



7月7日,腾讯混元3D再次升级,带来了业界首个美术级3D生成大模型Hunyuan3D-PolyGen。
结合自研高压缩率表征BPT技术,该模型可生成面数达上万面的复杂几何模型,布线精度更高,细节更丰富,同时支持三边面和四边面,满足不同专业管线需求。基于此,混元3D资产可无缝应用于UGC游戏资产生成,显著提升美术师建模效率。
目前,该能力已上线腾讯混元 3D AI 创作引擎(体验地址:3d.hunyuan.tencent.com),欢迎体验,该技术也集成到腾讯多个游戏管线,助力美术师建模效率提升超70%。
模型主要是为解决3D资产生成中布线质量和复杂物体建模的难题,提升美术师建模效率。
当前,3D生成算法在几何建模方面已取得显著进展,但生成的模型与美术制作的专业标准仍存在明显差距,难以直接应用于游戏开发等专业管线。

图1. 3D生成Mesh vs 美术Mesh
主要问题体现在以下三个方面:
面数过高:生成网格(Mesh)的面片数量动辄高达数十万,无法满足游戏实时加载与渲染的需求。
布线质量欠佳:网格布线杂乱无章,影响模型美观度,并对后续的UV展开、骨骼绑定等环节造成阻碍。
编辑难度大:生成结果为单一整体网格,难以拆分,限制了美术师的后期编辑能力。
为解决以上问题,PolyGen做了一系列的技术创新。
1.算法框架
为实现从“可看”到“可用”的3D生成,Hunyuan3D-PolyGen采用自回归网格生成框架,通过显式、离散的顶点与面片建模,进行空间推理,生成高质量、符合美术规范的3D模型。其核心框架(见图2)包括以下三个步骤:
网格序列化:将网格的顶点和面片转化为Token序列,用以表示Mesh结构。
自回归建模:以点云作为输入Prompt,利用自回归模型生成Mesh的Token序列。
序列解码:将生成的Token序列反向解码为顶点与面片,重建3D网格。
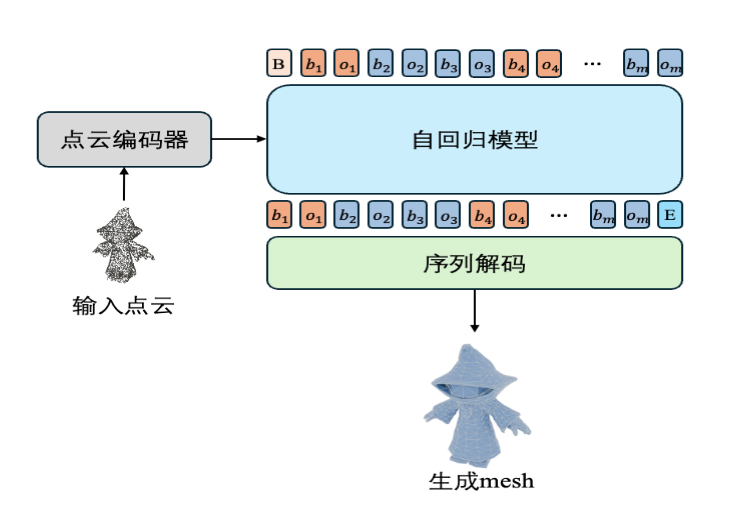
图2. Mesh自回归生成框架
