







 超级会员免费看
超级会员免费看
 本文介绍了Scrapy中用于提取数据的四个方法:extract()返回所有匹配的数据列表,extract_first()获取列表中的第一个数据,get()与extract_first()行为相同,而getall()则类似于extract()。get()和getall()在没有匹配项时会引发错误,而旧方法则返回None。
本文介绍了Scrapy中用于提取数据的四个方法:extract()返回所有匹配的数据列表,extract_first()获取列表中的第一个数据,get()与extract_first()行为相同,而getall()则类似于extract()。get()和getall()在没有匹配项时会引发错误,而旧方法则返回None。
1.extract()方法:
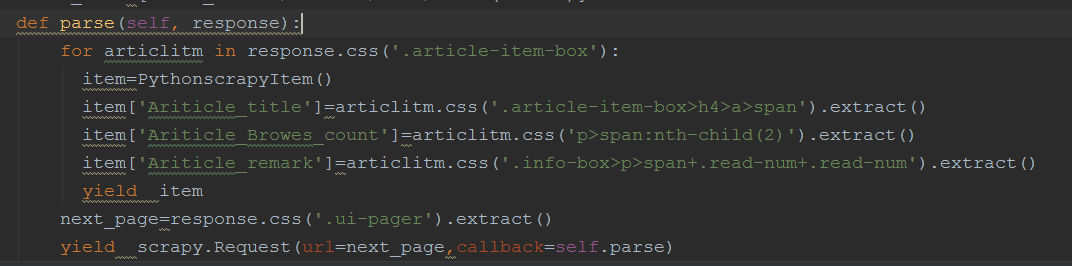
结果如下:
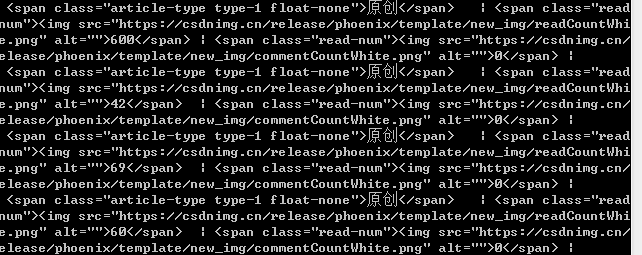
结论:说明了extract()方法返回的是符合要求的所有的数据,存在一个列表里。
2.extract_first()方法:
def parse(self, response):
sel = Selector(response)
hrefs = sel.xpath(r'//*[@class="c1 ico2"]/li/a/@href')
print(hrefs.extract_first())
结果如下:
'/4253340.html'
1
结论:说明了extract_first()方法返回的hrefs 列表里的第一个数据。
3.get()方法:
def parse(self, response):
sel = Selector(response)
hrefs = sel.xpath(r'

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1851
1851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











