









目录
一、概述
1.1、软件介绍
SeaTunnel是一个非常易用、超高性能的分布式数据集成平台,支持实时海量数据同步。 每天可稳定高效同步数百亿数据,已被近百家企业应用于生产。
Apache SeaTunnel是中国开发者主导的项目,也是Apache基金会中第一个诞生自中国的数据集成平台项目。
SeaTunnel原名Waterdrop,于2017年由乐视创建,并于同年在GitHub上开源
2021年10月改名为SeaTunnel
2021年12月9日SeaTunnel进入Apache孵化
2023年6月1日Apache SeaTunnel 毕业成为 Apache 顶级项目
Seatunnel的中文是"水滴",来自中国当代科幻小说作家刘慈欣的《三体》系列,它是三体人制造的宇宙探测器,会反射几乎全部的电磁波,表面绝对光滑,温度处于绝对零度,全部由被强互作用力紧密锁死的质子与中子构成,无坚不摧。在末日之战中,仅一个水滴就摧毁了人类太空武装力量近2千艘战舰
官网地址:
Apache SeaTunnel | Apache SeaTunnel
1.2、解决问题
SeaTunnel专注于数据集成和数据同步,主要旨在解决数据集成领域的常见问题:
- 数据源多样:常用数据源有数百种,版本不兼容。 随着新技术的出现,更多的数据源不断出现。 用户很难找到一个能够全面、快速支持这些数据源的工具。
- 同步场景复杂:数据同步需要支持离线全量同步、离线增量同步、CDC、实时同步、全库同步等多种同步场景。
- 资源需求高:现有的数据集成和数据同步工具往往需要大量的计算资源或JDBC连接资源来完成海量小表的实时同步。 这增加了企业的负担。
- 缺乏质量和监控:数据集成和同步过程经常会出现数据丢失或重复的情况。 同步过程缺乏监控,无法直观了解任务过程中数据的真实情况。
- 技术栈复杂:企业使用的技术组件不同,用户需要针对不同组件开发相应的同步程序来完成数据集成。
- 管理和维护困难:受限于底层技术组件(Flink/Spark)不同,离线同步和实时同步往往需要分开开发和管理,增加了管理和维护的难度。
1.3、软件特性
- 丰富且可扩展的Connector:SeaTunnel提供了不依赖于特定执行引擎的Connector API。 基于该API开发的Connector(Source、Transform、Sink)可以运行在很多不同的引擎上,例如目前支持的SeaTunnel引擎(Zeta)、Flink、Spark等。
- Connector插件:插件式设计让用户可以轻松开发自己的Connector并将其集成到SeaTunnel项目中。 目前,SeaTunnel 支持超过 100 个连接器,并且数量正在激增。
- 批流集成:基于SeaTunnel Connector API开发的Connector完美兼容离线同步、实时同步、全量同步、增量同步等场景。 它们大大降低了管理数据集成任务的难度。
- 支持分布式快照算法,保证数据一致性。
- 多引擎支持:SeaTunnel默认使用SeaTunnel引擎(Zeta)进行数据同步。 SeaTunnel还支持使用Flink或Spark作为Connector的执行引擎,以适应企业现有的技术组件。 SeaTunnel 支持 Spark 和 Flink 的多个版本。
- JDBC复用、数据库日志多表解析:SeaTunnel支持多表或全库同步,解决了过度JDBC连接的问题; 支持多表或全库日志读取解析,解决了CDC多表同步场景下需要处理日志重复读取解析的问题。
- 高吞吐量、低延迟:SeaTunnel支持并行读写,提供稳定可靠、高吞吐量、低延迟的数据同步能力。
- 完善的实时监控:SeaTunnel支持数据同步过程中每一步的详细监控信息,让用户轻松了解同步任务读写的数据数量、数据大小、QPS等信息。