2.技术难点与解决方案
难点一:对于复杂物体的建模
解决方案:自研高压缩率表征BPT
现有的mesh自回归方法,表达一个面通常需要9个token(一个面片三个顶点,每个顶点三个坐标),mesh表达冗余程度高,在给定有限的上下文窗口下,仅可对低面片(2k面以下)的简单模型进行建模,为了提升可建模面数,实现复杂mesh建模,我们自研了高压缩率mesh表征BPT(Blocked and Patchified Tokenization),设计block索引和patch压缩,使表达相同 mesh 所需的token序列更短,如下图所示:
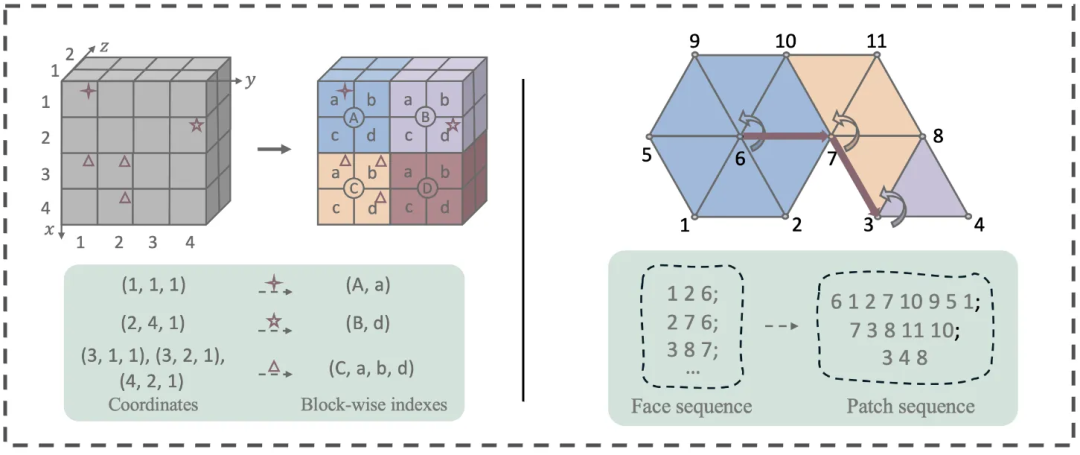
图3. 自研高压缩率mesh表征BPT
1) block索引:将网格空间分成多个block,顶点的表征由(x,y,z)空间坐标转化为(block, offset)索引坐标,token数量可降低33%;
2) patch压缩:将相邻面片组成patch(一个中心顶点和边缘顶点),减少相邻面片之间共用顶点的冗余,结合共享block等技巧,token数量可进一步降低约41%。
利用以上压缩算法BPT,表征mesh的token数量可压缩74%,即平均用2.3个token即可表征一个面,极大提升了模型的可建模面数,由下图可看出,对比现有mesh自回归方法,可建模的模型更加复杂(可达2w+面),细节更多。
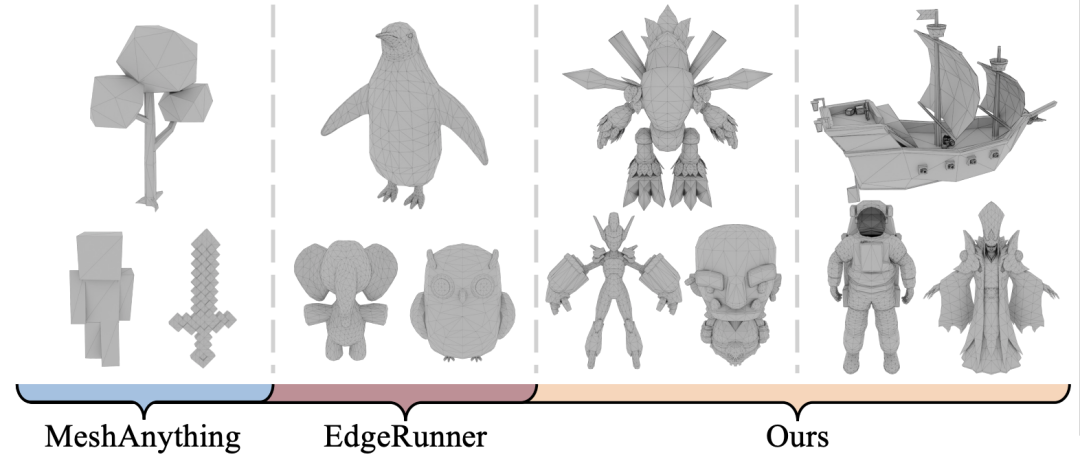
图4. 混元3D-PolyGen与现有SOTA方法可建模复杂度对比
难点二:mesh自回归生成稳定性低
解决方案:引入强化学习后训练
mesh自回归生成的另一个重大的挑战是生成的稳定性低,同一个模型的多次生成结果可能有较大差异,如图5所示。这其中包含两方面原因:一方面是mesh生成的容错率低,生成一个错误的坐标可能就会导致整体的生成失败;另一方面是mesh的token序列较长(可达上十万),更容易产生错误。

