




基于此,本篇继续带领大家搭建一个基于本地知识库检索的问答系统。
有同学说 Coze 不也可以实现同样功能么?
是的,不过在 Coze 上,你需要把知识库文件文件上传到 Coze 的服务器。如果对数据安全有要求,那么搭建本地私有的知识库就更有必要了。
而且,就目前的体验而言,相比下面介绍的 FastGPT,Coze 的知识库检索略逊色一些。
FastGPT,给 GPT 插上本地私有知识库的翅膀,让它可以利用你的领域知识回答问题。
有同学问:和 dify 有什么区别?
相比 dify,FastGPT 在知识库召回上更优,而 dify 产品功能更为丰富,适合 demo 搭建。
传送门:https://github.com/labring/FastGPT
1. FastGPT 部署
前两篇,我们分别搞了一台本地 Linux 虚拟机和一台云服务器:
- Windows上安装Linux子系统,搞台虚拟机玩玩
- 玩转云服务:手把手带你薅一台腾讯云服务器,公网 IP。
接下来,就把 OneAPI 部署在这台云服务器上,如果你用本地 Linux 虚拟机也是没问题的。
因为本项目还依赖其他服务,所以我们采用 docker-compose 的方式来进行部署,简单几步就能搞定,大大降低小白的部署门槛。
不了解 docker 的小伙伴可以看这里:【保姆级教程】Linux系统如何玩转Docker
1.1 下载配置文件
打开一个终端:
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
curl -o docker-compose.yml https://raw.githubusercontent.com/labring/FastGPT/main/files/docker/docker-compose-pgvector.yml
从 docker-compose.yml 中可以看出:FastGPT 用到的大模型需要兼容 OpenAPI 格式。
没关系,因为上一篇我们已经完成了 OneAPI + MySQL 的部署,只需要把 OneAPI 的 base_url 和 API Key 填入 yml 文件如下位置:

如果没有部署OneAPI,也没关系,这个 docker-compose.yml 文件包含了 OneAPI 的部署,可以先进入下面的1.3 服务启动。
等 OneAPI 启动后,参考:oneapi,在 OneAPI 中手动复制令牌,填到上面 CHAT_API_KEY 的位置。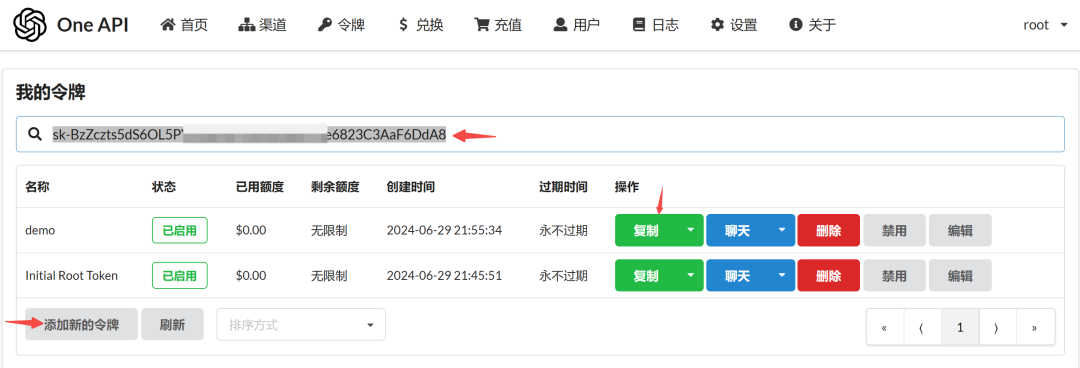
填写完成后,记得重启 FastGPT 容器:docker restart fastapi。
1.2 模型配置
知识库的构建,需要使用向量模型将一段文本转换成向量。在 OneAPI 中我们加入的 GLM 渠道,是支持向量模型的。
为此,需要在 config.json 中将用到的对话模型和向量模型加入进来:
- 对话模型:采用 “glm-4”

