




 文章详细探讨了UDF(用户自定义函数)的工作原理,指出UDF在Map阶段执行,通过示例解释了UDAF(用户定义聚合函数)如何在Map和Reduce两端执行,涉及局部聚合优化。此外,还简要提到了UDTF(用户定义表生成函数)的作用和执行阶段。
文章详细探讨了UDF(用户自定义函数)的工作原理,指出UDF在Map阶段执行,通过示例解释了UDAF(用户定义聚合函数)如何在Map和Reduce两端执行,涉及局部聚合优化。此外,还简要提到了UDTF(用户定义表生成函数)的作用和执行阶段。
1.4.12、三者区别
1.4.12.1、UDF
UDF全称为User Defined Function(即用户自定义函数),UDF开发在日常工作当中是非常普遍的。我们写一段SQL,调用UDF,得到结果就算是结束了,但大家有没有想过UDF底层是怎么执行的呢?那么我们拿MR引擎为例,那UDF是在Map端执行还是在Reduce端执行的呢?说实话,我之前没想过。
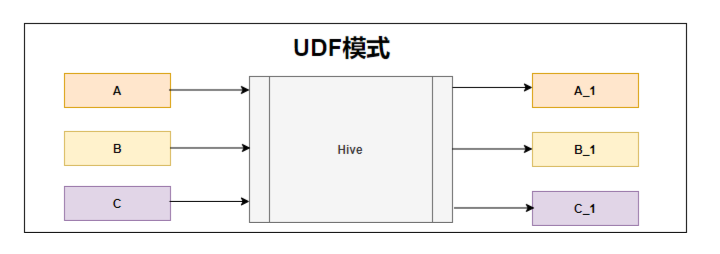
既然没想过,那今天就来想一想。首先抛开在哪端执行不说,那我们知道UDF的模式是我们给一个值,然后再返回一个值。如上图所示,传一个A,返回给一个A_1;传一个B,返回给一个B_1;传一个C返回给一个C_1;
这种模式就相当于在传入的一个值上进行了一些修饰后再返回给我们,相当于是一对一的模式。梳理到这里,答案也比较清晰了,这不就是map功能吗。有些同学可能会质疑,没关系,我们explain一下就知道了。
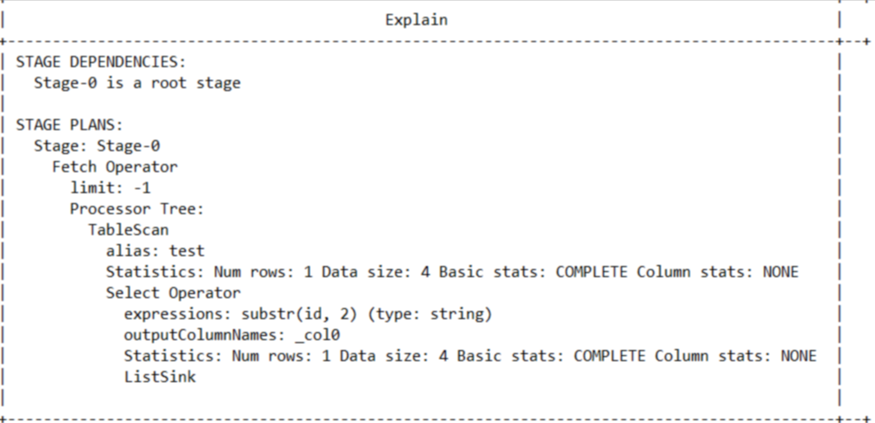
