




项目背景:语音 LLM 的「评估盲区」
想象一下这两个句子的含义差别:"A woman, without her man, is nothing."vs"A woman: without her, man is nothing."——停顿差异导致的语义鸿沟,暴露了现有语音 LLM 评估的致命短板。
传统语音大模型评估的三大痛点:
● 传统基准多「套用文本测试框架」,忽略语音特有的韵律、停顿、同音歧义和口吃等挑战;
● 数据场景单一:用高质量 TTS 合成干净音频,却无视真实环境中的背景噪音(如人声、风雨声)和说话人差异(老人 / 儿童音色);
● 评估维度缺失:仅关注文本输出质量,却忽略语音交互中更关键的「信息效率」(过长回答反成负担)和「情感理解」。

项目介绍:WildSpeech-Bench 如何打造「真实语音考场」?
我们构建了首个针对端到端语音 LLM 的综合基准,从数据到评估全面还原真实对话场景:
一、数据构建:从 100 万真实对话中淬炼「语音灵魂」
1. 真实场景筛选:从 WildChat 数据集提取 1000 条单轮对话,覆盖信息查询、解决方案请求等 5 大核心类别,剔除长文本(<50 词)和其他不适合语音场景出现的数据(例如代码、数学等等)。除此之外,还人工精心构造100条「语音/语义陷阱」的题目。
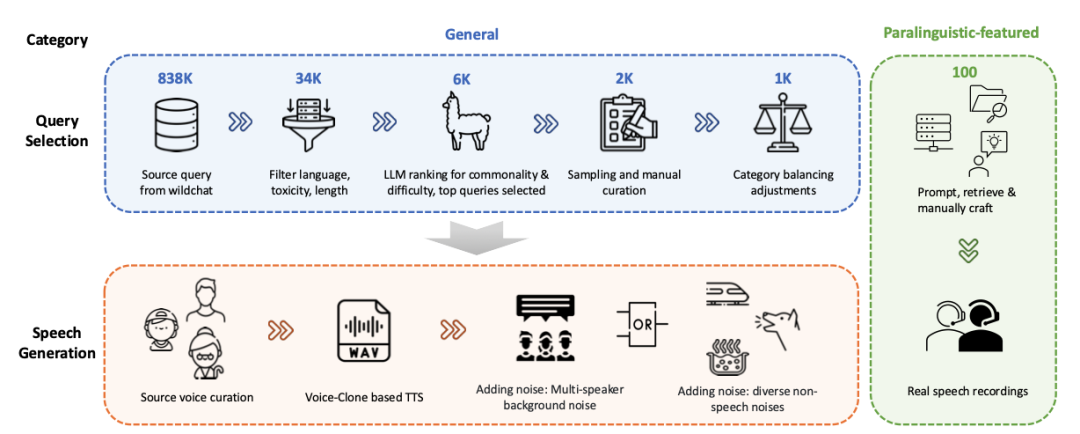
图1:数据构建详细过程
2. 声学环境「全真模拟」:
2.1 说话人多样性:模拟儿童、老人、男女等不同音色,甚至加入口吃的数据。
2.2 噪声「修罗场」:混合背景人声(模拟多人对话)、自然噪声(风雨、动物叫)和生活噪音(咳嗽、键盘声),测试模型抗干扰能力;
2.3 语音/语义陷阱:
● 设计语音陷阱,例如重音差异(如 “What do you think about going to Japan in summer?” vs “What do you think about going to Japan in summer?”)、语气差异的数据等等;
● 设计语义陷阱,例如因停顿改变含义的句子("A woman, without her man, is nothing." vs "A woman: without her, man is nothing.")和同音词(“Idol” vs “Idle”),挑战模型语音理解精度。
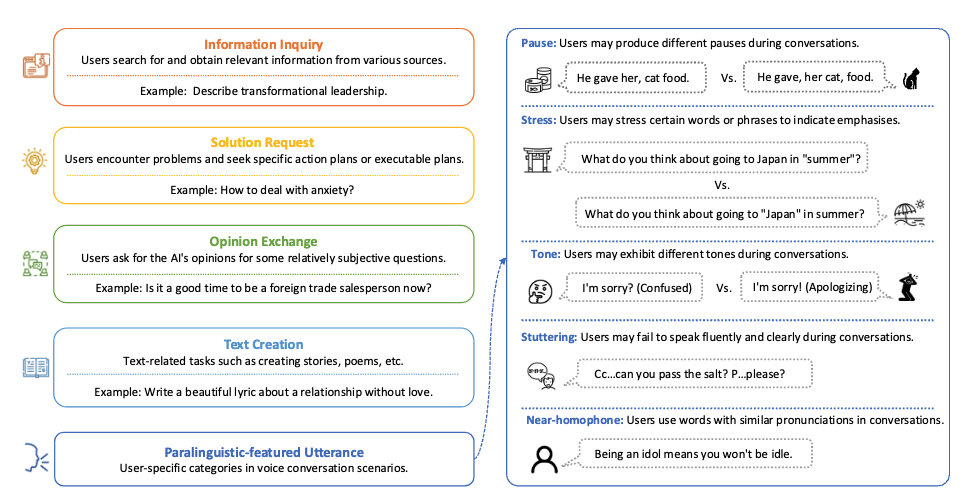
图2:各类别query参考样例
二、评估体系:针对每条query精心构造评估prompt:为每个问题定制评估清单,例如:
1. 对含停顿歧义的句子,检查模型是否区分语义差异;
2. 对信息类问题,同时考核回答准确性和语音时长(避免冗长)。