-
向量模型:采用 “embedding-2”
“vectorModels”: [
{
“model”: “embedding-2”, // 模型名(与OneAPI对应)
“name”: “Embedding-1”, // 模型展示名
“avatar”: “/imgs/model/openai.svg”, // logo
“charsPointsPrice”: 0, // n积分/1k token
“defaultToken”: 700, // 默认文本分割时候的 token
“maxToken”: 3000, // 最大 token
“weight”: 100, // 优先训练权重
“defaultConfig”: {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
“dbConfig”: {}, // 存储时的额外参数(非对称向量模型时候需要用到)
“queryConfig”: {} // 参训时的额外参数
}
]
1.3 服务启动
如果服务器是国内的 IP,建议将 docker-compose.yml 文件中的镜像都改为阿里云的镜像。
配置好 docker-compose.yml 文件后,采取如下命令一键启动:
sudo docker-compose up -d
看到下图,说明正在拉取镜像:
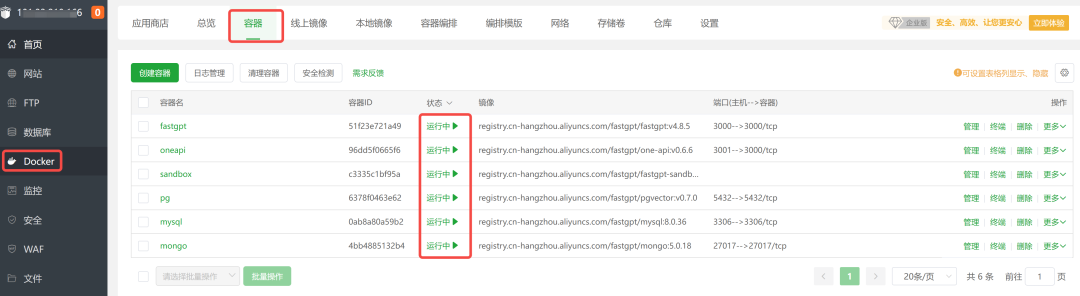
打开宝塔面板,可以看到服务已经在运行中:
1.4 启动失败解决
如果某个容器启动失败,可以采用如下命令重启:
docker restart oneapi
docker restart fastapi
如果还是不行,把 docker 重启试试:
sudo systemctl restart docker
可能有的小伙伴之前在服务器上安装过 MySQL,3306端口被占用,导致这里的 MySQL 容器启动失败。因此,可以终止已安装的 mysql 服务,再重新执行 sudo docker-compose up -d。