- 支持两种作业开发方法:编码和画布设计。 SeaTunnel Web 项目 GitHub - apache/seatunnel-web: SeaTunnel is a distributed, high-performance data integration platform for the synchronization and transformation of massive data (offline & real-time). 提供作业、调度、运行和监控功能的可视化管理。
1.4、使用用户
SeaTunnel 拥有大量用户

1.5、产品对比
| 对比项 | Apache SeaTunnel | DataX | Apache Sqoop | Apache Flume | Flink CDC |
| 部署难度 | 容易 | 容易 | 中等,依赖于 Hadoop 生态系统 | 容易 | 中等,依赖于 Hadoop 生态系统 |
| 运行模式 | 分布式,也支持单机 | 单机 | 本身不是分布式框架,依赖 Hadoop MR 实现分布式 | 分布式,也支持单机 | 分布式,也支持单机 |
| 健壮的容错机制 | 无中心化的高可用架构设计,有完善的容错机制 | 易受比如网络闪断、数据源不稳定等因素影响 | MR 模式重,出错处理麻烦 | 有一定的容错机制 | 主从模式的架构设计,容错粒度比较粗,容易造成延时 |
| 支持的数据源丰富度 | 支持 MySQL、PostgreSQL、Oracle、SQLServer、Hive、S3、RedShift、HBase、Clickhouse等过 100 种数据源 | 支持 MySQL、ODPS、PostgreSQL、Oracle、Hive 等 20+ 种数据源 | 仅支持 MySQL、Oracle、DB2、Hive、HBase、S3 等几种数据源 | 支持 Kafka、File、HTTP、Avro、HDFS、Hive、HBase等几种数据源 | 支持 MySQL、PostgresSQL、MongoDB、SQLServer 等 10+ 种数据源 |
| 内存资源占用 | 少 | 多 | 多 | 中等 | 多 |
| 数据库连接占用 | 少(可以共享 JDBC 连接) | 多 | 多 | 多 | 多(每个表需一个连接) |
| 自动建表 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 整库同步 | 支持 | 不支持 | 不支持 | 不支持 | 不支持(每个表需配置一次) |
| 断点续传 | 支持 | 不支持 | 不支持 | 不支持 | 支持 |
| 多引擎支持 | 支持 SeaTunnel Zeta、Flink、Spark 3 个引擎选其一作为运行时 | 只能运行在 DataX 自己引擎上 | 自身无引擎,需运行在 Hadoop MR 上,任务启动速度非常慢 | 支持 Flume 自身引擎 | 只能运行在 Flink 上 |
| 数据转换算子(Transform) | 支持 Copy、Filter、Replace、Split、SQL 、自定义 UDF 等算子 | 支持补全,过滤等算子,可以 groovy 自定义算子 | 只有列映射、数据类型转换和数据过滤基本算子 | 只支持 Interceptor 方式简单转换操作 | 支持 Filter、Null、SQL、自定义 UDF 等算子 |
| 单机性能 | 比 DataX 高 40% - 80% | 较好 | 一般 | 一般 | 较好 |
| 离线同步 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 增量同步 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 实时同步 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| CDC同步 | 支持 | 不支持 | 不支持 | 不支持 | 支持 |
| 批流一体 | 支持 | 不支持 | 不支持 | 不支持 | 支持 |
| 精确一致性 | MySQL、Kafka、Hive、HDFS、File 等连接器支持 | 不支持 | 不支持 | 不支持精确,提供一定程度的一致性 | MySQL、PostgreSQL、Kakfa 等连接器支持 |
