







vulkan基础概念
opengl相对与vulkan不是一个级别的东西,opengl几十行代码就可以绘制一个简单的物体,而vulkan需要几百行才能绘制,所以vulkan的学习曲线比较陡峭,本人经过也经过一个很长的时间的断断续续学习对vulkan有了一些认识,在这里做一下笔记,错误请指出。
首先针对vulkan的上下文进行讲解,vulkan对于底层的整个管线流程做了开放,并且给出了很多逻辑上的对外接口,基本上下文包括Instance、physicalDevice、logicDevice、Queue、surface、swapchain、Image、ImageView、pipeline、CommandPool、CommandBuffer、RenderPass、PipelineVertexInputState、push contants、Layout、Fence、semaphore。
1. Instance
Instance存在的意义,记得很早看过dx12的api,都有类似的功能,Instance就好比一个总管,可以设置一写全局的东西进去,如验证层和扩展(物理设备也有自己单独的验证层和扩展),可以枚举很多物理设备,是操作系统层面管理所有显卡设备的一个逻辑功能,可以枚举出所有的显卡,电脑上一般都由集成显卡和独立显卡,所以在选择显卡的时候Instance会枚举出所有的显卡,然后拿到每个显卡的功能,看看哪些显卡满足我们的使用要求就使用哪个显卡。
2. physicDevice
physicDevice是计算机上显卡硬件的代理(类似显卡驱动的东西),显卡支持的功能就是真正能用的功能,所以很多的信息需要从physicDevice去查询(例如队列簇等信息)。
3.logicDevice
logicDevice存在的意义,本人认为是选择了physicalDevice中的某些功能进行封装,而不是直接代理physicalDevice,比如对于显卡有很多的命令队列簇(Queue Family 0,Queue Family 1,Queue Family 2),而每个Queue Family中又包含了不同的命令队列。而在创建logicDevice的时候会设置这个logicDevice使用那些命令队列簇,不设置的不会用到,就好比显卡设备有很多的功能,而我们的渲染器只是需要一部分功能,那就把一部分功能拿出来打包成一个logicDevice去使用就好了。
4. Queue
Queue,既然logicDevice已经封装了队列信息,那么就可以直接从logicDevice中取出Queue,方便后续的命令缓冲传入Queue中来绘制命令(Graphic)、计算命令(Compute)、传输数据到GPU(transfer),当然命令队列是一个队列,与cpu共享访问权限,就会涉及到冲突问题,就要加锁,就会出现信号量、屏障等。
5.surface
surface是屏幕格式的一个接口,通过surface可以知道显示器图像的格式。
6.Swapchain
Swapchain,交换链不属于显卡的功能,是用于显示的,在显卡与屏幕之间需要一些协商的工作,就是交换链的功能做(不显示图像就不用交换链),交换链根据surface的一些格式(大小、颜色格式【颜色空间】)跟显卡进行协商,同时交换链也设定创建多少张这样的图像,通常用于创建双缓冲、三缓冲。还有一个重要的应用就是交换链连接图像渲染队列和显示队列,当渲染一张图像时,先从交换链中取出一张图像作为当作帧缓冲附件进行渲染,渲染完成后将这个图像传输到显示队列中,用来显示图像到屏幕上。
7.Image
Image,图像是交换链中创建的,就需要在交换链中读取出来。
8.ImageView
ImageView,Image是一个内存块(或者一种不为我们知道的格式存在),如果我们想读取这块内存,就要对这个Image进行格式化,ImageView就是一个格式化的过程。
9.pipeline
