




 本文深入解析了AdaBoost算法,一种基于向分步算法和加法模型的经典二分类问题解决方案。文章详细介绍了算法的思想、过程及小结,强调了样本权重更新机制和模型优化的重要性。
本文深入解析了AdaBoost算法,一种基于向分步算法和加法模型的经典二分类问题解决方案。文章详细介绍了算法的思想、过程及小结,强调了样本权重更新机制和模型优化的重要性。
1.AdaBoost的简述
AdaBoost是以向分步算法和加法模型为基础的,经典的AdaBoost是解决二分类问题的并且也以此来进行说明。
ps:基分类器可以是任意的!
算法思想:就是在训练第m个分类器时,根据第m-1个分类器分类的情况来更新第m个分类器的样本权重分布。
ps:当样本被分错增大权值,当样本被分对减小权值,而分类器的权重是根据该分类器的表现也就是重要性。
ps:第m个分类器的样本权重分布是根据,第m-1个模型的错误率、权值分布来决定的!
2.算法的过程分析
首先会初始化权值!
模型:(使用具有权值分布Dm的训练数据集学习,得到基本分类器Gm)
![]() ,
,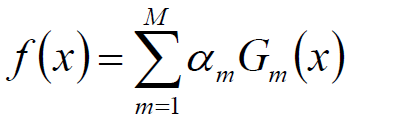
首先定义错误率:
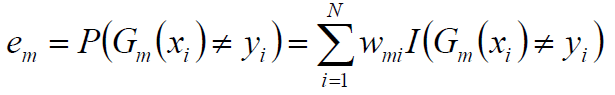
Gm代表第m个分类器,xi为样本输入值,yi为实际值,N代表样本数,I函数是式子为true返回1否则返回0
Wmi是样本的权重!!这里要注意所有样本的权重和是1,这里更新的时候进行了归一化。
计算第m个分类器的系数:
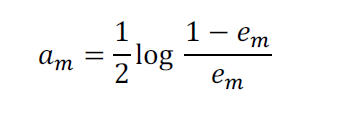
样本权值的更新:
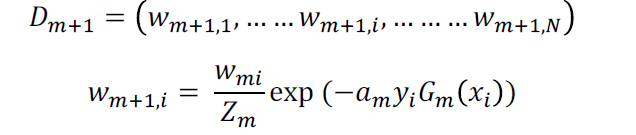
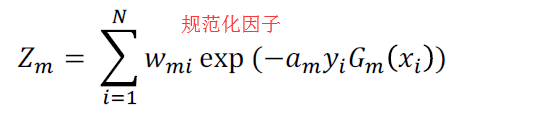
注意公式:
ps:如果样本多次被分错,那么权重真的会越来越大!还是基于乘法的!
最终模型:
重复M次,构建出最终的分类器模型!

----------------------------------------------------------------------------------------------------------------------------------------------------------------
定义优化函数(损失函数):(求解模型)
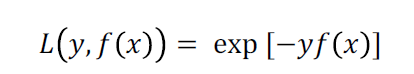
ps:损失函数是指数损失函数。
m个分类器组成的模型:
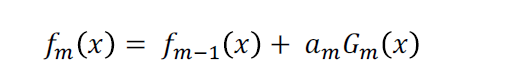
从上式:最小化目标损失函数(指数损失函数):
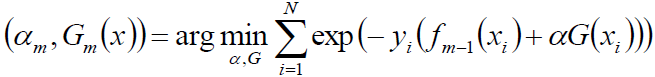
化简成:
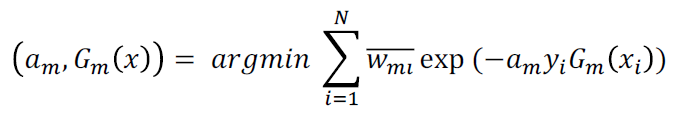
求出第m个模型:
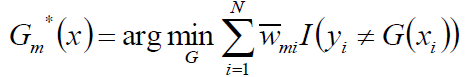
求解?∗:
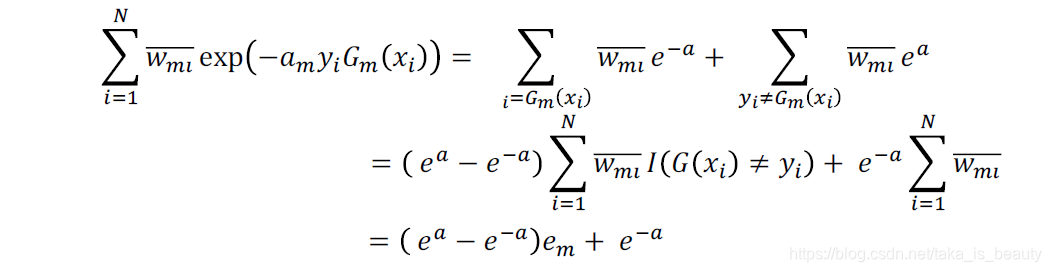
对上式求导得到:
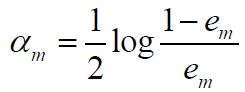
注意误差率公式:
3.算法小结
我们通过前向分步算法,加法模型,在优化指数误差函数推导出了AdaBoost。
Bagging和Boosting:分别对应模型的方差(预测值与预测值期望的偏离程度)和偏差(预测值的期望与真实值之间的偏离程度)
ps:误差可以分解为:方差,偏差,噪声。
ps:Bagging的随机取样方法可以减少方差,对于投票或者取平均对基分类器进行集成。
ps:Boosting通过迭代进行分类器的优化可以减少偏差。

















 2350
2350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









