



 文章详细介绍了Python中数据抽取在数据分析中的关键操作,包括使用loc和iloc属性抽取单行、多行、指定列和指定条件的数据。重点展示了如何通过这些工具从不同数据源提取所需数据进行后续分析。
文章详细介绍了Python中数据抽取在数据分析中的关键操作,包括使用loc和iloc属性抽取单行、多行、指定列和指定条件的数据。重点展示了如何通过这些工具从不同数据源提取所需数据进行后续分析。
数据抽取在数据分析中扮演着重要的角色
目录
为什么要进行数据抽取:
数据抽取是从各种数据源中获取数据的过程。在数据分析中,数据的质量和准确性对于得出准确的结论和洞察至关重要。通过数据抽取,可以从不同的数据源(如数据库、日志文件、API等)中提取所需的数据,以便进行后续的分析。
前言
在数据分析过程中,并不是所有的数据都是我们想要的,此时可以抽取部分数据,主要使用DataFrame对象的loc属性。
loc 属性:以列名(columns)和行名(index)作参数,当只有一个参数时,默认是行名,
即抽取整行数据,包括所有列,如 df.loc[A]。
已 iloc 属性:以行和列位置索引(即0,1,2,⋯)作参数,0表示第1行,1表示第2行,以此类推。当只有一个参数时,默认是行索引,即抽取整行数据,包括所有列。如抽取第1行数据,df.iloc[O]。
1.1抽取一行数据
抽取一行数据主要使用loc属性。
实例1:抽取一行考试成绩数据
程序代码如图所示:
import pandas as pd
data = [[1 10, 105,99],[105,88, 115],[109, 120, 130],[112,115]]
name =['明日','七月流火','高袁圆','二月二'〕
columns =['语文','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
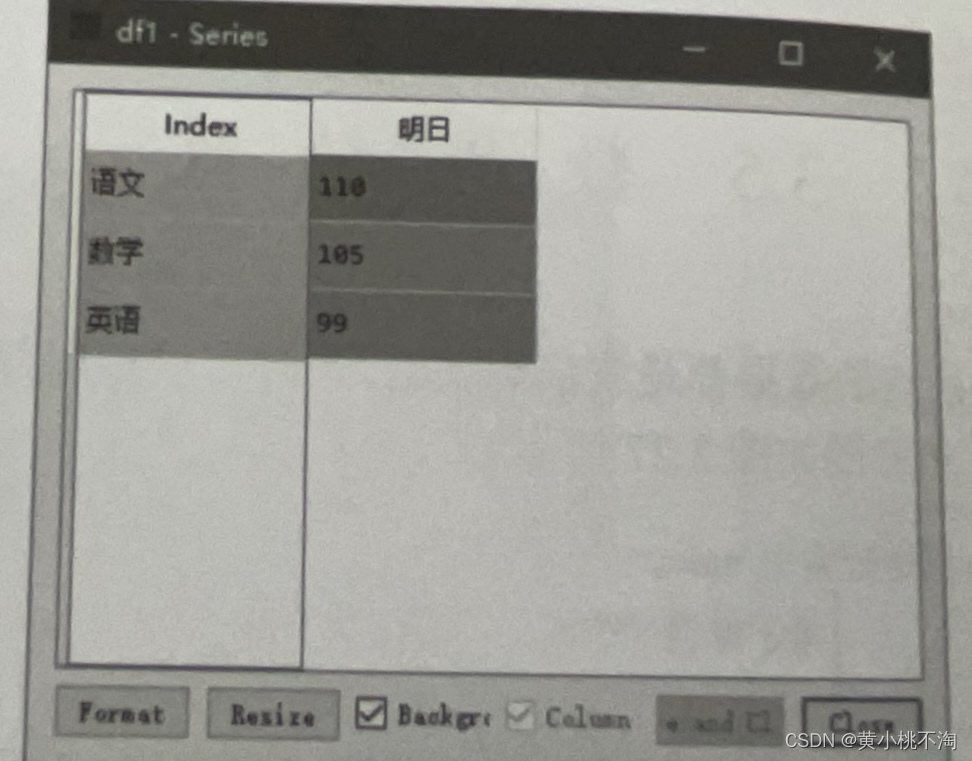
df1=df.loc['明日']运行程序,输出结果如下图
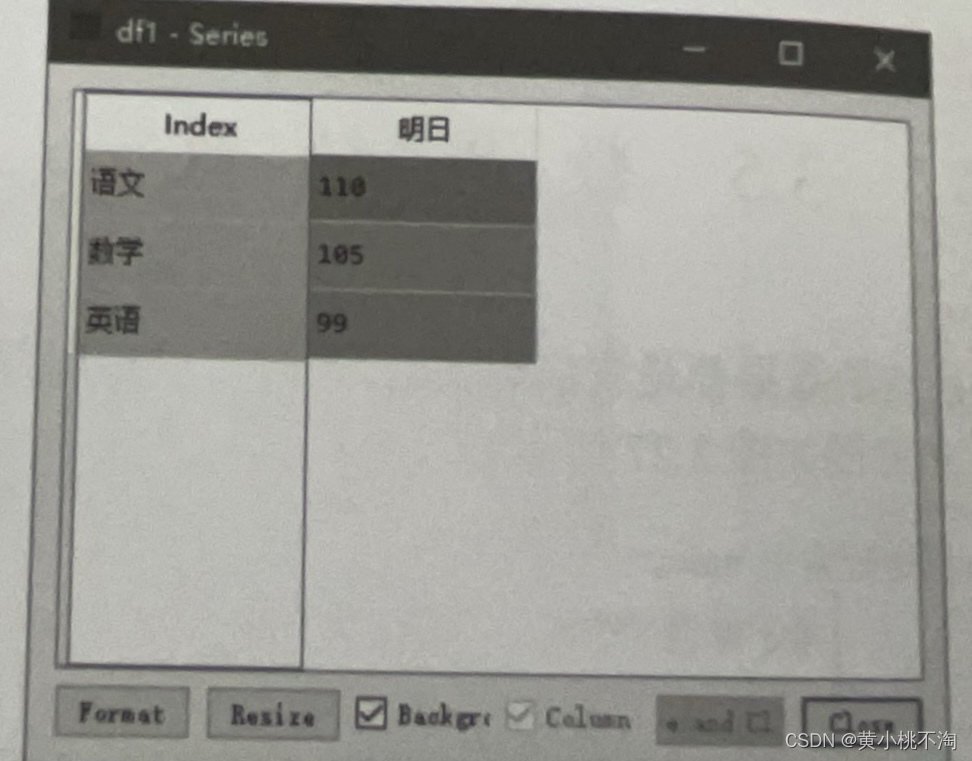
1.2抽取多行数据
1.2.1抽取任意多行数据
通过loc属性和iloc属性指定行名和索引即可实现抽取任意多行数据。
实例2:抽取多行考试成绩数据
主要代码如下:
df1=df.loc[['明日','高圆圆']]
