






摘要
我们提出了一种联邦动态低秩训练(FeDLRT)方案,以减少客户端计算和通信成本。我们的方法基于动态低秩分裂方案,用于流形约束优化,创建网络权重的全局低秩基,使客户端能够在小系数矩阵上进行训练。这种全局低秩基使我们能够引入方差校正方案,并证明全局损失下降并收敛到一个稳定点。FeDLRT通过动态增加和截断低秩基来优化计算和通信资源的利用。值得注意的是,FeDLRT仅在每个客户端训练一个小的系数矩阵。
1 引言
联邦学习(FL)计算通常受到以下限制:
(i)客户端与服务器之间的通信带宽;部署各种压缩技术来解决,例如稀疏随机草图、子采样或允许部分或异步通信
(ii)每个客户端的计算和内存资源有限。通过稀疏训练和迁移学习来解决。
基于低秩、稀疏性和矩阵草图的方法被提出以提高FL的通信和计算效率。这些方法可以分为两类:
1)在客户端进行全秩训练并通过仅通信(a)低秩因子或(b)草图矩阵来减少通信成本的方法;
2)通过在客户端训练(a)低秩因子或(b)稀疏模式来同时减少通信和客户端计算成本的方法。
第一类方法仅压缩通信,但不会减少客户端的计算和内存成本;
第二类方法减少了客户端的计算和内存成本,但通常需要在服务器上重建完整的权重矩阵。
此外,客户端上多次优化步骤(本地迭代)通常会导致客户端漂移现象,其中收敛到局部最小值会阻碍全局收敛。已经提出了几种方法来缓解非压缩模型中的这一问题,但由于校正项通常与本地训练中的压缩(低秩或稀疏)表示不兼容,因此将这些客户端漂移缓解技术应用于第二类方法并非易事。
贡献:利用权重矩阵的低秩近似来动态跟随梯度流。
所提出的方法具有以下特点:
1)高效通信——仅传输低秩因子;
2)低客户端计算和内存占用——客户端仅优化一个小的系数矩阵,且FeDLRT的所有浮点运算均按矩阵维度线性缩放;
3)服务器端自动压缩——通过服务器端动态秩调整,在训练期间最小化内存和通信需求;
4)全局损失收敛保证——通过引入方差校正方案实现收敛到稳定点。这些特性均在基准问题上得到了验证。据作者所知,这是首个具备所有这些特性的低秩方法。
2 背景与问题陈述
在本工作中,我们考虑一个一般的联邦优化问题,即:
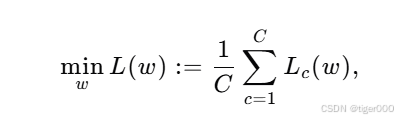
在这里,每个客户端使用梯度下降对局部损失函数,
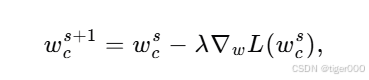

低秩神经网络训练:一系列最新工作提供了理论和实验证据,表明过参数化网络的层权重倾向于低秩(Arora et al., 2019; Bah et al., 2022; Galanti et al., 2022; Martin & Mahoney, 2018),并且去除小奇异值甚至可能增加模型性能,同时显著减少模型大小(Sharma et al., 2024; Schotthöfer et al., 2022),在非联邦场景中。这一有益特性激发了在训练后对神经网络进行低秩分解并进行微调的丰富方法(Sainath et al., 2013; Denton et al., 2014; Tjandra et al., 2017; Lebedev et al., 2015),训练分解后的网络并固定秩(Jaderberg et al., 2014; Wang et al., 2021; Khodak et al., 2021),在训练过程中动态调整秩(Schotthöfer et al., 2022; Zangrando et al., 2023),或者使用低秩适配器对基础模型进行微调(Hu et al., 2021; Dettmers et al., 2023; Zhao et al., 2024; Schotthöfer et al., 2024)。




























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









