



HAP - SPMD DNN Training on Heterogeneous GPU Clusters with Automated Program Synthesis(EuroSys‘24)
摘要
HAP是一个自动化系统,旨在加速在异构集群上的SPMD(Single-Program-Multiple-Data)类型模型训练。通过优化张量分片策略、异构设备间的分片比例和张量通信方法,实现分布式训练的优化。HAP将模型分割问题表述为自动化程序合成问题(Automated Program Synthesis),通过A*搜索算法在分布式指令集上生成分布式程序,同时解决最优张量分片比例的问题,进而按照SPMD计算范式并行执行。
问题挑战
解决在异构集群上训练大模型时,如何有效利用不同GPU设备及网络连接等资源。
详细解决方案
执行流程
HAP整体执行流程如下图所示,HAP的用户API类似于PyTorch内置的DDP模块:用户使用单设备PyTorch模型和设备规范的Python字典调用hap.HAP函数,该函数返回可以在集群上使用PyTorch的torch.distributed模块运行的分布式模型_。_
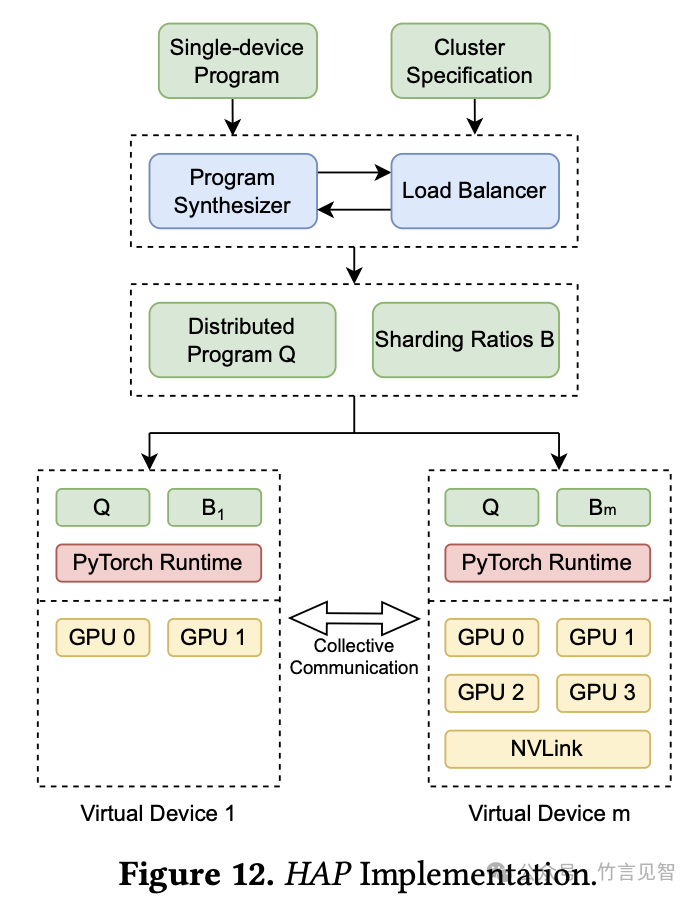
具体流程如下:
-
输入数据包括:单设备程序和集群参数明细-包括设备如GPU的FLOPS、通信原语的延迟和带宽等
-
将上述数据输入到CPU上的程序合成器和负载均衡器,以确定最优的分布式程序Q和分片比例B。文中使用CBC解决分片比例优化问题
-
