







使用spleeter分割后的人声与背景音乐分别存储在很多文件夹中。 文件结构大概是这样:
有许多这样的文件夹存储分离的人声与背景音乐。其中人声的音频文件名为vocals.wav。
因此,遍历所有文件夹,判断文件名是否为vocals.wav,并将其复制到另一个文件夹中,将该音频文件重命名为其所在的文件夹名加上vocals.wav。
import os
import shutil
from pydub import AudioSegment
from pydub.silence import detect_nonsilent
def collect_and_rename_vocals(src_root, dst_folder):
"""
收集并重命名所有文件夹中的“vocals”音频文件。
:param src_root: 源文件夹根目录
:param dst_folder: 目标文件夹,用于存放收集的音频文件
"""
if not os.path.exists(dst_folder):
os.makedirs(dst_folder)
for root, dirs, files in os.walk(src_root):
for file in files:
print(file)
if file == "vocals.wav":
folder_name = os.path.basename(root)
new_file_name = f"{folder_name}_vocals.wav" # 假设是.wav格式
src_file_path = os.path.join(root, file)
dst_file_path = os.path.join(dst_folder, new_file_name)
shutil.copy(src_file_path, dst_file_path)
print(f"Copied and renamed: {src_file_path} to {dst_file_path}")考虑到去除背景音乐之后一般歌曲的头尾人声都比较少,甚至是完全没有声音的。因此这部分音频可以删除。避免影响训练效果。 且训练模型时,音频文件长度应该在10-20s左右,音频文件太大会导致显存压力太大。
因此,需要在此对音频文件进行分割并且删除人声较少的部分。
具体代码如下:
def split_and_clean_audio_files(directory, segment_length=15000, silence_threshold=-50.0, min_silence_len=1000, min_sound_duration=5000):
"""
将音频文件分割成指定长度的片段,并删除声音时长小于指定值的片段。
:param directory: 音频文件所在目录
:param segment_length: 分割片段的长度(毫秒)
:param silence_threshold: 静音的分贝阈值
:param min_silence_len: 识别为静音的最小时长(毫秒)
:param min_sound_duration: 保留的最小声音时长(毫秒)
"""
for filename in os.listdir(directory):
if filename.endswith(".wav"): # 根据实际音频文件格式调整
file_path = os.path.join(directory, filename)
audio = AudioSegment.from_file(file_path)
# 分割音频文件
for i in range(0, len(audio), segment_length):
segment = audio[i:i + segment_length]
segment_file_path = os.path.join(directory, f"{os.path.splitext(filename)[0]}_part{i//segment_length}.wav")
segment.export(segment_file_path, format="wav")
# 检测非静音部分
nonsilent_ranges = detect_nonsilent(segment, min_silence_len=min_silence_len, silence_thresh=silence_threshold)
total_sound_duration = sum(end - start for start, end in nonsilent_ranges)
# 如果非静音部分总时长小于最小声音时长,删除文件
if total_sound_duration < min_sound_duration:
os.remove(segment_file_path)
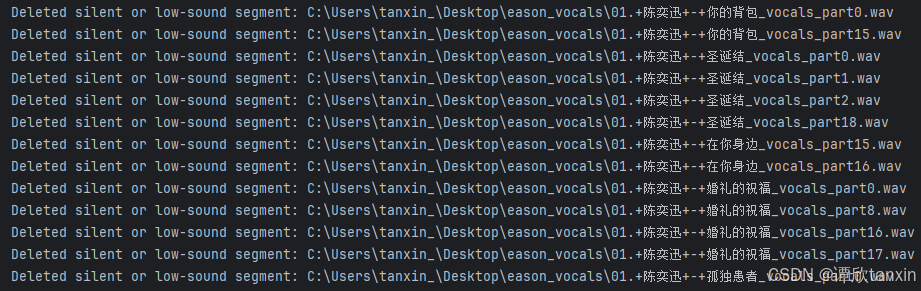
print(f"Deleted silent or low-sound segment: {segment_file_path}")运行结果:

















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









