






这是使用的是github上一个开源的音频转换的模型。有兴趣的可以自行去搜索下载。
我所用的电脑显卡算力不足,因此我选择了一个算力云服务平台。大家可以根据需要自行选择是在本地训练还是云端租卡训练。
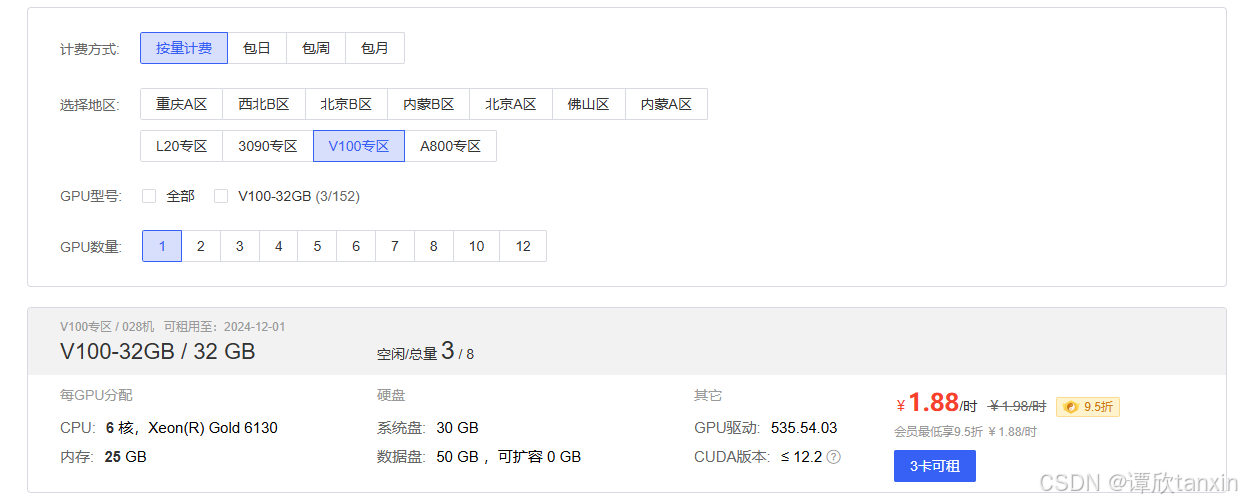
选择一个v100。
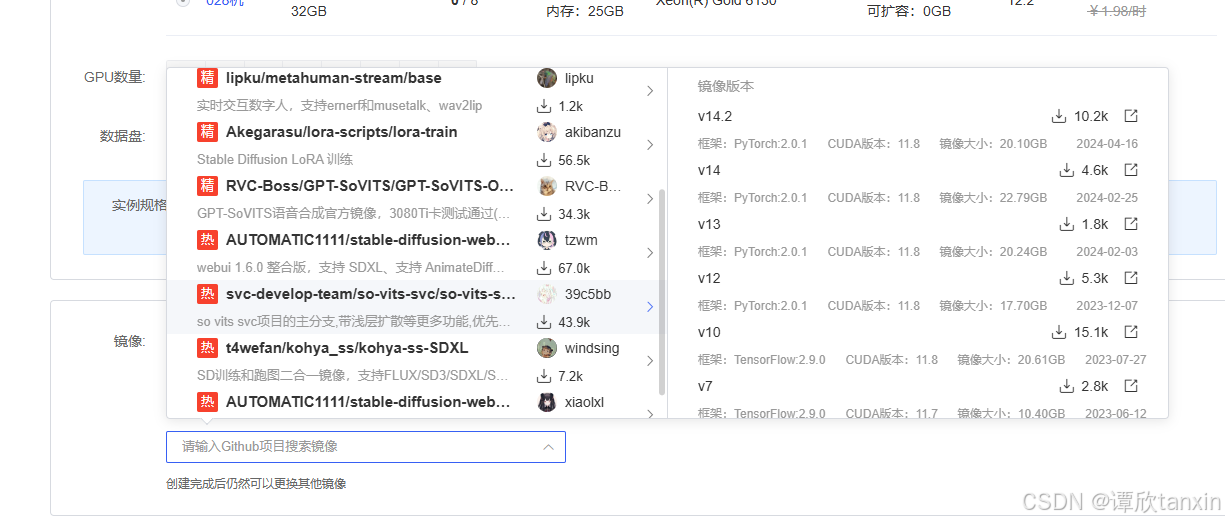
在云平台上可以选择社区镜像,这里直接可以选择我们所需要的项目。优先选择最新版本的。
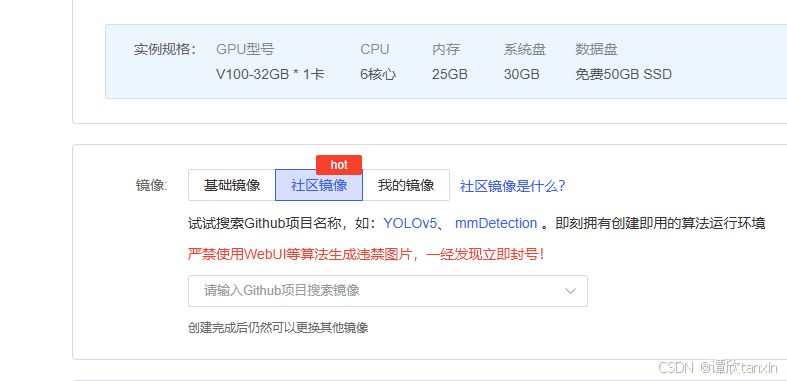
选择好社区镜像之后,创建即可。首次创建时间会长一些。
创建成功之后,点击进入jupyter(见下面第一张图),如果想看一下详情,可以把这个“请先看我”的记事本看完,也可以选择文档快速开始。