pipeline,这是显卡对图元的一次渲染流程,包含了从顶点装配、顶点着色器、视口设置、光栅化、像素着色器、深度模板比较、混合等各个阶段的参数设置,这个管线基本上是一个整体,不能中途更改(除了线宽、视口大小),也就是说一个着色器glsl代码对应一个pipeline。对于layout的设置主要是针对Uniform、pushContant相关布局的设置。而对于RenderPass的设置,则是每个pipeline必然都有输出,针对GraphicPepeline的管线,它的输出都是FrameBuffer(ColorAttachment、DepthAttachment),而renderPass中会设置这些附件的格式(布局),方便vulkan进行优化。
10.CommandPool
CommandPool,就是一个命令池,和很多的池化概念一样,池化就是需要的时候在池中取出,不用的时候放到池子中去,避免创建、销毁过程中的性能损失。
11.CommandBuffer
CommandBuffer命令,通常情况下命令与swapchain中缓冲的个数相同(双缓冲或者三缓冲),因为如果是三缓冲,同一个帧(同一幅画面)肯定在同一个GraphicQueue中被调度渲染,其他GraphicQueue肯定是闲置的,所以在开始渲染一帧时首先看看swapchain中哪个缓冲是闲置的,这个闲置的索引也对应了哪个GraphicQueue是闲置的,就将CommandBuffer添加到这个闲置的GraphicQueue中,一帧中有多个渲染实体(一个实体对应一组vertexBuffer、Uniform、pipeline)时,需要使用这个命令一次封装一个实体,实体被一个一个的提交到命令队列中。
12.RenderPass
RenderPass,这是一个对渲染过程中帧缓冲的描述,或者是对帧缓冲的布局进行说明,为什么在pipeline中需要使用这个RenderPass呢,很多资料中给出的解释是方便vulkan在pipeline的fragmentshader输出图象时进行优化,给出这样的解释让我很是不解(就好比解释不了就推给神或者上帝),同时vulkan的设计初衷是让程序掌握很多底层的细节,这个细节处理的不好。renderpass的创建信息是这样的,renderpass中包含了一组对各个帧附件的描述,这个原理我还没有完全弄明白,留待后面修改。

13.PipelineVertexInputState
PipelineVertexInputState 这个布局对应了shader中顶点属性的布局,与opengl中顶点属性布局的功能对应。
14.push contants
push contants 直接将常量数据通过命令缓冲区传递给着色器,而不是通过内存传递,
常量的限制是只能在命令录制中传递,同时又大小的限制(vulkan规定128字节),这里最重要的点是常量的对齐,vec3内存是与vec4的内存一样对齐的是16字节对齐。
15.Layout
Layout是数据的布局,这个布局主要是针对推送常量和uniform数据的内存格式使用的。
16.Fence
Fence,我们知道cpu和gpu是两个不同的设备,不同的设备在执行的时候对同一个数据的的处理就会出现同步问题,就好比两个不同的线程,通常的情况下数据都会先调如内存,然后从内存调用寄存器,如果两个线程都将同一份数据进行了这样的操作,并同时覆盖了内存中的数据,这就出现了数据冲突,通常我们会使用互斥对象、临界区等一些类似原子操作手段进行处理,而vulkan中使用了Fence进行处理,Fence有如下状态:
- 未发出信号(unsignaled):表示关联的操作还未完成。
- 已发出信号(signaled):表示关联的操作已经完成。
// 创建一个fence
VkFenceCreateInfo fenceCreateInfo{};
fenceCreateInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
fenceCreateInfo.flags = VK_FENCE_CREATE_SIGNALED_BIT; // 初始状态为已发出信号
VkFence fence;
vkCreateFence(device, &fenceCreateInfo, nullptr, &fence);
// 重置fence状态
vkResetFences(device, 1, &fence);
// 提交命令队列并关联fence
VkSubmitInfo submitInfo{};
submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &commandBuffer;
submitInfo.signalSemaphoreCount = 0;
submitInfo.pSignalSemaphores = nullptr;
submitInfo.waitSemaphoreCount = 0;
submitInfo.pWaitSemaphores = nullptr;
submitInfo.pWaitDstStageMask = nullptr;
submitInfo.fence = fence;
vkQueueSubmit(queue, 1, &submitInfo, VK_NULL_HANDLE);
// CPU等待fence发出信号
vkWaitForFences(device, 1, &fence, VK_TRUE, UINT64_MAX);
上述代码中vkCreateFence创建的时候是有信号的,提交队列命令之前首先调用vkResetFences,将Fence置为无信号,vkQueueSubmit内部处理完成之后会将Fence置为有信号,但是调用vkQueueSubmit之后cpu不会停止,会继续执行,而在cpu执行到vkWaitForFences时检查到Fence没有信号就会等待(阻塞),直到GPU处理完成,Vulkan将Fence置为有信号后,CPU才继续执行。
17、Semaphore
Fence是为了保护cpu中的资源,使得cpu中的资源与gpu中的资源保持一致,然而在gpu的渲染过程中,在gpu的内部涉及到多个队列同时使用某些资源的情况所以要使用信号量来控制资源,例如:渲染过程中要使用image作为渲染目标,那么在开始渲染之前要保证这张图不在被其他队列使用(显示队列),这就要使用Semaphore来避免抢夺image资源,其次渲染目标在渲染队列渲染完成后才能放到显示队列中,这也需要Semaphore进行同步操作。
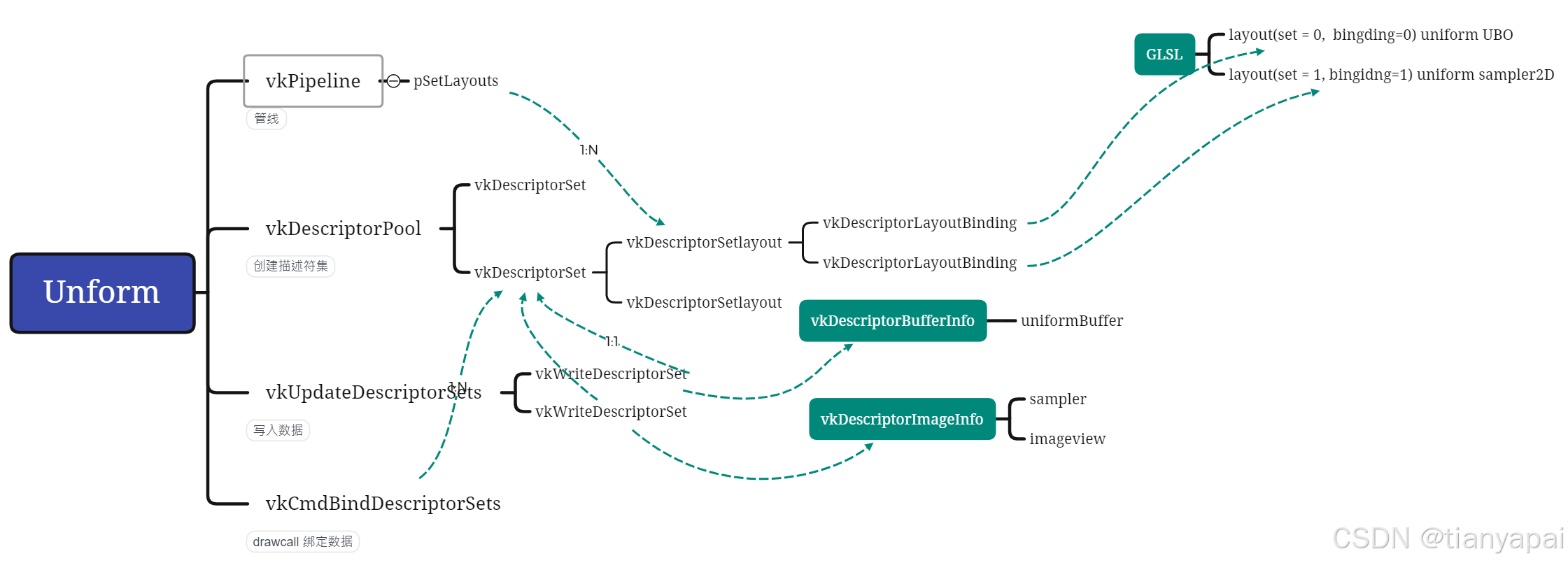
18、DescriptorSet
描述符集用来处理Uniform相关的数据,相比于opengl的API,一次只能传递一个uniform数据不同,vulkan主打的是一个Command命令,是一个批次的提交,使用描述符集set,就是将uniform数据分组打包,例如:视图投影矩阵,不经常变化的可以作为一个set;模型矩阵每个对象都不同(同时经常变化,位置移动)作为一个set;材质中的Image每个模型不同,但是不会变化作为一个set。
vulkan中的池化概念很常见,描述符集需要频繁处理资源,所以进行了池化;而pipeline中需要使用setlayout将内存布局与shader做到一一对应;再就是更新uniform缓冲数据到描述符集中;最后就是在渲染的时候将描述符集连同数据传递命令中。
19.ComputeShader
在vulkan中使用computer进行并行计算,可以类比CPU上的thread计算,每个computershader的main函数就是一个线程执行函数。同时GPU上的并行计算是完全并行的(除非任务超过了计算核心数量).