图5. mesh自回归生成存在稳定性差问题,同一个模型生成结果差异较大
为此,我们研发了mesh自回归的强化学习后训练框架(如图6所示),在预训练模型的基础上进行后训练,设计稳定生成和美术规范奖励来引导模型生成更好的结果。通过强化学习,可以提升模型生成“好结果”的概率,降低模型生成“差结果”的概率,从而提升了模型生成的稳定性。
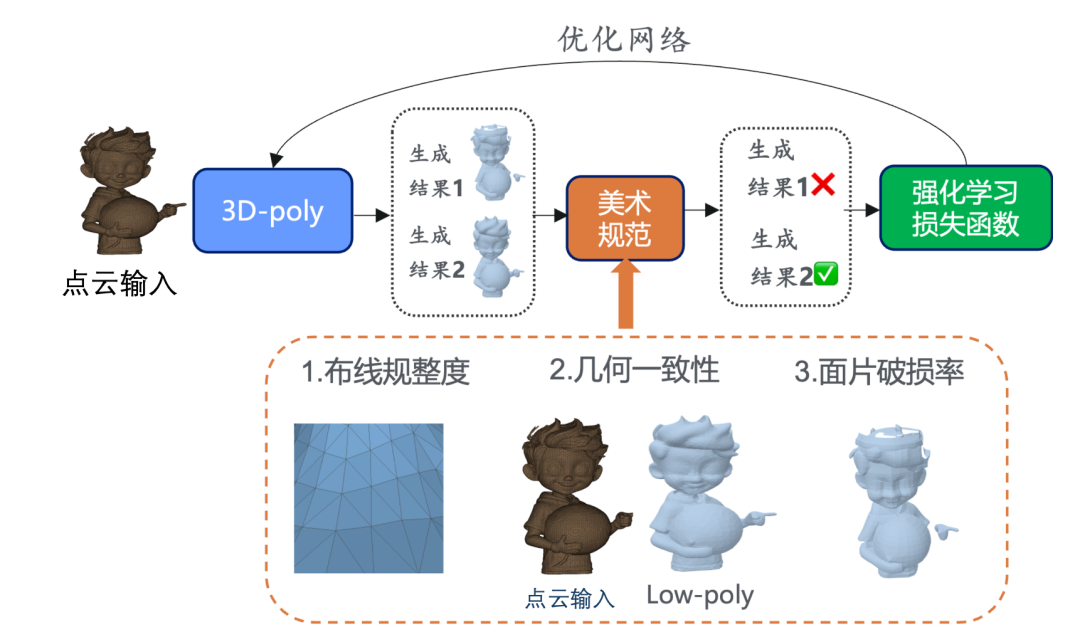
图6. 混元3D-PolyGen强化学习后训练模块
效果对比
1.Hunyuan3D-PolyGen vs Mesh自回归SOTA算法
mesh自回归方法在生成复杂物体时容易出现破损、细节丢失、布线杂乱等问题,相比之下,混元3D-PolyGen在生成的稳定性、细节、布线质量等方面均优于目前SOTA模型。
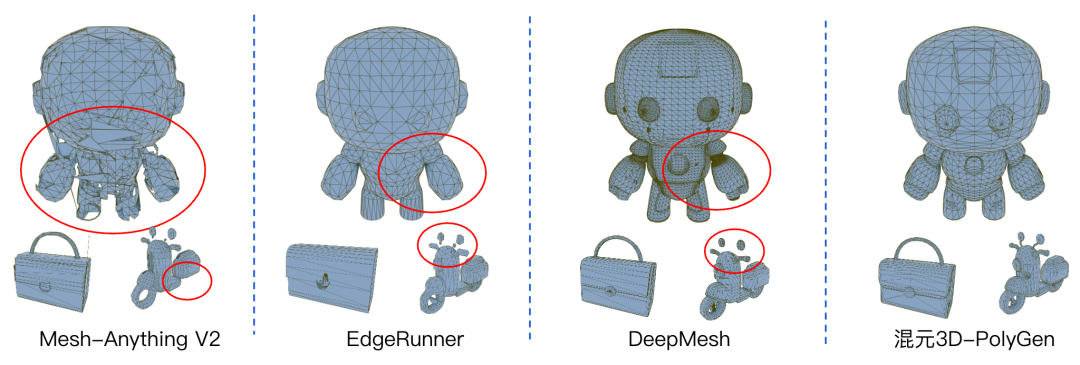
图7. Hunyuan3D-PolyGen与SOTA方法效果对比
2. Hunyuan3D-PolyGen vs 业界重拓扑接口
为了解决前面提到的面数和布线问题,业界通常采用传统的图形学重拓扑算法对布线进行优化,现有重拓扑方法虽然能生成相对规整的布线,但其面片大小分布均匀,在给定较低面数时,会导致细节丢失。相比竞品的重拓扑/AI拓扑方法,混元3D-PolyGen可根据几何结构自适应分配面数,可利用更低的面数实现更好的细节。
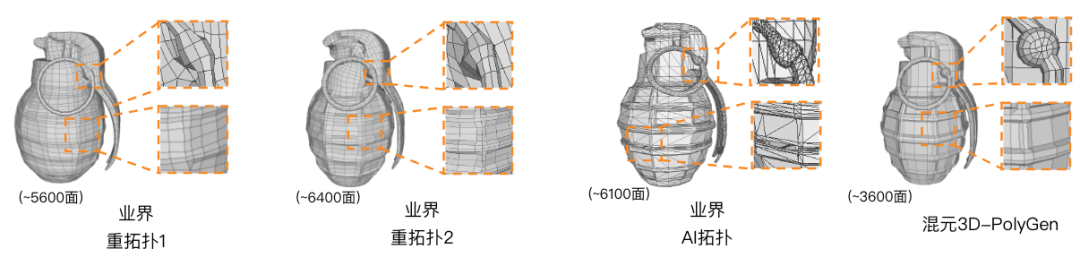
图8. 相比于业界的重拓扑/AI拓扑算法,Hunyuan3D-PolyGen可以智能分配面数,达到更好的细节。
效果对比:
输入图