| 可扩展性 | 插件机制非常易扩展 | 易扩展 | 扩展性有限,Sqoop主要用于将数据在Apache Hadoop和关系型数据库之间传输 | 易扩展 | 易扩展 |
| 统计信息 | 有 | 有 | 无 | 有 | 无 |
| Web UI | 正在实现中(拖拉拽即可完成) | 无 | 无 | 无 | 无 |
| 与调度系统集成度 | 已经与 DolphinScheduler 集成,后续也会支持其他调度系统 | 不支持 | 不支持 | 不支持 | 无 |
| 社区 | 非常活跃 | 非常不活跃 | 已经从 Apache 退役 | 非常不活跃 | 非常活跃 |
二、架构
2.1、运行流程
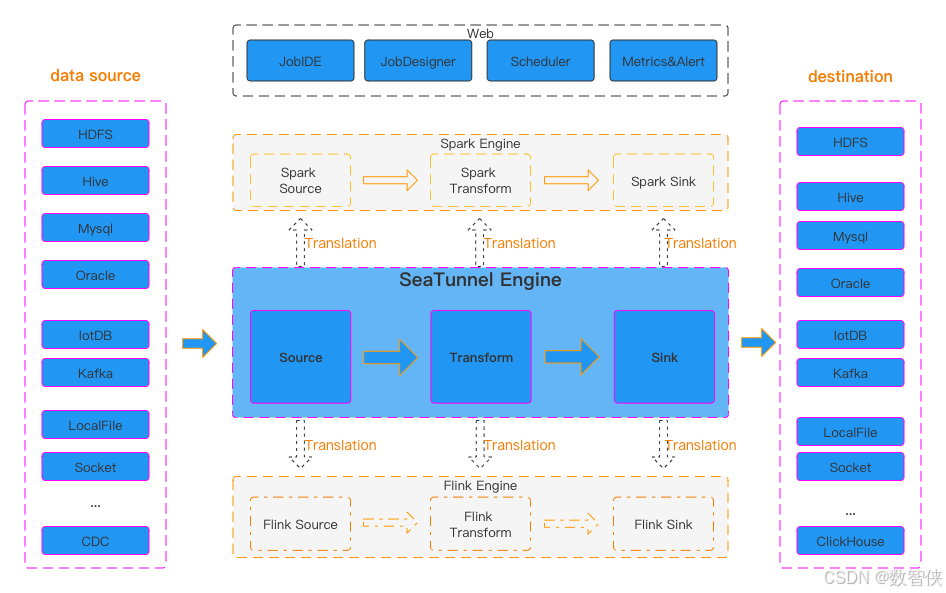
SeaTunnel的运行流程如上图所示。
用户配置作业信息并选择提交作业的执行引擎。
Source Connector负责并行读取数据并将数据发送到下游Transform或直接发送到Sink,Sink将数据写入目的地。 值得注意的是,Source、Transform 和 Sink 可以很容易地自行开发和扩展。
SeaTunnel 是一个 EL(T) 数据集成平台。 因此,在SeaTunnel中,Transform只能用于对数据进行一些简单的转换,例如将一列的数据转换为大写或小写,更改列名,或者将一列拆分为多列。
SeaTunnel 使用的默认引擎是 SeaTunnel Engine。 如果您选择使用Flink或Spark引擎,SeaTunnel会将Connector打包成Flink或Spark程序并提交给Flink或Spark运行。
2.2、连接器
-
源连接器 SeaTunnel 支持从各种关系、图形、NoSQL、文档和内存数据库读取数据; 分布式文件系统,例如HDFS; 以及各种云存储解决方案,例如S3和OSS。 我们还支持很多常见SaaS服务的数据读取。 您可以在[此处] 访问详细列表。 如果您愿意,您可以开发自己的源连接器并将其轻松集成到 SeaTunnel 中。
-
转换连接器 如果源和接收器之间的架构不同,您可以使用转换连接器更改从源读取的架构,使其与接收器架构相同。
-
Sink Connector SeaTunnel 支持将数据写入各种关系型、图形、NoSQL、文档和内存数据库; 分布式文件系统,例如HDFS; 以及各种云存储解决方案,例如S3和OSS。 我们还支持将数据写入许多常见的 SaaS 服务。 您可以在[此处]访问详细列表。 如果您愿意,您可以开发自己的 Sink 连接器并轻松将其集成到 SeaTunnel 中。
2.3、引擎
2.3.1、设计理念
SeaTunnel Engine 是一个由社区开发的用于数据同步场景的引擎,作为 SeaTunnel 的默认引擎,它支持高吞吐量、低延迟和强一致性的数据同步作业操作,更快、更稳定、更节省资源且易于使用。
SeaTunnel Engine 的整体设计遵循以下路径:
- 更快,SeaTunnel Engine 的执行计划优化器旨在减少数据网络传输,从而减少由于数据序列化和反序列化造成的整体同步性能损失,使用户能够更快地完成数据同步操作。同时,支持速度限制,以合理速度同步数据。
- 更稳定,SeaTunnel Engine 使用 Pipeline 作为数据同步任务的最小粒度的检查点和容错。任务的失败只会影响其上游和下游任务,避免了任务失败导致整个作业失败或回滚的情况。同时,SeaTunnel Engine 还支持数据缓存,用于源数据有存储时间限制的场景。当启用缓存时,从源读取的数据将自动缓存,然后由下游任务读取并写入目标。在这种情况下,即使由于目标失败而无法写入数据,也不会影响源的常规读取,防止源数据过期被删除。
- 节省空间,SeaTunnel Engine 内部使用动态线程共享技术。在实时同步场景中,对于每个表数据量很大但每个表数据量很小的表,SeaTunnel Engine 将在共享线程中运行这些同步任务,以减少不必要的线程创建并节省系统空间。在读取和写入数据方面,SeaTunnel Engine 的设计目标是最小化 JDBC 连接的数量;在 CDC 场景中,SeaTunnel Engine 将重用日志读取和解析资源。
