




目录
一、引言
在机器学习和数据科学的领域中,支持向量机(Support Vector Machine, SVM)是一种广泛使用的分类算法。其独特的原理和强大的性能使得SVM在诸多领域中都有出色的表现。然而,对于初学者而言,SVM的复杂性和抽象性往往让人难以捉摸。本文将通过数据可视化的方式,深入浅出地解析SVM的工作原理和应用,帮助读者更好地理解并掌握这一强大的分类工具。
二、支持向量机的基本原理
SVM的核心思想是通过找到一个决策超平面,将不同类别的数据分隔开来。这个决策超平面不仅要能将数据分开,还要使得数据点到超平面的距离最大化,即所谓的“最大间隔”。这样,SVM就能够对新的数据点进行准确的分类。
在二维空间中,这个决策超平面就是一条直线;在三维空间中,它是一个平面;而在更高维度的空间中,则是一个超平面。为了找到这个最优的超平面,SVM引入了“支持向量”的概念。支持向量是那些距离决策超平面最近的数据点,它们决定了超平面的位置和方向。
三、数据可视化在SVM中的应用
数据可视化是一种强大的工具,它可以帮助我们直观地理解SVM的工作原理。通过绘制数据点和决策超平面的图形,我们可以清晰地看到SVM是如何将数据分开的。
四、SVM的数据可视化绘图方法
1.sin正弦函数绘制
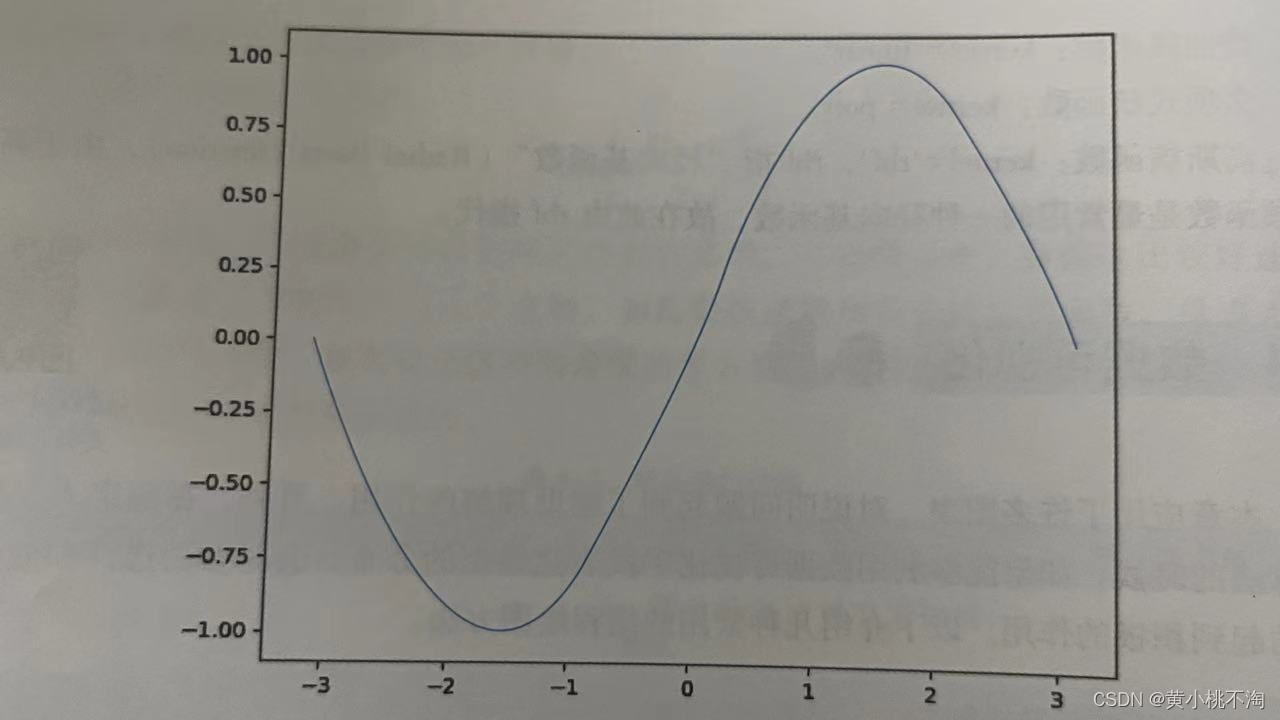
这里采用Matplotlib模块来对数据可视化,用pip install matplotlib 命令安装该模块,先绘制一个sin函数图形。
from pylab import *
import numpy as np
X = np. Linspace(-np. pi, np. pi, 256,endpoint=True)
S = np. sin(X)
#产生绘图数据X,S,为x轴和y轴一一对应的数据
plot ( X,S)
#以默认的形式绘制数据,plot 第1个参数为x轴坐标数据,第2个参数为y轴坐标数据
show ( )运行结果如图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