计算着色器有其独特的特性,需要从两方面分析:
1、从计算着色器代码看:
layout (local_size_x = 10, local_size_y = 20, local_size_z = 30) in;上述代码是每个计算着色器中都需要写的,代表了调用一次计算着色器就会同时启动(local_size_x * local_size_y * local_size_z)个核心(或者线程),为什么是三维的呢,这主要是应对图形学这一技术,我们可以想象大部分的图形学是计算三维空间中的物体,更具体点就是,三维纹理(体积纹理),如果我们处理体积类的模型是不是就很方便了。
那如果是二维纹理,就可以使用下面这个过程,第三个维度是1就可以了。
layout (local_size_x = 10, local_size_y = 20, local_size_z = 1) in;那如果是一维纹理,就可以使用下面这个过程,第二、三个维度是1就可以了。
layout (local_size_x = 10, local_size_y = 1, local_size_z = 1) in;2、从程序调用方面:
vkCmdDispatch(compute.commandBuffer, storageImage.width / local_size_x, storageImage.height / local_size_y, storageImage.depth / local_size_z);将图像分成多个调用批次,每个批次会调用所有的(local_size_x * local_size_y * local_size_z),也就是会调用(storageImage.width * storageImage.height * storageImage.depth )这些次。
最后就是同步问题,计算着色器计算的结果在其他着色器使用时会出现竞争问题,处理方式就是使用信号量semaphore和fence
20、VkSubmitInfo
这个接口中有几个特别注意的地方(信号量同步)
typedef struct VkSubmitInfo {
VkStructureType sType;
const void* pNext;
uint32_t waitSemaphoreCount;
const VkSemaphore* pWaitSemaphores;
const VkPipelineStageFlags* pWaitDstStageMask;
uint32_t commandBufferCount;
const VkCommandBuffer* pCommandBuffers;
uint32_t signalSemaphoreCount;
const VkSemaphore* pSignalSemaphores;
} VkSubmitInfo;直观理解这个结构的功能就是,如果这是一个将命令提交到队列的接口,但是提交的信息中包含了在cpu中无法控制,但是在gpu中必须指定的一个流程,在执行队列命令之前必须等待某些过程已经完成,就是通过设置信号量这种原子操作来完成,(我们从cpu将命令传入到gpu的命令队列之后,这是一个异步操作,我们无法知道什么时候命令执行,也不知到什么时候命令执行完成了,但是可以通过信号量来指导某些过程)
下面是一个实例,
VkSubmitInfo submitInfo{};
submitInfo.pWaitDstStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT; // 在这个阶段等待前面的信号量完成
submitInfo.waitSemaphoreCount = 1; // 等待几个信号量
submitInfo.pWaitSemaphores = &semaphores.presentComplete; // 等待的信号量
submitInfo.signalSemaphoreCount = 1; // 触发几个信号量
submitInfo.pSignalSemaphores = &semaphores.renderComplete; // 触发的信号量pWaitDstStageMask : 代表这个提交的命令需要在什么时候进行同步(阻塞),设置设置了颜色附件输出,也就是我们的渲染管线pipeline执行玩成了,但是最终要出到帧缓冲的时候,要检查某些条件(信号量是否有信号),如果条件还不成熟就阻塞,如果条件成熟就继续执行,执行完成之后还要触发某些信号,用来通知后续的工作执行。
waitSemaphoreCount :代表pWaitDstStageMask要等待几个信号量。
pWaitSemaphores :代表pWaitDstStageMask等待那些信号量。
signalSemaphoreCount :当pWaitDstStageMask执行完成后需要触发几个信号量。
pSignalSemaphores:当 pWaitDstStageMask执行完成后触发那些信号量。
21、内存申请的一般过程
对于缓冲区(Buffer、Image)这类缓冲区的一般申请过程如下(image举例):
1、根据image的必要信息创建image,必要信息例如:图像大小、每个像素的格式、重采样次数等这些就能确定需要多大的内存;
2、根据创建image,查询需要多大的内存等信息;
3、创建image对应的内存;
4、将image绑定到内存。
VkImageCreateInfo imageCI{};
imageCI.sType = VK_STRUCTURE_TYPE_IMAGE_CREATE_INFO;
imageCI.imageType = VK_IMAGE_TYPE_2D; // 2D图形
imageCI.format = depthFormat; // 深度的格式,在交换链中已经获取了
imageCI.extent = { width, height, 1 }; // 图像的宽度和高度
imageCI.mipLevels = 1; // 只有一个mipmap级别
imageCI.arrayLayers = 1; // 只有一个层
imageCI.samples = VK_SAMPLE_COUNT_1_BIT; // 单重采样
imageCI.tiling = VK_IMAGE_TILING_OPTIMAL; // 图像分tiling进行优化
imageCI.usage = VK_IMAGE_USAGE_DEPTH_STENCIL_ATTACHMENT_BIT; // 用作深度模板附件
// 创建图像
VK_CHECK_RESULT(vkCreateImage(device, &imageCI, nullptr, &depthStencil.image));
// 根据图像查询内存需求
VkMemoryRequirements memReqs{};
vkGetImageMemoryRequirements(device, depthStencil.image, &memReqs);
VkMemoryAllocateInfo memAllloc{};
memAllloc.sType = VK_STRUCTURE_TYPE_MEMORY_ALLOCATE_INFO;
memAllloc.allocationSize = memReqs.size;
// VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT申请的是GPU内存
memAllloc.memoryTypeIndex = vulkanDevice->getMemoryType(memReqs.memoryTypeBits, VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT);
// 申请内存
VK_CHECK_RESULT(vkAllocateMemory(device, &memAllloc, nullptr, &depthStencil.memory));
// 绑定内存
VK_CHECK_RESULT(vkBindImageMemory(device, depthStencil.image, depthStencil.memory, 0));22、pool相关
命令缓冲池、描述符池

















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