df1=df.iloc[[0,2]]运行程序,输出结果如下图
1.2.2抽取连续多行数据
在loc属性和iloc属性中合理地使用冒号(:),即可抽取连续任意多行数据。
实例3:抽取连续任意几个学生的考试成绩。
主要代码如下:
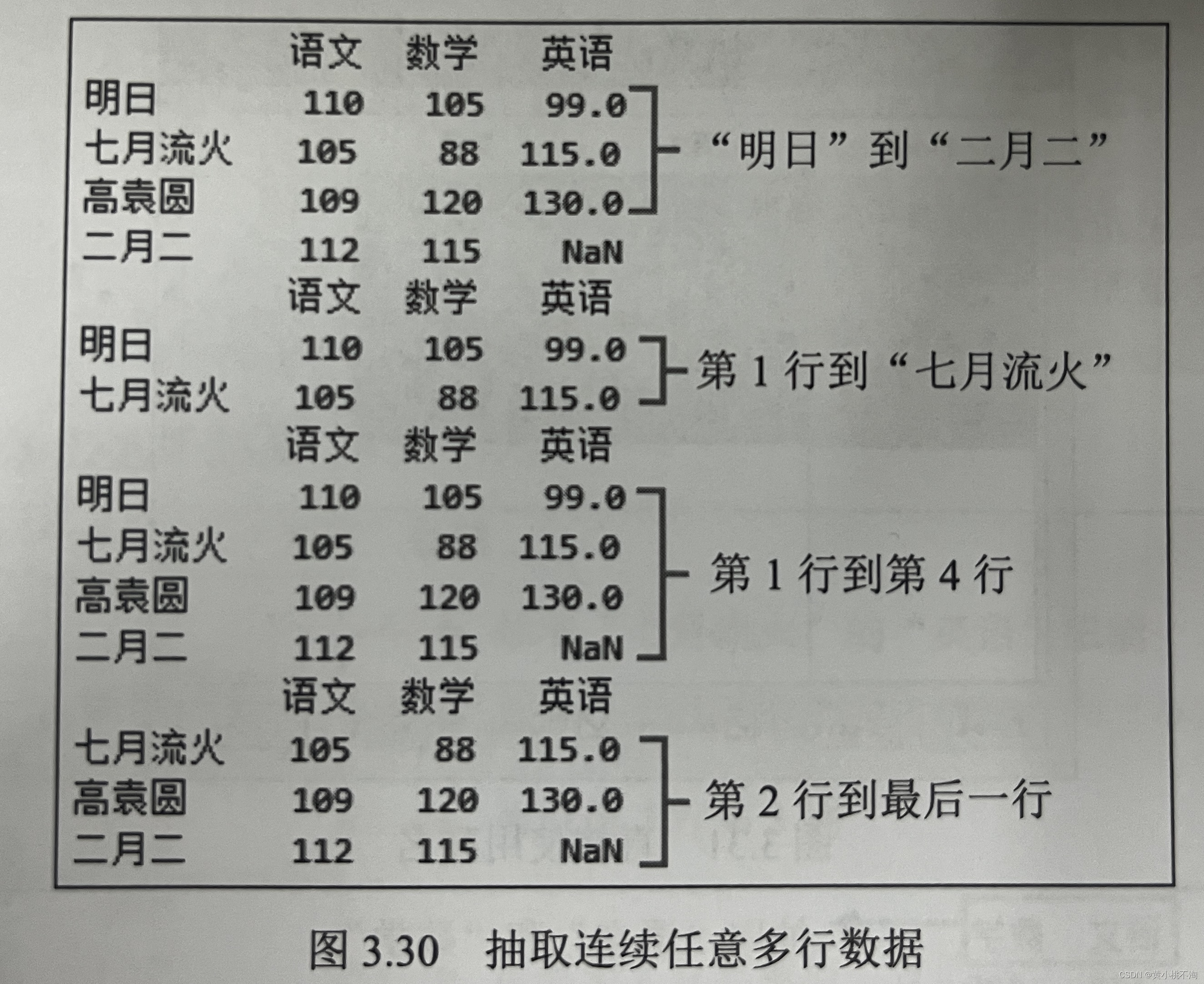
print(df.loc['明日','二月二']) #从“明日”到“二月二”
print(df.loc[:'七月流火:']) #从第一行到“七月流火”
print(df.loc[0:4]) #从第一行到第四行
print(df.loc[1::]) #从第二行到最后一行运行程序结果如下图:
1.3抽取指定列数据
抽取指定数据,可以直接使用列名,也可以使用loc属性和iloc属性
1.3.1直接使用列名
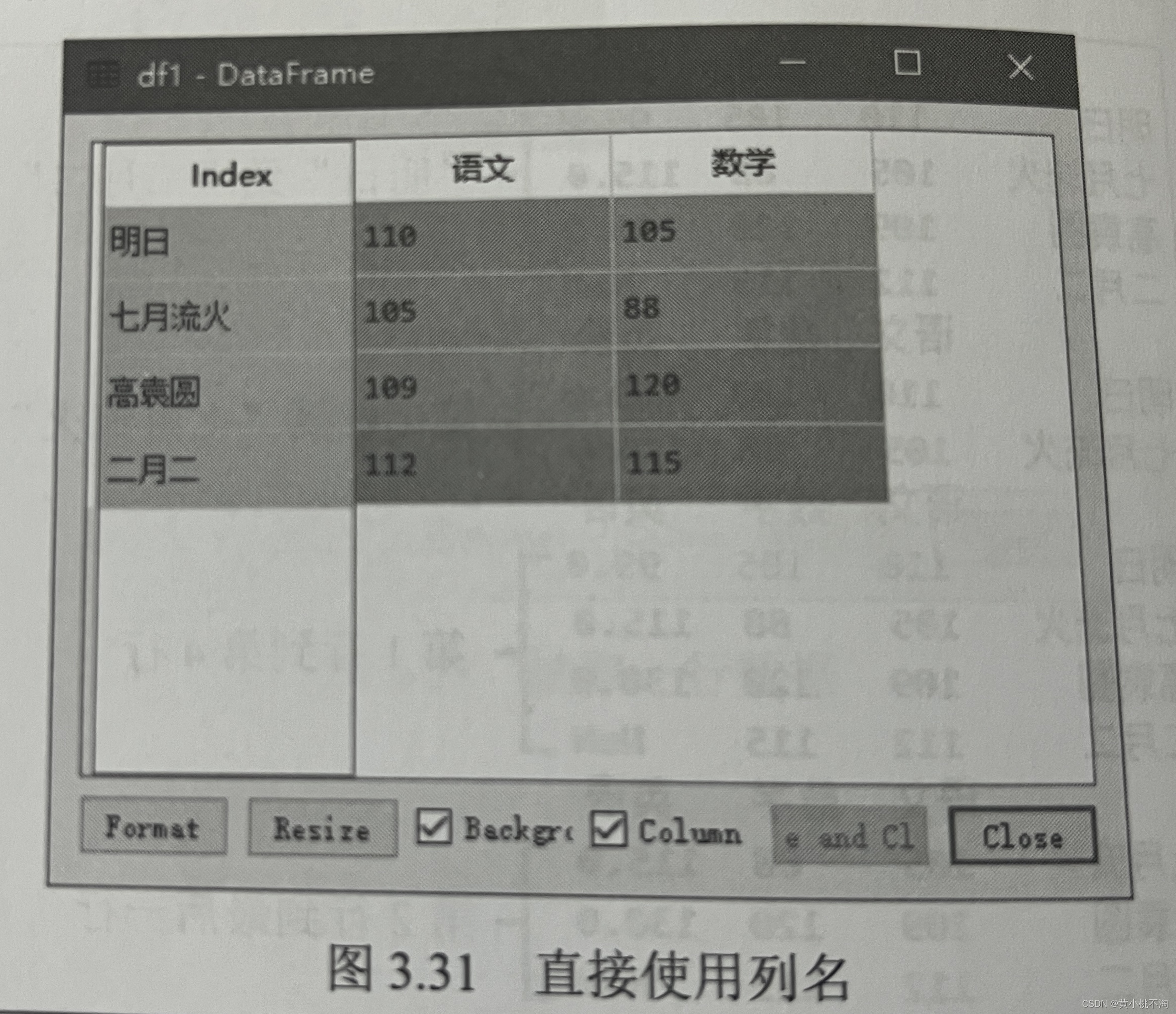
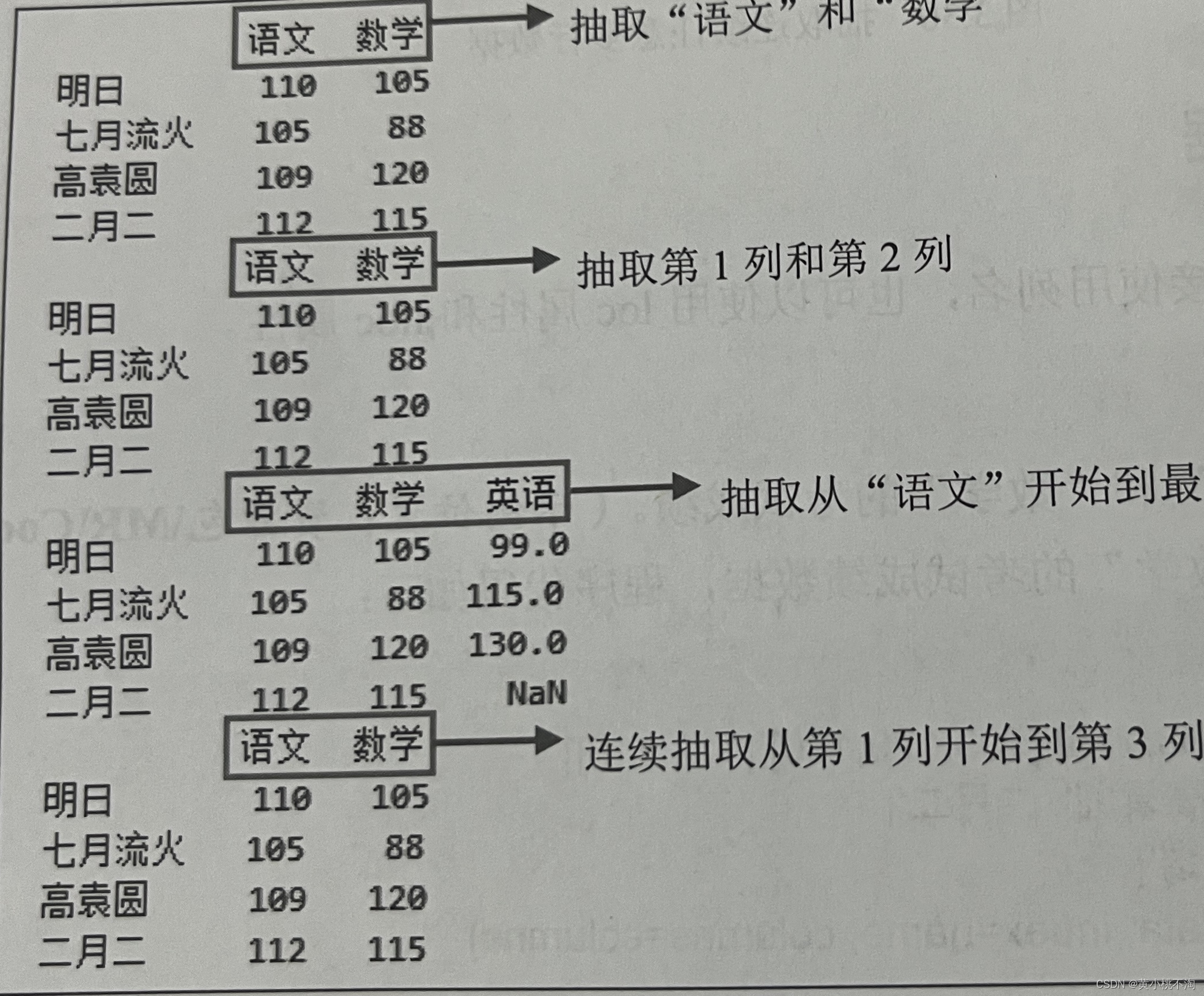
实例4:抽取“语文”和“数学”的考试成绩
程序代码如下:
import pandas as pd
data = [[110, 105,99],[105,88,115],[109,120, 130],[112,115]]