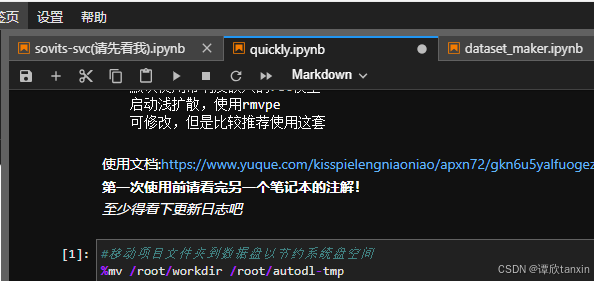
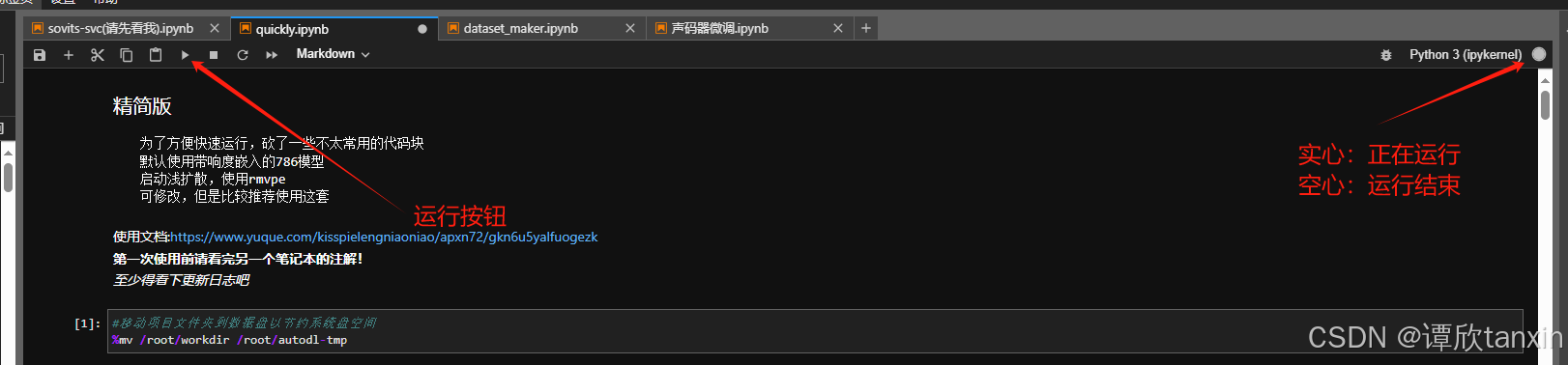
进入quickly记事本后,点击第一个代码块:#移动项目文件夹到数据盘以节约系统盘空间。然后点击上方的三角图标,运行代码块。
在 autodl-tmp/so-vits-svc/dataset_raw这个路径下创建文件夹,将之前处理好的音频文件直接拖到这个界面中上传。
随后,逐个运行预处理的代码块就好。
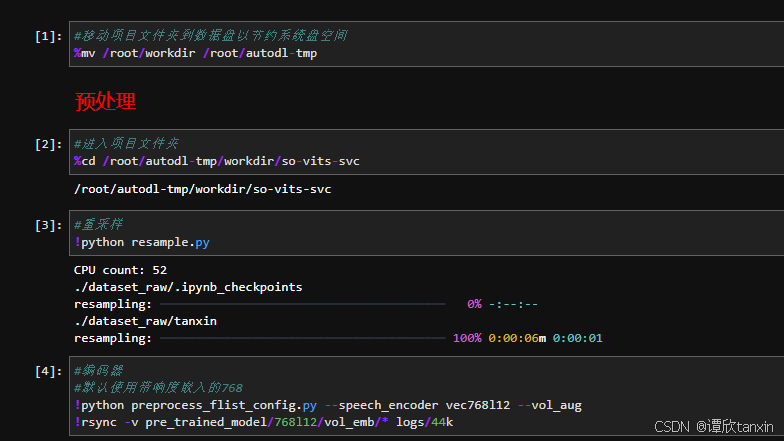
预处理最后一步稍微会久一些。随后就可以开始训练了,在训练这部分有两个,一个浅扩散模型,一个主模型。主模型是核心,需要先训练;浅扩散模型属于扩展模型,能增强效果,但是会削弱音色。

















 2478
2478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