2. FastGPT 应用
2.1 登录 FastGPT
在 docker-compose.yml 配置文件中找到 FastGPT 的端口号:3000。
浏览器中打开:http://IP:Port,例如:http://101.33.210.xxx:3000/。
如果上述地址打不开,需要到服务器中把 3000/3001/3306 端口的防火墙打开。如果你用的是腾讯云服务器,具体操作见:玩转云服务:手把手带你薅一台腾讯云服务器。
防火墙打开后,上述地址就可以访问了,初始账号名 root,密码 1234:
2.2 新建知识库
我们需要先把知识库准备好,便于后续调用。
左侧菜单栏选择知识库,右上角新建: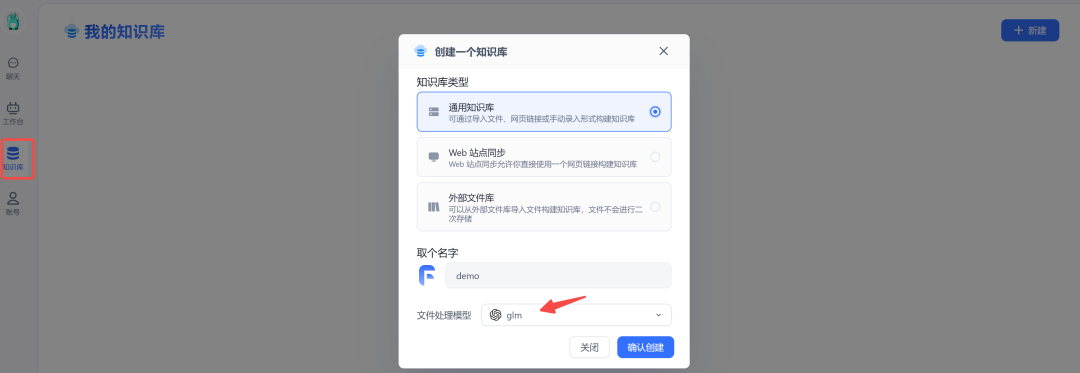
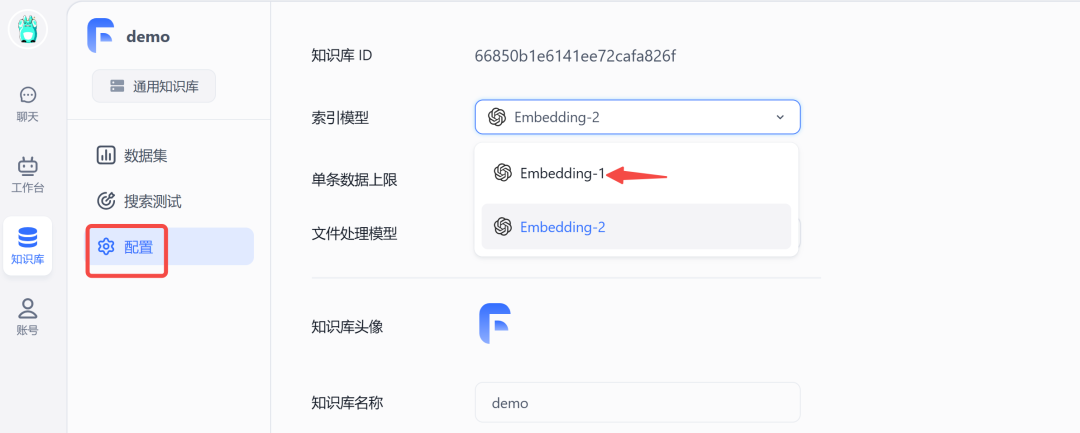
进来后,点击下面的配置,将索引模型改为 Embedding-1 ,因为这个才是我们在1.2 模型配置部分加入的向量模型,而 Embedding-2 对应的是默认 GPT 的 "text-embedding-ada-002"模型。配置修改完成,记得保存。
然后上传文件,这里为了跑通测试流程,我选择了文本格式,并简单填写了一些内容:

等待处理,最后文本状态是“已就绪”就是 OK 了。

最后,我们来测试一下,看能否检索到对应内容:
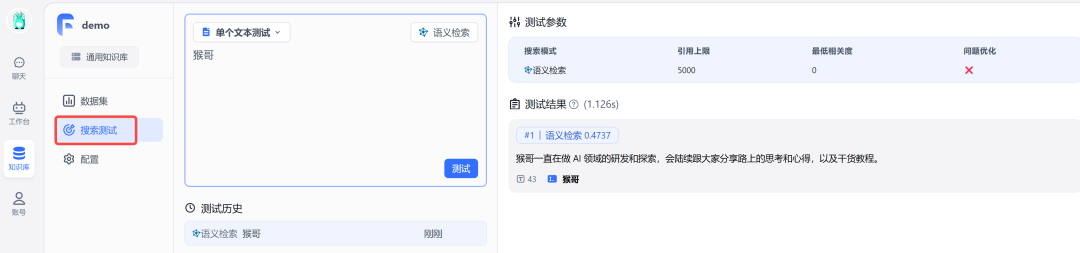
Ok,知识库搭建完毕!
2.3 新建应用
登录 FastGPT 后,先新建一个简易应用:
进入应用后,AI 模型 :需要选择刚才放到 config.json 中的 glm 模型。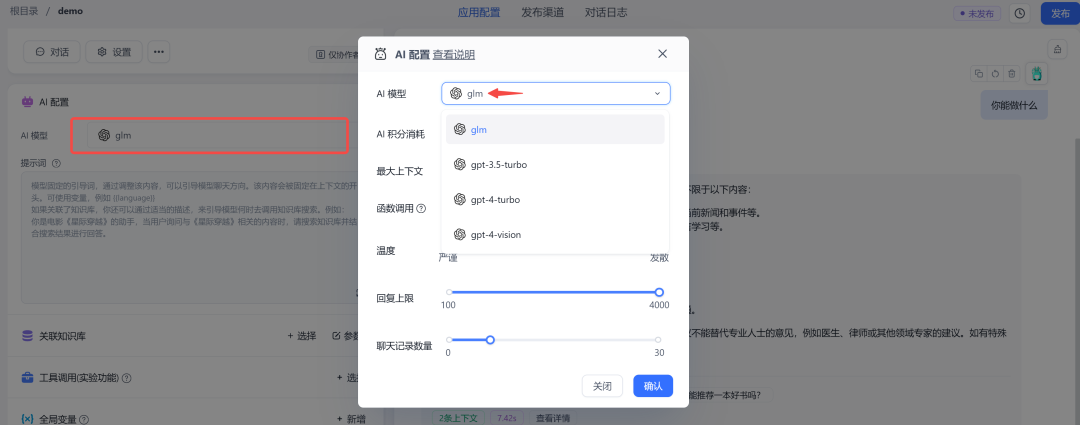
然后,把刚刚建立的知识库,关联进来。
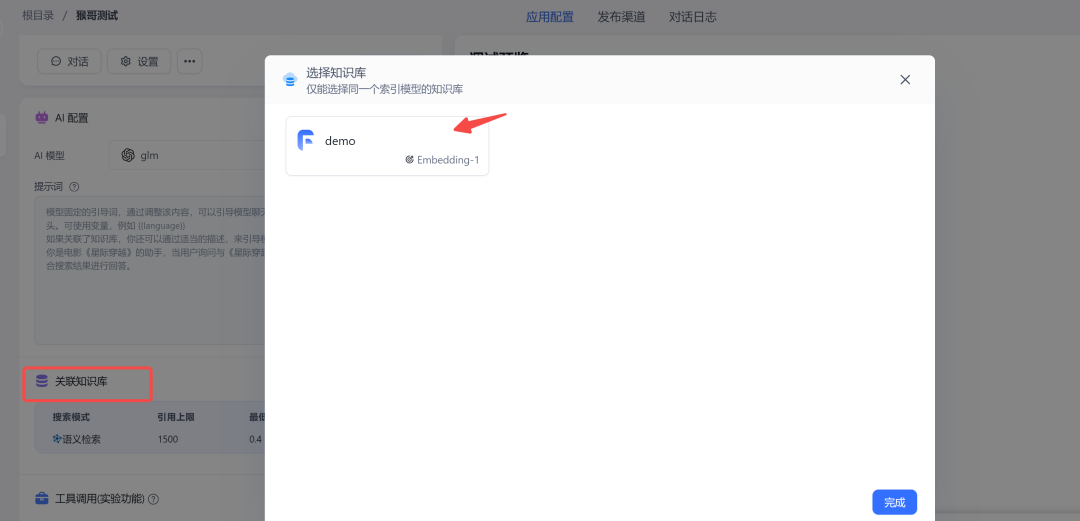
配置完成后,我们在右侧调试一下。比如我问他 “猴哥是谁”,他会先从知识库中检索到相关信息再回答我:
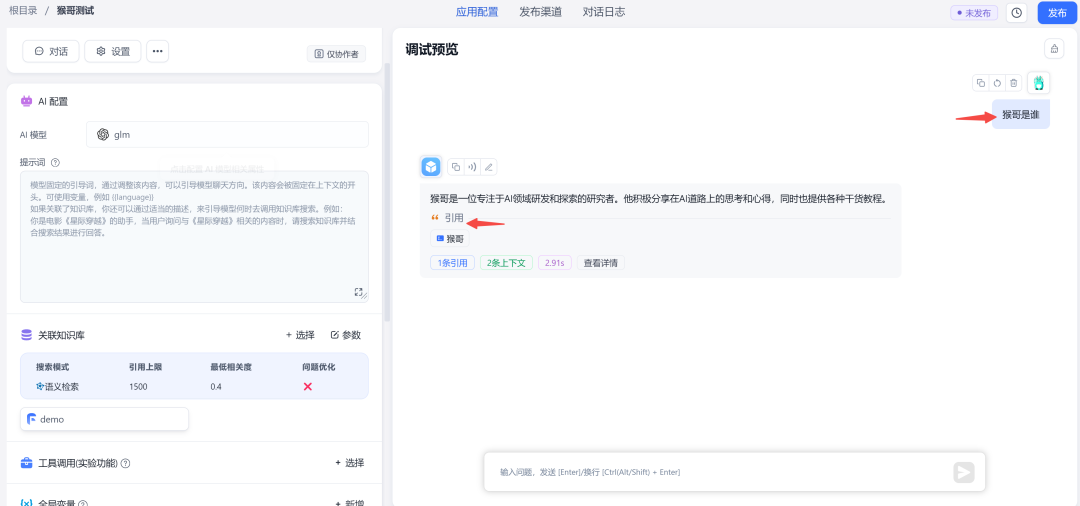
如果调试没问题了,再点击右上角 发布。成功后,你就拥有一个本地私有知识库增强的 LLM 了。
2.4. API 调用
为了在应用中能够调用刚发布的机器人,我们还需要一个兼容 OpenAI 格式的 API。
别急,FastGPT 也帮你搞定了!
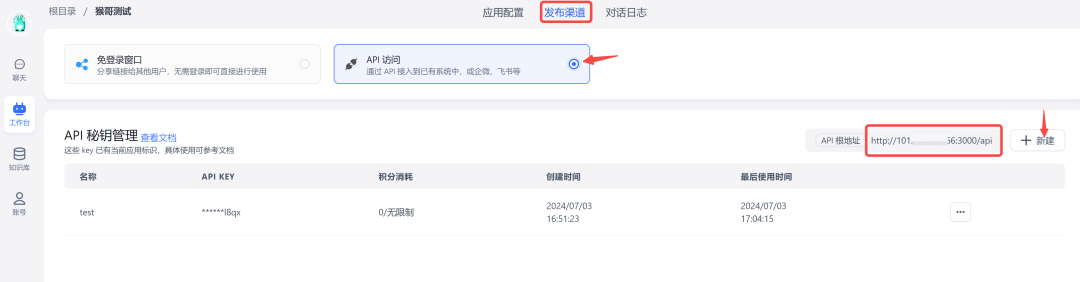
如下图,在刚才发布的应用中间,点击 发布渠道-> API 访问,右侧点击新建,将密钥保存下来,这就是 api_key。
base_url 在哪?红色方框处自取👇
有了 api_key 和 base_url,API 调用就很容易了,关注我的老朋友可能已经非常熟悉以下测试代码(记得 base_url 后面加上/v1):
from openai import OpenAI
model_dict = {
'fastgpt': {
'api_key': 'fastgpt-zWqC4UyMKMdWrtFLCJ3Jgma7CkcScKbkxW4Xf42',
'base_url': 'http://101.33.210.xxx:3000/api/v1',
'model_name': 'glm-4'
}
}
class LLM_API:
def __init__(self, api_key, base_url, model):
self.client = OpenAI(
api_key=api_key,
base_url=base_url,
)
self.model = model
def __call__(self, messages, temperature=0.7):