如上图所示,只有一个fetch Operator,当然这个demo比较简单,不会走MR的。从这里也可以看出来这就是一个转换功能,但有些同学仍有疑惑,没关系,让我们来一个走MR的例子。
explain select substr(id,2),count(1) from test group by substr(id,2);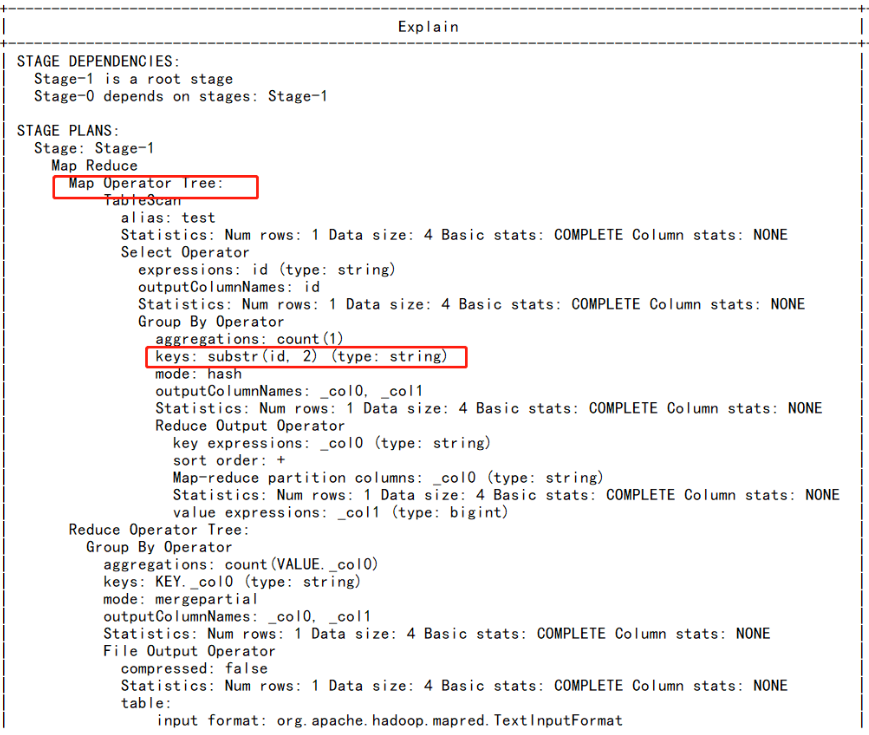
到这里总能证明UDF函数是在Map阶段执行的吧!
1.4.12.2、UDF编写
对于如何开发UDF,网上模板一大堆,这里不再叙述。下面出一个关于year函数的内部实现,供大家参考
public class UDFYear extends UDF {
private final SimpleDateFormat formatter = new SimpleDateFormat("yyyy-IM-dd");
private final Calendar calendar = Calendar.getInstance();
private final IntWritable result = new Intwritable();
public UDFYear() {}
public Intwritable evaluate(Text datestring) {
if (dateString == null) return null;
try {
Date date = formatter.parse(datestring.tostring());
