







给定一个模式串 S,以及一个模板串 P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模板串 P 在模式串 S 中多次作为子串出现。
求出模板串 P 在模式串 S 中所有出现的位置的起始下标。
输入格式
第一行输入整数 N,表示字符串 P 的长度。
第二行输入字符串 P。
第三行输入整数 M,表示字符串 S 的长度。
第四行输入字符串 S。
输出格式
共一行,输出所有出现位置的起始下标(下标从 0 开始计数),整数之间用空格隔开。
数据范围
1≤N≤105
1≤M≤106
输入样例:
3
aba
5
ababa
输出样例:
0 2
暴力:时间复杂度为O(n)
for(int i = 1; i <= n; i++)
{
bool falg = true;
int t=i;
for(int j = 1; j <= m&&t<=n;j++)//每次都要重头
{
if(s[t++] != p[j]) {
flag = false;
break;
}
}
}
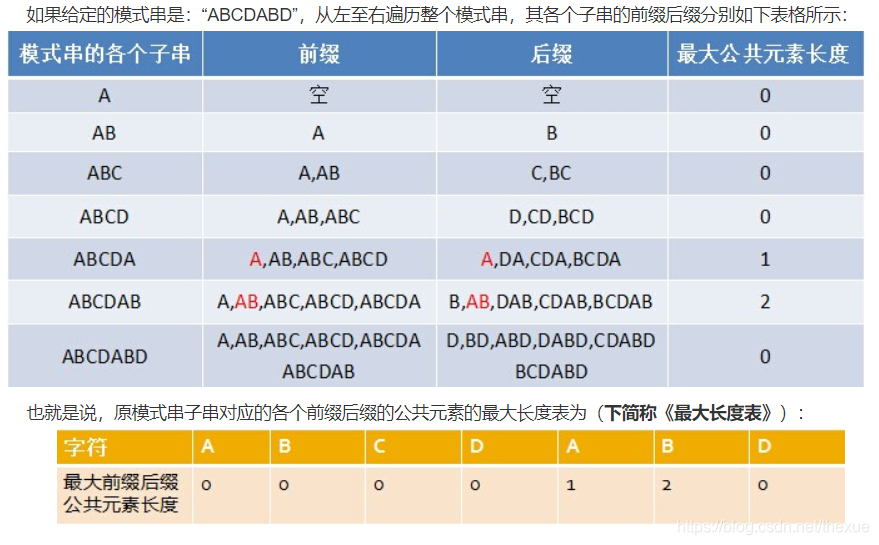
kmp 算法主要利用前缀后缀特点优化暴力历遍过程时间复杂度为O(n);
第一步是寻找前缀与后缀匹配的最大长度
代码实现:
for(int i=2,j=0;i<=n;i++)
{
while(j&&s[i]!=s[j+1])j=ne[j];//
if(s[i]==s[j+1])j++;
ne[i]=j;
}
前两个位置默认为 0;
j为0说明无法继续前移,那么说明这点不存在相同的前缀后缀
i++寻找下个点
如果发现 s[i]==s[j+1]则发现一个前缀 等于后缀
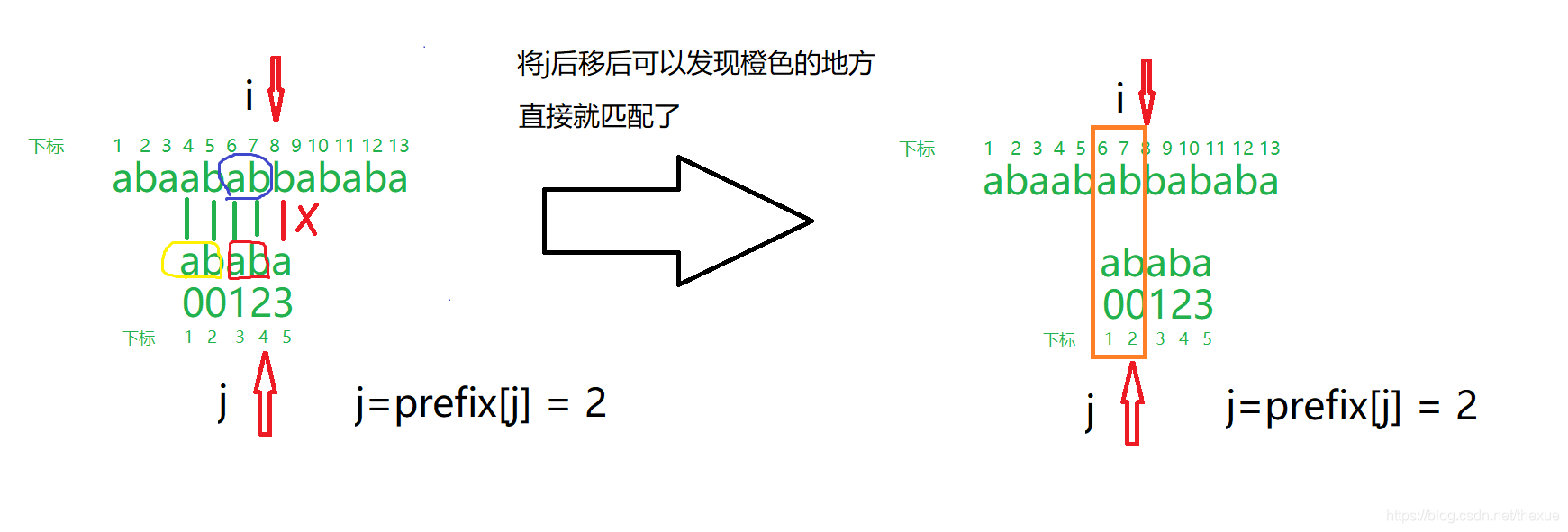
下一步在字符串中历遍寻找,利用前缀后缀数组优化寻找过程
#include<iostream>
#include<stdio.h>
using namespace std;
int n,m,ne[100005];
char str[1000005],s[100005];
int main()
{
cin>>n>>s+1>>m>>str+1;
for(int i=2,j=0;i<=n;i++)
{
while(j&&s[i]!=s[j+1])j=ne[j];
if(s[i]==s[j+1])j++;
ne[i]=j;
}
for(int i=1,j=0;i<=m;i++)
{ while (j && str[i] != s[j + 1])j = ne[j];//每次从后缀回到相等的前缀位置;
if (str[i] == s[j + 1])j++;
if (j == n)
{
printf("%d ", i - n);
j = ne[j];
}
}
return 0;
}

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