分布式程序Q(所有GPU上市一样的)**:是根据单设备上的原始程序自动程序合成的,目的是按照SPMD计算范式在多设备上实现并行处理,**同时保持与原始单设备程序相同的语义。这种方法特别适用于那些结构相对简单、允许进行有效语义分析的程序。大模型训练中,Tensor程序因为非递归且无副作用刚好满足条件。
-
Sharding Ratio B:是在分布式训练中,如何在不同GPU之间分配Tensor的Shards。大型的张量可能无法在单个设备上完全存储,因此需要将这些张量分割成更小的分片,并分布到多个设备上。B就是用来描述这种分布的比例或大小。包含两种分片比例方法:CP(按计算能力设置分片比例)和EV(均匀分片)。
-
模型训练开始时,将Q、B广播给所有工作节点(设备)并执行,每个工作节点首先使用相同的种子在CPU上初始化原始的单设备模型。对于Q中的每个Parameter-Shard(d)操作,第j个工作节点沿着其d维将相应的参数分片,并只保留对应于
 部分的切片,分片后的参数加载到GPU上训练。
部分的切片,分片后的参数加载到GPU上训练。 -
每次训练迭代中,工作节点根据其分片比例各自加载一小批输入数据。然后它们执行QQ并在执行集体通信时相互同步。运行QQ后每个工作节点将梯度应用到自己的参数分片上。
-
每个通信操作抽象为Hoare三元组,{ 𝑝𝑟𝑒𝑐𝑜𝑛𝑑𝑖𝑡𝑖𝑜𝑛 } 𝑖𝑛𝑠𝑡𝑟𝑢𝑐𝑡𝑖𝑜𝑛 { 𝑝𝑜𝑠𝑡𝑐𝑜𝑛𝑑𝑖𝑡𝑖𝑜𝑛 }
-
首先使用Gather或Reduce将所有GPU上的张量聚合到GPU 0;然后GPU 0使用聚合的张量参与全局集体通信;然后GPU 0将结果使用Scatter或Broadcast广播到机器中的其他GPU。
整体方案主要由以下几部分组成。
自动化程序合成
HAP将模型分割问题转化为程序合成问题,利用分布式指令集从头开始生成分布式程序,该程序在语义上类似于为单设备设计的程序。即实现SPMD计算范式。