- 简单易用,SeaTunnel Engine 减少了对第三方服务的依赖,并且可以独立于如 Zookeeper 和 HDFS 等大数据组件实现集群管理、快照存储和集群 HA 功能。这对于目前缺乏大数据平台的用户,或者不愿意依赖大数据平台进行数据同步的用户来说非常有用。
未来,SeaTunnel Engine 将进一步优化其功能,以支持离线批同步的全量同步和增量同步、实时同步和 CDC。
2.3.2、集群管理
- 支持独立运行;
- 支持集群运行;
- 支持自治集群(去中心化),使用户无需为 SeaTunnel Engine 集群指定主节点,因为它可以在运行过程中自行选择主节点,并且在主节点失败时自动选择新的主节点;
- 自治集群节点发现和具有相同 cluster_name 的节点将自动形成集群。
2.3.3、核心功能
- 支持在本地模式下运行作业,作业完成后集群自动销毁;
- 支持在集群模式下运行作业(单机或集群),通过 SeaTunnel 客户端将作业提交给 SeaTunnel Engine 服务,作业完成后服务继续运行并等待下一个作业提交;
- 支持离线批同步;
- 支持实时同步;
- 批流一体,所有 SeaTunnel V2 Connector 均可在 SeaTunnel Engine 中运行;
- 支持分布式快照算法,并支持与 SeaTunnel V2 Connector 的两阶段提交,确保数据只执行一次。
- 支持在 Pipeline 级别调用作业,以确保即使在资源有限的情况下也能启动;
- 支持在 Pipeline 级别对作业进行容错。任务失败只影响其所在 Pipeline,只需要回滚 Pipeline 下的任务;
- 支持动态线程共享,以实时同步大量小数据集。
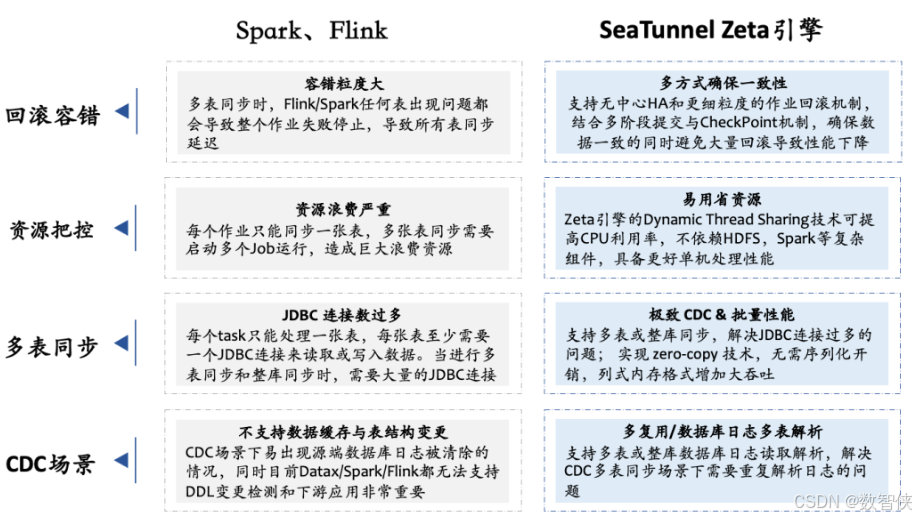
2.3.4、引擎对比
Apache SeaTunne默认使用的是自研的SeaTunne Zeta引擎,还支持Spark、Flink计算引擎
三、软件部署
3.1、Docker部署
3.1.1、拉取镜像
docker pull apache/seatunnel:2.3.83.1.2、任务提交
# Run fake source to console sink
docker run --rm -it apache/seatunnel:<version_tag> ./bin/seatunnel.sh -m local -c config/v2.batch.config.template
# Run job with custom config file
docker run --rm -it -v /<The-Config-Directory-To-Mount>/:/config apache/seatunnel:<version_tag> ./bin/seatunnel.sh -m local -c /config/fake_to_console.conf
# Example
# If you config file is in /tmp/job/fake_to_console.conf
docker run --rm -it -v /tmp/job/:/config apache/seatunnel:<version_tag> ./bin/seatunnel.sh -m local -c /config/fake_to_console.conf
# Set JVM options when running
docker run --rm -it -v /tmp/job/:/config apache/seatunnel:<version_tag> ./bin/seatunnel.sh -DJvmOption="-Xms4G -Xmx4G" -m local -c /config/fake_to_console.conf3.2、发布包部署
下载地址:
https://seatunnel.incubator.apache.org/download
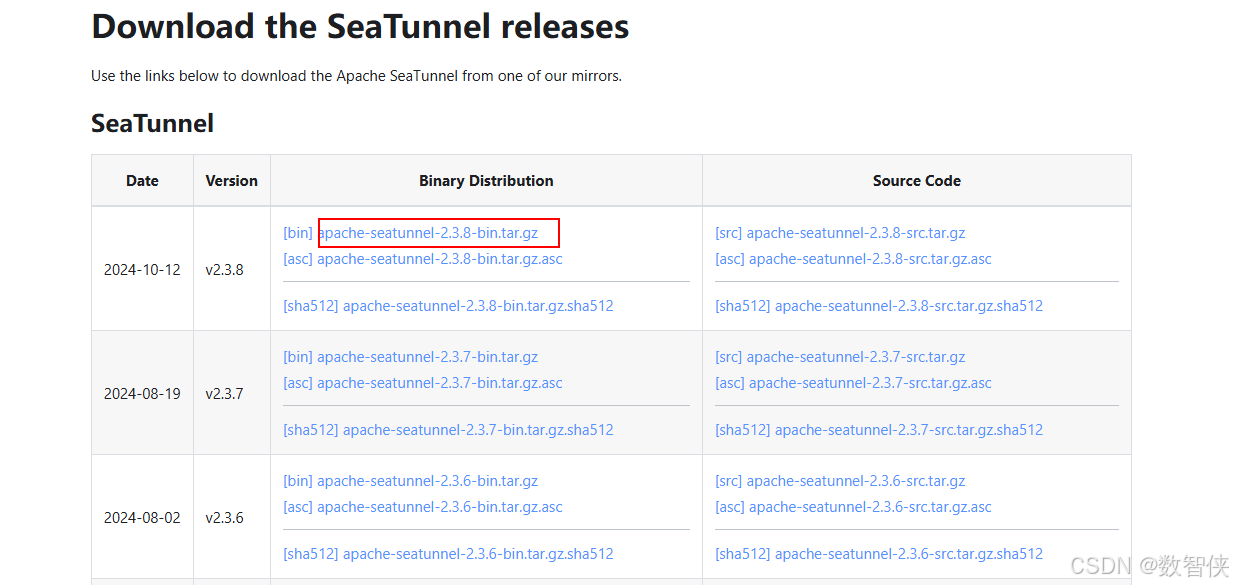
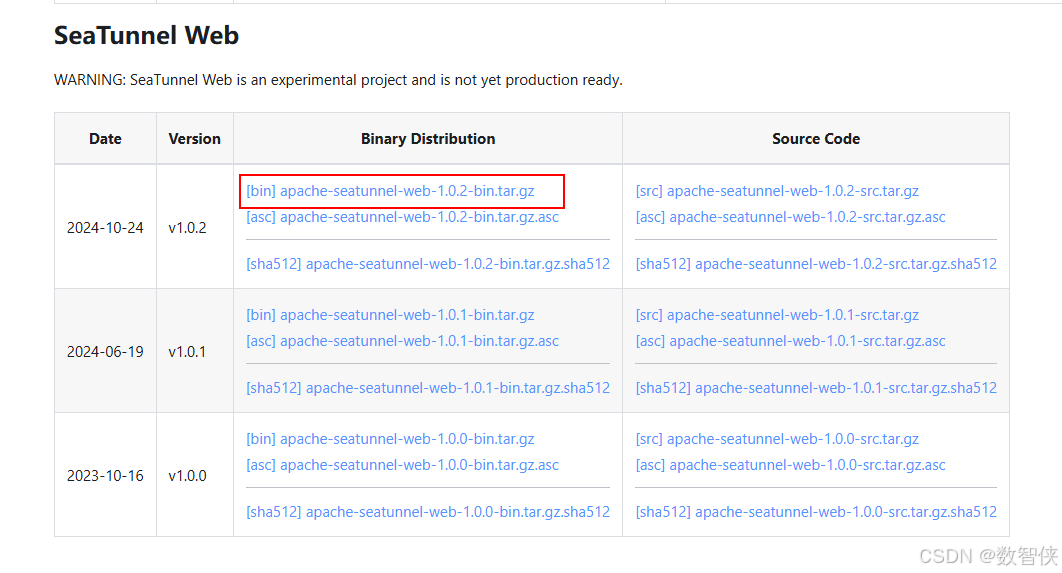
上面下载太慢,可以使用国内镜像
apache-seatunnel-2.3.8安装包下载_开源镜像站-阿里云
部署参考:https://seatunnel.incubator.apache.org/zh-CN/docs/2.3.8/start-v2/locally/deployment
3.2.1、Apache SeaTunnel部署与使用
3.2.1.1、软件解压
cd /usr/local/soft/
tar -zxvf apache-linkis-1.6.0-bin.tar.gz3.2.1.2、安装插件
安装插件前需要进行Maven镜像地址更换与一些不用的插件不需要下载
cd /usr/local/soft/apache-seatunnel-2.3.8/
sh bin/install-plugin.sh3.2.1.2.1 更换maven地址
整个过程非常慢…从国外maven中央仓库下载东西,可以使用maven的阿里云镜像
setting文件地址:/root/.m2/wrapper/dists/apache-maven-3.8.4-bin/52ccbt68d252mdldqsfsn03jlf/apache-maven-3.8.4/conf/
换成阿里云镜像
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/central</url>
</mirror>
<mirror>
<id>aliyun-maven</id>
<mirrorOf>*</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror> 
更换后再下载速度很快
3.2.1.2.2 减少插件下载
默认插件全部下载,如果自己用不到,可以注释掉,因为即便下载了也不用,占用空间,如果下载有需要可以再下载,配置地址如下:/usr/local/soft/apache-seatunnel-2.3.8/config/plugin_config
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
#
# This mapping is used to resolve the Jar package name without version (or call artifactId)
#
# corresponding to the module in the user Config, helping SeaTunnel to load the correct Jar package.
# Don't modify the delimiter " -- ", just select the plugin you need
--connectors-v2--
#connector-amazondynamodb
connector-assert
#connector-cassandra
connector-cdc-mysql
connector-cdc-mongodb
#connector-cdc-sqlserver
connector-cdc-postgres
#connector-cdc-oracle
#connector-cdc-tidb
connector-clickhouse
connector-datahub
connector-dingtalk
#connector-doris
connector-elasticsearch
connector-email
connector-file-ftp
connector-file-hadoop
connector-file-local
connector-file-oss
connector-file-jindo-oss
#connector-file-s3