name =[明日,七月流火,高袁圆,二月二]columns =[语文,数学,英语]
df = pd.DataFrame(data=data, index=name, columns=columns)
df1=df[语文,数学1]运行程序如下图:
1.3.2使用loc属性和iloc属性
前面介绍loc属性和 iloc属性均有两个参数:第一个参数代表行;第二个参数代表列。那么这里抽取指定列数据时,行参数不能省略。
实例5:抽取指定学科的考试成绩
主要代码如下:
print(df.locf:['语文','数学'])
print(df.iloc[:,[0,1]])
print(df.loct,['语文'])
print(df.iloc[:,:2])运行程序如图下
在上述结果中,第一个输出结果是一个数,不是数据,是由于“df.loc['七月流火','英语']”没有使用方括号[],导致输出的数据不是DataFrame类型。
1.4抽取指定行、列数据
抽取指定行、列数据主要使用loc属性和iloc属性,这两个方法的两个参数都可以指定就可以实现指定行、列数据的抽取。
实例6:抽取指定学科和指定学生的考试成绩
程序代码如下:
import pandas as pd
data = [[110,105,99],[105,88, 1151,[109,120,130],[112,115]]
name=['明日','七月流火','高袁圆','二月二']
1columns =['语文 ','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
print(df.loc['七月流火','英语'])
print(df.loc[['七月流火'],[‘英语’])
print(df.loc[['七月流火'],['数学','英语'])
print(df.iloc[[1],[2]])
print(df.iloc[1:,[2]])
print(df.iloc[1:,[0,2]])
print(df.iloc[:,2])运行程序如下图:

1.5按指定条件抽取数
据DataFrame 对象实现数据查询有以下3种方式。
(1)取其中的一个元素.iat[x,x]。
(2)基于位置的查询,如.ilocl、iloc[2,1]。
(3)基于行、列名称的查询,如.loc[x]。
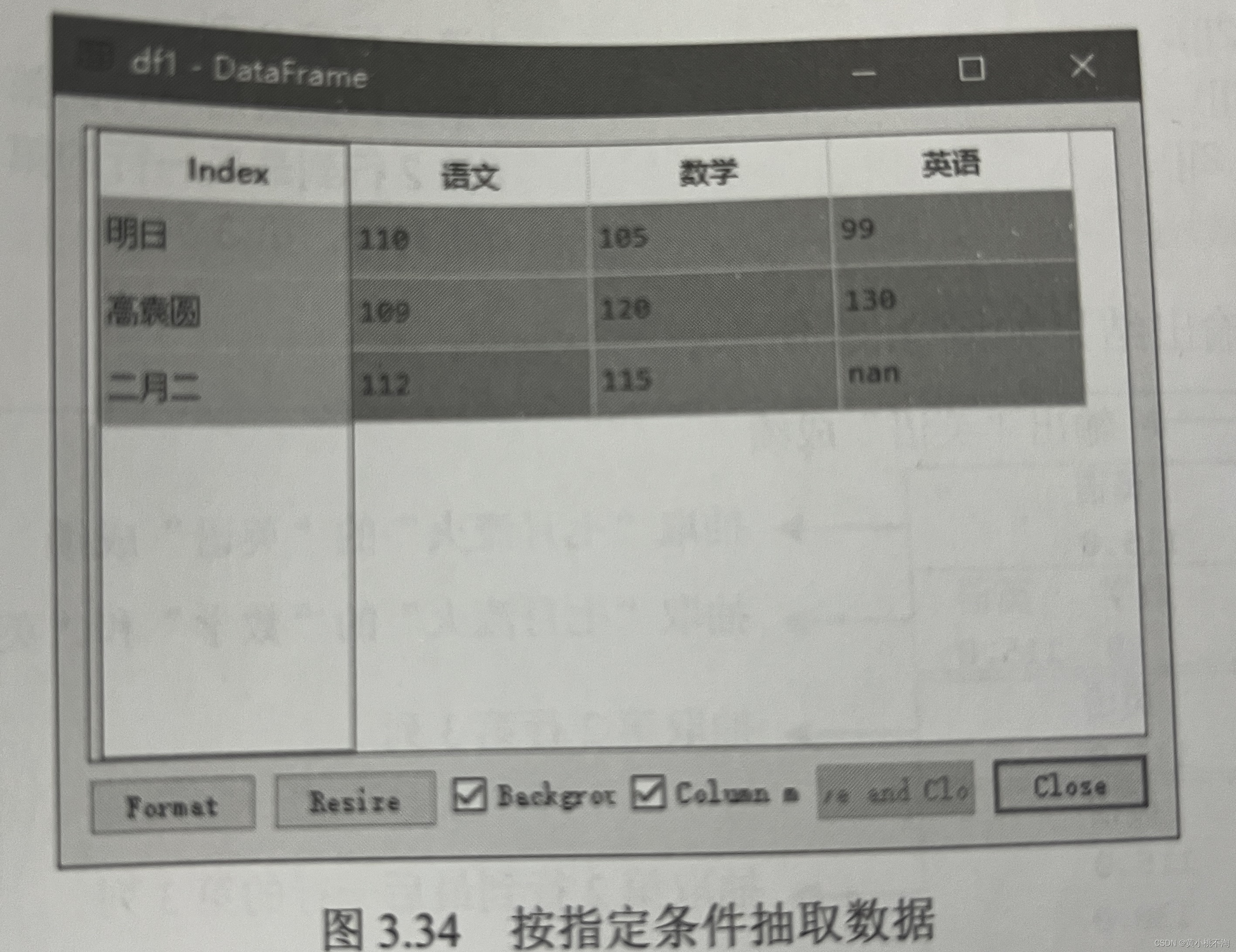
实例7:抽取指定学科和指定分数的数据。
程序代码如下:
import pandas as pd
data=[[110,105,99],[105,88,115],[109,120,130],[112,115]]
name =['明日','七月流火','高袁圆','二月二']
columns =['语文','数学','英语']
df = pd.DataFrame(data=data, index=name, columns=columns)
df1=df.loc[(df['语文']>105)&(df['数学']>88)]运行程序结果如下
总结:
在写这个文章的过程中,遇到了很多的困难,要编写代码和代码运行是否成功,还好有老师、同学的指导,自己的探索,慢慢的解决了问题。对任务的结果不是很满意,主要是制作时用了很多时间,没有效率,走了很多弯路,没有做好计划,希望这篇文章能够帮助到更多的同学。
总之,还要努力呀!
本文文章链接:python数据分析-数据抽取-优快云博客

















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