负载均衡
利用负载均衡分配计算通信任务,确保所有设备高效工作。
-
将负载均衡问题转换为线性规划问题:目标是最小化整个训练过程的迭代时间,同时考虑到不同设备的计算速度和内存容量。
-
模型分割:在更复杂的情况下,DNN模型可能包含许多层,每层的计算和通信比例可能不同。论文中提出了将模型分割成多个段(segments),并为每个段独立确定分片比例的方法。
-
All-To-All通信:在模型分割的基础上,为了协调不同段之间的张量分片比例,HAP在段的边界插入All-To-All通信操作和同步点,以确保数据在设备之间的正确分配。
-
优化算法:论文中使用了迭代优化方法来交替优化分布式程序和分片比例。通过这种方式,系统可以逐步逼近最优的负载均衡解决方案。
A搜索算法
HAP使用A*搜索算法来寻找最优的分布式程序,该算法结合了动态规划的思想,通过循环搜索和成本预估来加速搜索过程。其中成本预估指的是HAP提出的一种基于仿真的方法,将分布式程序的执行分成多个阶段,并计算每个阶段的通信和计算时间

通信优化
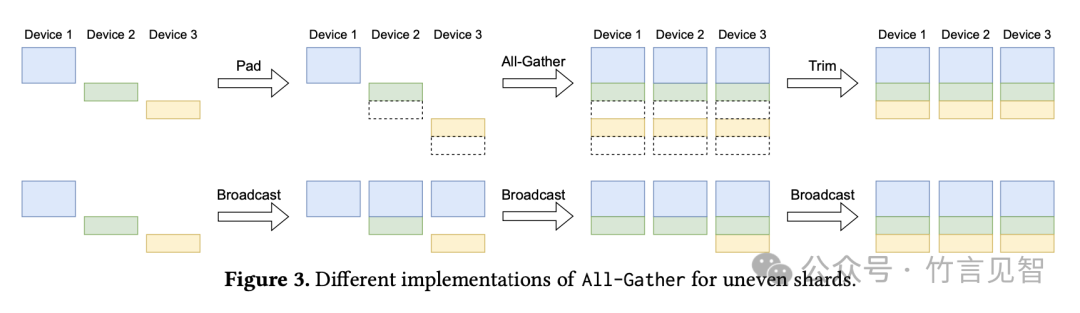
- 异构集群中的All-Gather实现:在异构集群中,根据分片比例的不同,可能需要不同的All-Gather实现方式。论文中提出了两种方法:填充(Padded All-Gather)和分组广播(Grouped Broadcast),并在搜索过程中自动选择性能更好的方法。
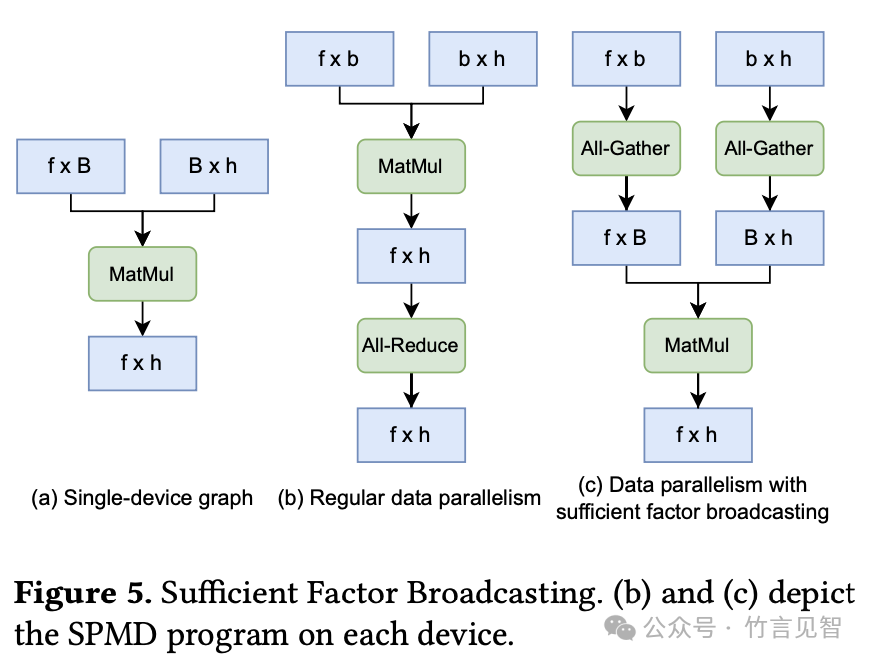
- Sufficient Factor Broadcasting (SFB):SFB利用梯度张量的低秩结构来减少通信量。在搜索过程中,通过添加特定的规则来探索SFB的应用,以优化通信。

