)。
各个指标的定义及含义
(1)Accuracy
模型的精度,即模型预测正确的个数/样本的总个数
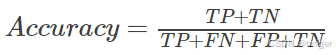
(2)Positive predictive value(PPV,Precision)
正确率,阳性预测值,在模型预测为正类的样本中,真正的正样本所占的比例。

(3)False discovery rate(FDR)
伪发现率,也是错误发现率,表示在模型预测为正类的样本中,真正的负类的样本所占的比例

4)False omission rate(FOR)
错误遗漏率,表示在模型预测为负类的样本中,真正的正类所占的比例。即评价模型"遗漏"掉的正类的多少。
![]()
(5)Negative predictive value(NPV)
阴性预测值,在模型预测为负类的样本中,真正为负类的样本所占的比例。

(6)True positive rate(TPR,Recall)
召回率,真正类率,表示的是,模型预测为正类的样本的数量,占总的正类样本数量的比值。

(7)False positive rate(FPR),Fall-out
假阳率,表示的是模型预测为正类的样本中,占模型负类样本数量的比值。

一般情况下,假正类率越低,说明模型的效果越好。
(8)False negative rate(FNR),Miss rate
假负类率,缺失率,模型预测为负类的样本中,是正类的数量,占真实正类样本的比值。

2、ROC曲线
另一个用于度量分类中的非均衡的工具是ROC曲线(ROC curve),ROC代表接收者操作特征(receiver operating characteristic)
横坐标是伪正例的比例(假阳率=FP/(FP+TN)),而纵坐标是真正例的比例(真阳率=TP/(TP+FN))。ROC曲线给出的是当阈值变化时假阳率和真阳率的变化情况。左下角的点所对应的将所有样例判为反例的情况,而右上角的点对应的则是将所有样例判为正例的情况。虚线给出的是随机猜测的结果曲线。
ROC曲线不但可以用于比较分类器,还可以基于成本效益(cost-versus-benefit)分析来做出决策。
7.6 小结
AdaBoost算法优缺点
优点:泛化错误率低,易编码,可以应用在大部分分类器上,无参数调整。
缺点:对离群点敏感。
适用数据类型:数值型和标称型数据。
集成方法通过组合多个分类器的分类结果,获得了比简单的单分类器更好的分类结果。
多个分类器组合可能会进一步凸显出单分类器的不足,比如过拟合问题。
本章介绍的两种集成方法是bagging和boosting。在bagging中,是通过随机抽样的替换方式,得到了与原始数据集规模一样的数据集。而boosting在bagging的思路上更进了一步,它在数据集上顺序应用了多个不同的分类器。
boosting方法中最流行的一个称为AdaBoost的算法。AdaBoost以弱学习器作为基分类器,并且输入数据,使其通过权重向量进行加权。在第一次迭代当中,所有数据都等权重。但是在后续的迭代当中,前次迭代中分错的数据的权重会增大。这种针对错误的调节能力正是AdaBoost的长处。
非均衡分类问题是指在分类器训练时正例数目和反例数目不相等(相差很大)。该问题在错分正例和反例的代价不同时也存在。本章不仅考察了一种不同分类器的评价方法——ROC曲线,还介绍了正确率和召回率这两种在类别重要性不同时,度量分类器性能的指标。

















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