效果

输入图

效果
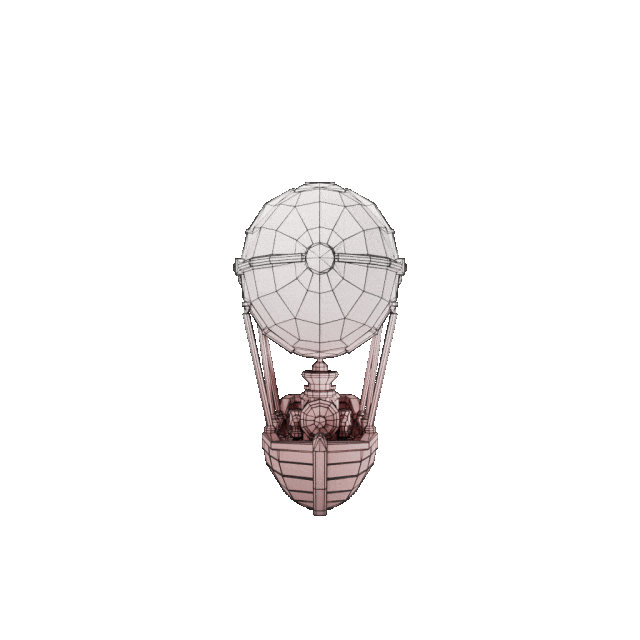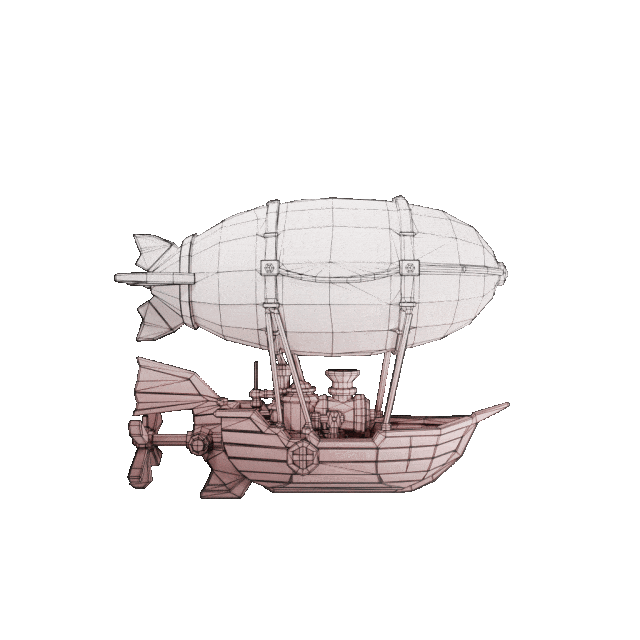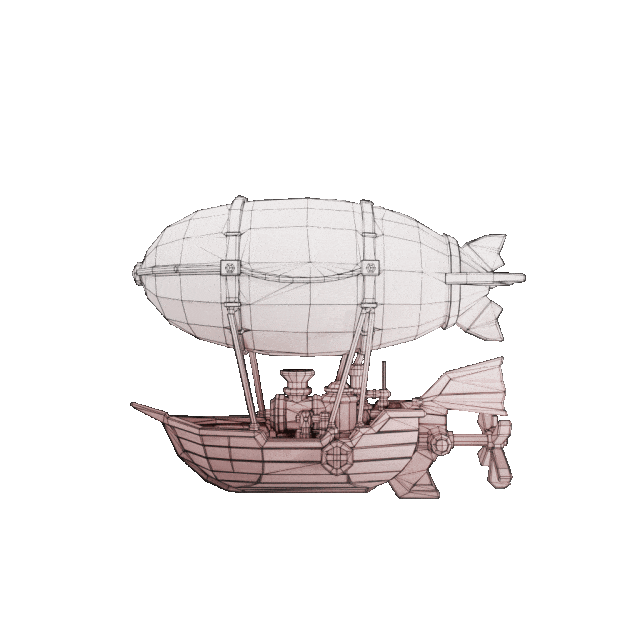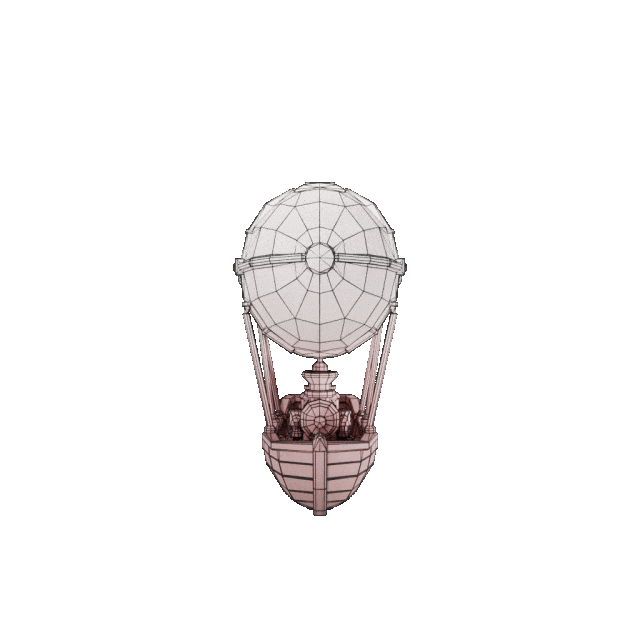
输入图