搜索时间优化
-
融合Hoare三元组:将具有空前提条件的Hoare三元组与其消费者融合,减少搜索过程中对这些指令位置的枚举。
-
避免重复通信:不允许对同一参考张量进行多次通信,减少不必要的通信指令。
-
移除冗余属性:从部分程序中移除不会用于任何指令前提条件的属性,增加可以剪枝的程序数量。
-
启发式函数优化:使用最小化执行时间作为启发式函数,确保不会高估未来成本。
实验效果
在代表性工作负载的广泛实验中,HAP在异构集群上实现了高达2.41倍的加速。
Optimal Resource Efficiency with Fairness in Heterogeneous GPU Clusters(Middleware’24)
摘要
OEF(Optimal Resource Efficiency with Fairness)是一个新的资源分配框架,专为异构GPU集群中的深度学习训练设计,以实现最优的资源效率并确保用户的多样性公平性 。OEF通过将资源效率和公平性整合到全局优化框架中,能够在合作和非合作环境中为用户提供最大化的整体效率和各种公平性保证。
通过在包含24个异构GPU设备的集群中实现OEF原型系统并进行大规模实验,结果表明,OEF能够将整体训练吞吐量提高最多32%,同时与现有最先进的异构感知调度器相比,提高了公平性。
问题挑战
-
现有的深度学习调度器在异构GPU集群中提供有限的公平性属性和次优的训练吞吐量。
-
设计挑战源于效率和公平性属性之间的固有冲突。
-
需要一个新的调度策略,既能提供高效率,又能在资源分配中保持公平性。
详细解决方案
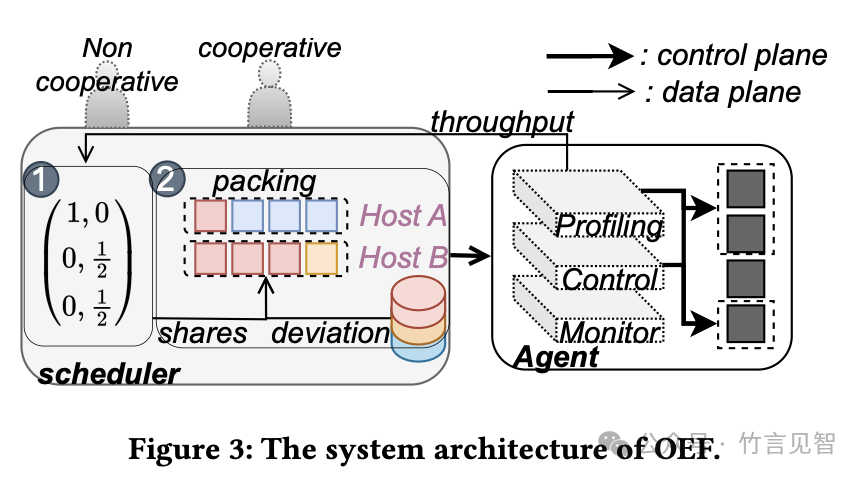
OEF资源分配框架如上图所示,旨在解决异构GPU集群中的资源效率与公平性之间的冲突。它通过以下关键组件实现这一目标:
-
全局优化框架:整合资源效率和公平性,以便于同时考虑这两方面的需求。
-
效率与公平性的量化:明确定义和量化效率与公平性,便于在优化问题中进行评估和平衡。主要的speedup矩阵W和allocation矩阵X,分别表示:
-
W训练任务在不同GPU设备上的执行速率与在最慢GPU设备上执行速率的比值。它反映了不同GPU设备处理特定训练任务的性能差异
-
X用于记录每个用户分配到的每种类型GPU数量的矩阵。它定义了资源分配的具体方案。
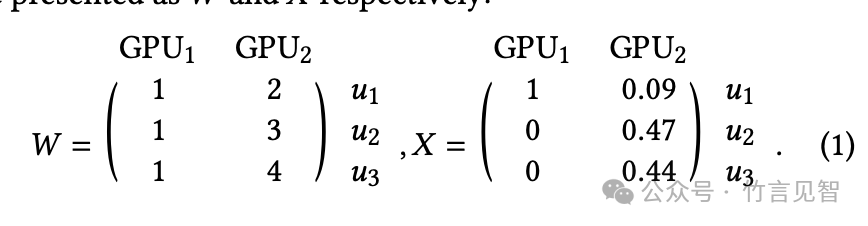
非合作环境解决方案
在非合作环境中,OEF的设计重点在于实现策略证明性(Strategy-Proofness, SP),确保用户不会通过虚报其作业的加速比来获得不当利益:
-
效率均等分配:设计一个优化问题,确保所有用户获得相同的(标准化)吞吐量,从而实现策略证明性。
-
优化问题:构建一个线性优化模型,目标是最大化所有用户的总吞吐量,同时约束条件确保用户间的效率平等。