calendar.setTime(date);
result.set(calendar.get(Calendar.YEAR));
return result;
} catch (ParseException e) {
return null;
}
}
public IntWritable evaluate(Datewritable d) {
if (d == null) {
return null;
}
calendar.setTime(d.get());
result.set(calendar.get(Calendar.YEAR));
return result;
}
public IntWritable evaluate(Timestampwritable t) {
if (t == null) {
return null;
}
calendar.setTime(t.getTimestamp());
result.set(calendar.get(Calendar.YEAR));
return result;
}
}1.4.12.3、UDAF
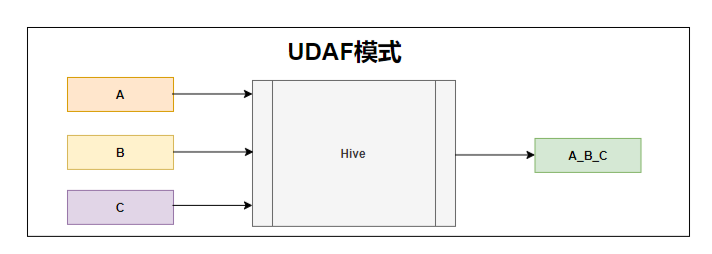
UDAF全称为User-defined Aggregation Function,从命名来看,这是一种聚合函数,比如像我们常用的sum、max。如下图所示,可以抽象的理解成传入多个值,最后返回给我们一个值。那么对于该类型的函数是不是一定在reduce端执行了,为什么这么说呢?你看sum函数是不是会发生shuffle,是不是在reduce端做全局聚合呢(如果你这样想也没问题,但也有问题)