效果

体验入口:
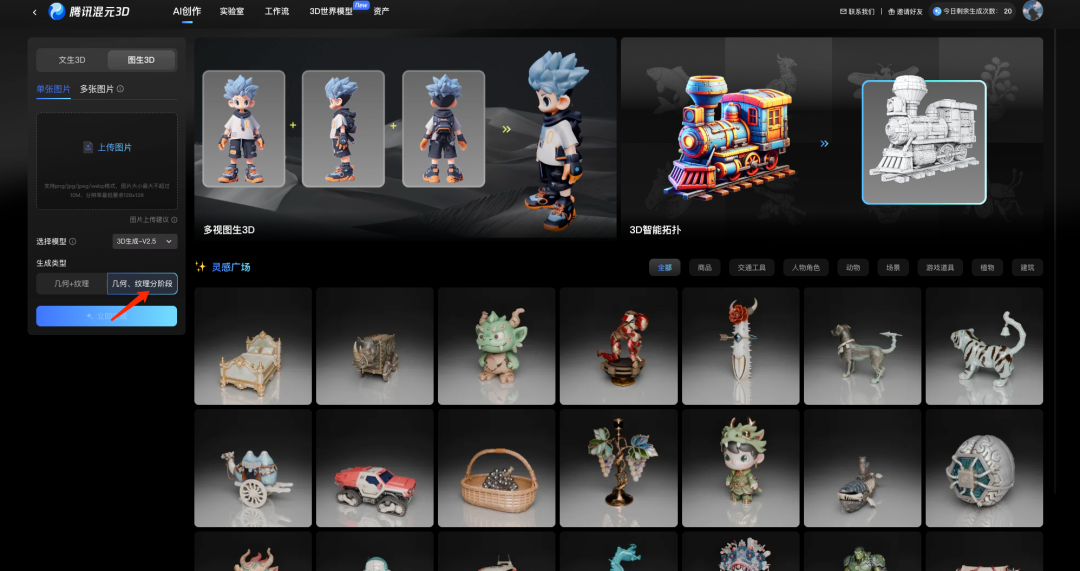
1.首页"3D智能拓扑“
2.实验室->3D智能拓扑
3.首页”文生3D“、"图生3D”选择“几何、纹理分阶段”,在生成几何模型后,可选择“智能拓扑”

关注腾讯开源公众号
获取更多最新腾讯官方开源信息!
加入微信群即可了解更多“腾讯开源新动态”

点击👇阅读原文,即刻体验。

















 2695
2695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