connector-file-sftp
connector-file-obs
#connector-google-sheets
#connector-google-firestore
connector-hive
connector-http-base
connector-http-feishu
connector-http-gitlab
connector-http-github
connector-http-jira
connector-http-klaviyo
connector-http-lemlist
connector-http-myhours
connector-http-notion
connector-http-onesignal
connector-http-wechat
connector-hudi
connector-iceberg
connector-influxdb
connector-iotdb
connector-jdbc
connector-kafka
connector-kudu
#connector-maxcompute
connector-mongodb
connector-neo4j
#connector-openmldb
#connector-pulsar
connector-rabbitmq
connector-redis
connector-druid
#connector-s3-redshift
#connector-sentry
#connector-slack
connector-socket
#connector-starrocks
#connector-tablestore
#connector-selectdb-cloud
connector-hbase
#connector-amazonsqs
#connector-easysearch
#connector-paimon
#connector-rocketmq
#connector-tdengine
connector-web3j
#connector-milvus
#connector-activemq
#connector-sls
#connector-qdrant
#connector-typesense
#connector-cdc-opengauss
连接器下载到/usr/local/soft/apache-seatunnel-2.3.8/connectors/,可以单独保存,以后安装就不用再下载

上述内容也可以直接上传,地址如下
链接: https://pan.baidu.com/s/1Q4lTMtiBWlP5-3epmCC6jw?pwd=ejkx 提取码: ejkx
3.2.1.3、测试
cd /usr/local/soft/apache-seatunnel-2.3.8/
./bin/seatunnel.sh --config ./config/v2.batch.config.template -m local
3.2.1.4、启动服务
用于web端连接
cd /usr/local/soft/apache-seatunnel-2.3.8/bin/
nohup sh seatunnel-cluster.sh 2>&1 &
3.2.2、 SeaTunnel-Web部署与使用
3.2.2.1、下载解压
cd /usr/local/soft/
mkdir apache-seatunnel-2.3.8-web
tar -zxvf apache-linkis-1.6.0-web-bin.tar.gz -C apache-seatunnel-2.3.8-web
3.2.2.2、 安装运行
cd /usr/local/soft/apache-seatunnel-2.3.8-web/
sh install.sh

3.2.2.3、浏览器验证
浏览器输入:http://node11:8088/

其它参考:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