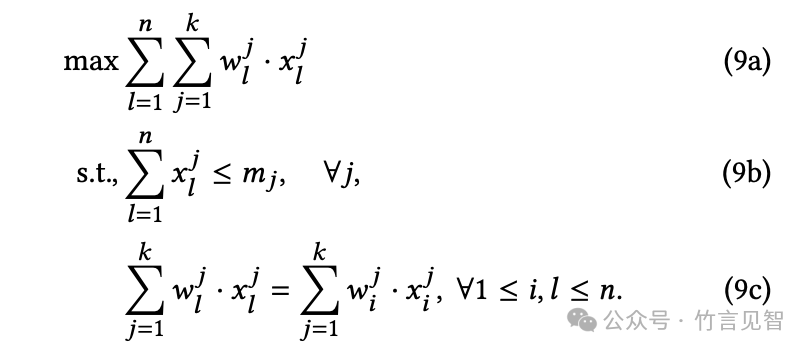
合作环境解决方案
在合作环境中,OEF专注于实现无嫉妒(Envy-Freeness, EF)和共享激励(Sharing-Incentive, SI):
-
优化问题调整:调整优化问题以包含无嫉妒约束,确保每个用户对其分配的资源满意,不会羡慕其他用户的资源分配。
-
共享激励的实现:通过优化问题的设计,当追求无嫉妒时,共享激励自然得到满足,因为最大化整体资源效率会促使资源的公平分配。
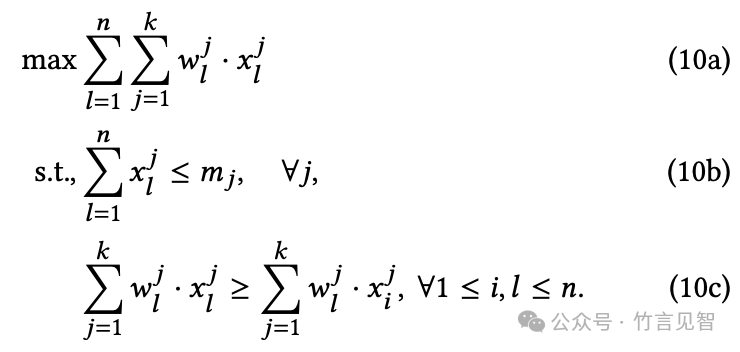
权重OEF
为了适应不同用户优先级的情况,OEF引入权重机制:
-
用户权重分配:为每个用户分配权重,反映其重要性或资源需求。
-
速度向量复制:通过复制速度向量多次来适应权重,确保权重较高的用户获得更多的资源。
多类型作业支持
OEF支持用户同时训练不同类型的DL作业:
-
虚拟用户概念:将每种作业类型视为单独的虚拟用户,独立处理。
-
权重分配:将用户的权重平均分配给其所有作业类型,确保公平性。
放置优化
OEF的放置优化策略旨在将分数分配转换为整数份额,并考虑长期效率和公平性:
-
四舍五入策略:开发一种策略,将每个用户分配的分数转换为整数份额,同时跟踪和调整偏差,以确保长期公平性。
-
网络争用缓解:优化放置方案以减少网络争用,优先考虑分配更多资源给具有更多工作进程的作业。
拖沓效应缓解
OEF通过以下方式减轻拖沓效应:
-
GPU类型限制:确保为每个用户分配的GPU类型相邻,减少跨类型放置。
-
极端点定理应用:利用定理限制分配矩阵中的非零元素数量,减少拖沓效应的影响。
实验效果
实验结果表明,OEF在非合作和合作环境中都能成功实现所需的公平属性,并且在整体训练吞吐量方面优于现有技术。与现有的异构感知调度器相比,OEF可以将整体训练吞吐量提高高达32%,并将整体作业完成时间减少高达19%。
AI大模型应用怎么学?
这年头AI技术跑得比高铁还快,“早学会AI的碾压同行,晚入门的还能喝口汤,完全不懂的等着被卷成渣”!技术代差带来的生存压力从未如此真实。
兄弟们如果想入门AI大模型应用,没必要到处扒拉零碎教程,我整了套干货大礼包:从入门到精通的思维导图、超详细的实战手册,还有模块化的视频教程!现在无偿分享。

1.学习思维导图
AI大模型应用所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

2.从入门到精通全套视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。

3.技术文档和电子书
整理了行业内PDF书籍、行业报告、文档,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

朋友们如果有需要全套资料包,可以点下面卡片获取,无偿分享!

















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