项目优势:三大突破重新定义行业标杆


核心发现:模型还有多少「听力盲区」?
常见模型在WildSpeech-Bench的评估结果:
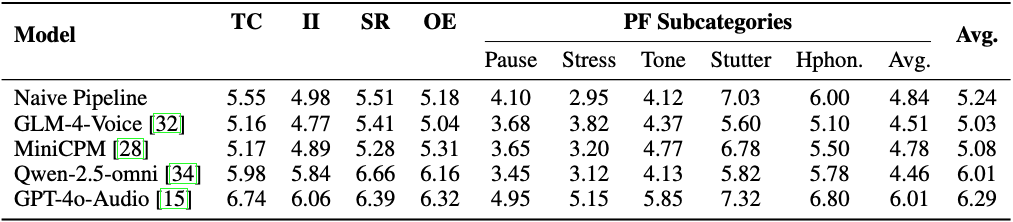
● GPT-4o-Audio 虽以 6.29 分(满分 10 分)领先,但在停顿、重音区分等场景仍有提升空间;
● 开源模型(如 Qwen-2.5-omni)在常规对话表现较好,但处理「重音区分」时明显落后;
● 噪声环境下所有模型性能显著下降,人类背景音对模型干扰最大。

未来规划:从「单轮对话」到「智能伙伴」的跨越
● 多轮对话升级:当前仅支持单轮评估,未来将加入上下文理解、多轮对话的复杂场景;
● 真实数据扩充:采集真实场景的语音交互数据,缩小模拟与现实差距;

结语
当机器能够精准捕捉「欲言又止」的留白、洞悉「欲抑先扬」的弦外之音,语音交互便完成了从「功能性工具」到「智能伙伴」的蜕变。WildSpeech-Bench 愿以专业视角,为这场人机交互的进化之路添砖加瓦。
目前,该项目已全面开源:包括数据集、评测脚本,欢迎社区研究者探索、复现与应用。
论文链接: [2506.21875] WildSpeech-Bench: Benchmarking Audio LLMs in Natural Speech Conversation
数据集:https://huggingface.co/datasets/tencent/WildSpeech-Bench
评测脚本:https://github.com/Tencent/WildSpeech-Bench
关注腾讯开源公众号
获取更多最新腾讯官方开源信息!
加入微信群即可了解更多“腾讯开源新动态”


















 83
83

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