我们通过explain命令来验证一下想法。我们执行如下命令:
explain select sum(id) from test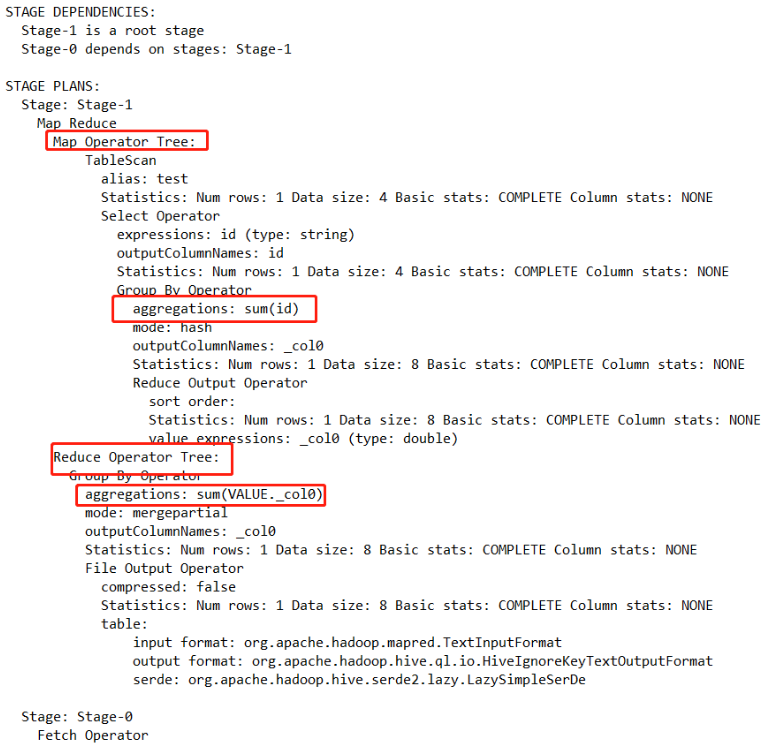
如上图所示,对于SUM类型的UDAF是在map端和reduce端都执行了,哎呦,这是怎么回事呢?我们回想一下MapReduce机制,如果我们要做全局聚合,难道要把所有的数据都拉取到reduce端吗?那reduce端压力是不是就会很大。所以有了局部聚合的这么一种优化方式。
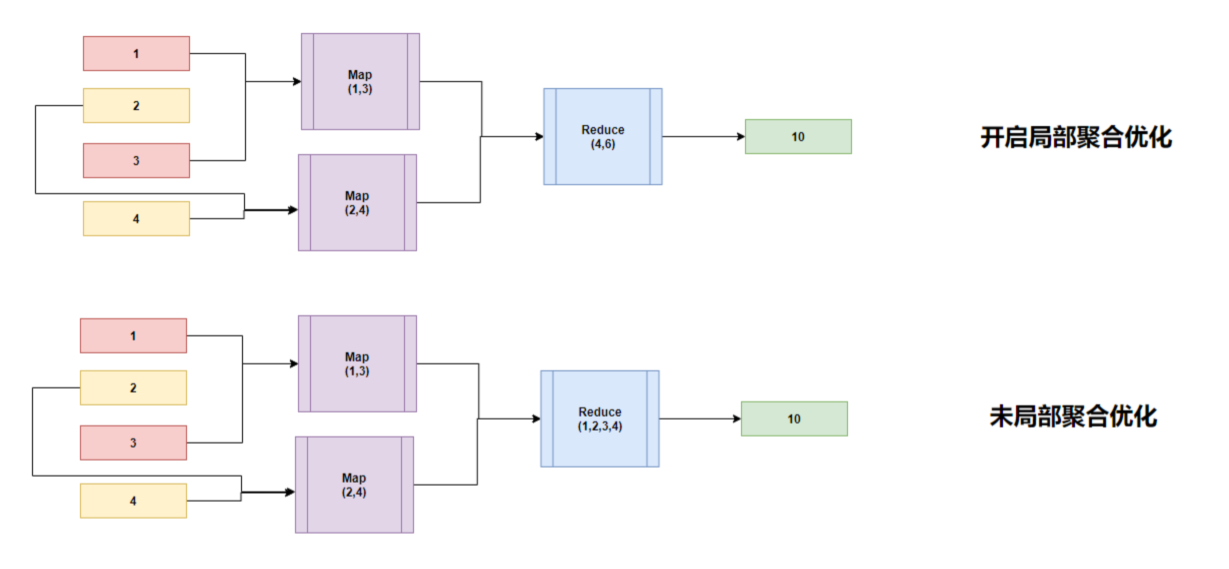
那我们把局部聚合优化阶段给关闭后,再来看一下UDAF会在那一端执行
--关闭map端聚合
set hive .map.aggr=false ;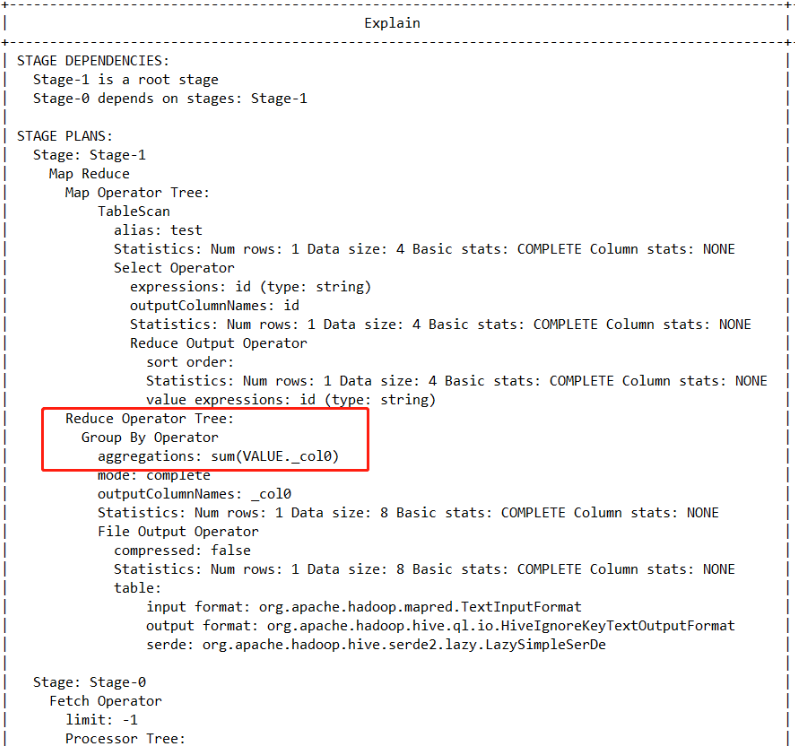
如上图所示,当我们把局部聚合优化功能给关闭后,UDAF只会在reduce执行。
1.4.12.4、UDTF
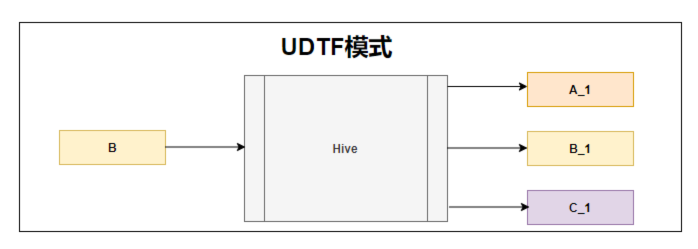
UDTF全称为User-defined Table Generating Function,该模式的功能是通过输入一行,返回多行。在实际场景中用的不多,该类型的执行阶段通常是在本地,大家也可以理解成是做map转换和UDF是一样的阶段。


















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