completion = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
)
return completion.choices[-1].message.content
if __name__ == '__main__':
model = 'fastgpt'
llm = LLM_API(model_dict[model]['api_key'], model_dict[model]['base_url'], model_dict[model]['model_name'])
user_question = "猴哥是谁"
messages = [{"role": "user", "content": user_question},]
print(llm(messages))
还记得么?上一篇中,我们采用 chatgpt-on-wechat 搭建了一个微信机器人。
如果把上述 api_key 和 base_url 放到 chatgpt-on-wechat 的配置文件 config.json 中,不就相当于让我们的微信机器人也拥有了基于私有知识库回答问题的能力?
感兴趣的小伙伴赶紧试试吧~
写在最后
如果说,OneAPI 帮你一键封装好所有 LLM 的调用接口,实现 LLM 自由 ~
那么,FastGPT 则为你的 LLM 插上了知识库的翅膀,实现私有知识库自由 ~
祝大家借助 OneAPI+FastAPI 玩转大模型,开发出更多 AI 创意应用。
如果你对AI大模型应用感兴趣,这套大模型学习资料一定对你有用。
1.大模型应用学习大纲
AI大模型应用所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

2.从入门到精通全套视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。

3.技术文档和电子书
整理了行业内PDF书籍、行业报告、文档,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。


朋友们如果有需要全套资料包,可以点下面卡片获取,无偿分享!

















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









