




 本文围绕Flink的状态容错展开。Flink支持有状态计算,为保证计算精准一次,单机时会周期性保存数据消费位置和状态形成快照;分布式环境下,通过在数据流中插入checkpoint barrier生成全局一致快照。此外,还介绍了检查点和savepoint在程序恢复中的应用。
本文围绕Flink的状态容错展开。Flink支持有状态计算,为保证计算精准一次,单机时会周期性保存数据消费位置和状态形成快照;分布式环境下,通过在数据流中插入checkpoint barrier生成全局一致快照。此外,还介绍了检查点和savepoint在程序恢复中的应用。
状态容错 State Fault Tolerance
首先来说一说状态容错。Flink 支持有状态的计算,可以把数据流的结果一直维持在内存(或 disk)中,比如累加一个点击数,如果某一时刻计算程序挂掉了,如何保证下次重启的时候,重新恢复计算的数据可以从状态中恢复,并且每条数据只被计算了一次呢?
从数据的流入到计算流出,整个过程看成事务的话,就是如何保证整个过程具有原子性。
Flink 是怎么做的呢?只靠状态本身是远远不够的,状态只是保存了某个值,还需要保存一个计算的位置。
如果是单机的情况下,这个很好实现。
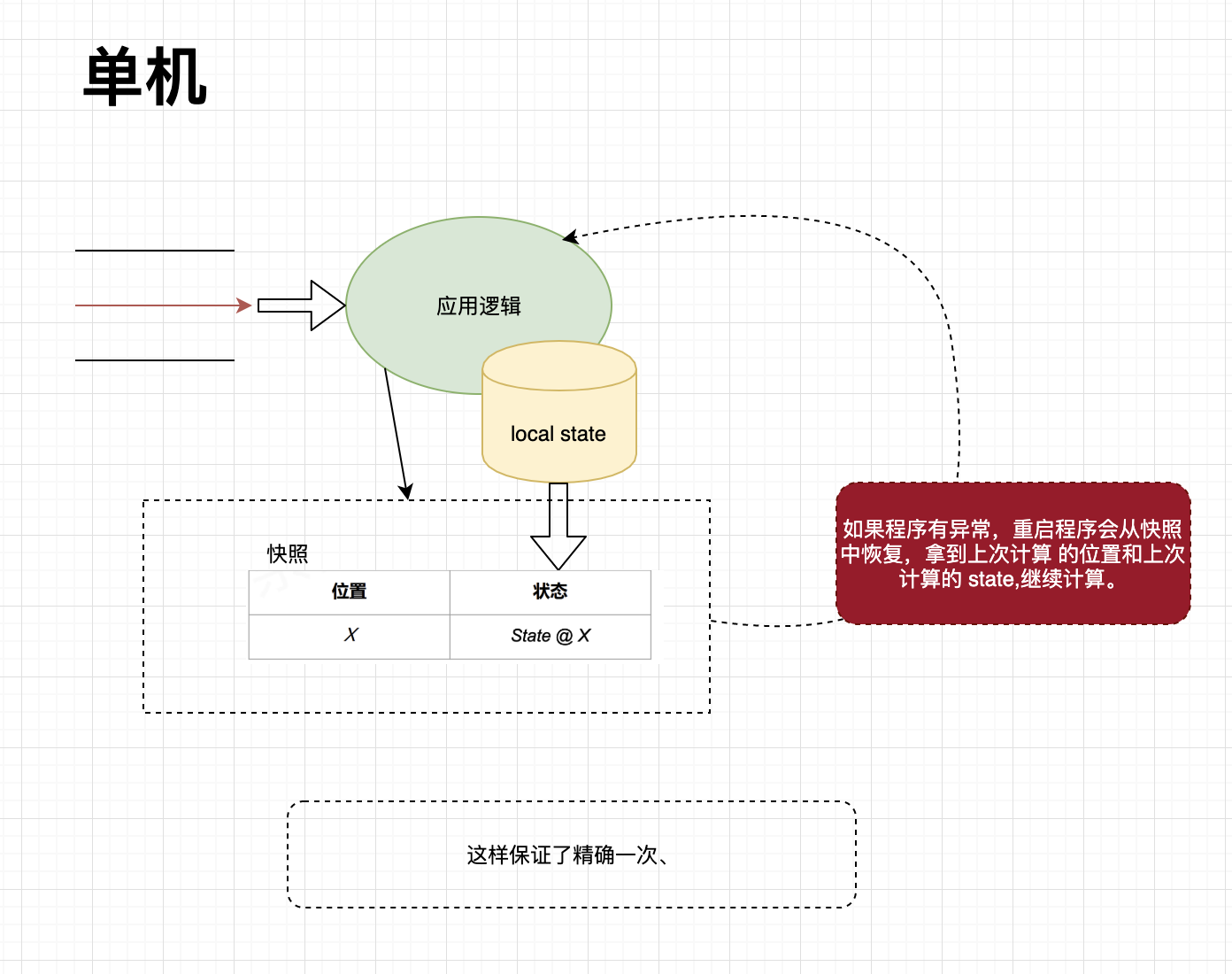
假设来自 Kafka 的数据流,经过应用逻辑的计算,生成状态保存到 state 中,这个过程是源源不断的,如图所示,为了保证state的容错性,程序会周期性的保存数据消费的位置和该时刻的状态,叫做快照,如果程序有异常需要重启的时候,就会从快照中恢复。这个过程保证了精准一次的计算,一条数据只会被计算一次。
分布式环境下没有这个简单,众所周知,任何问题到了分布式环境下,就变得复杂。
Flink 是如何做到状态分布式容错的呢?如何在不中断计算的情况下产生快照呢?
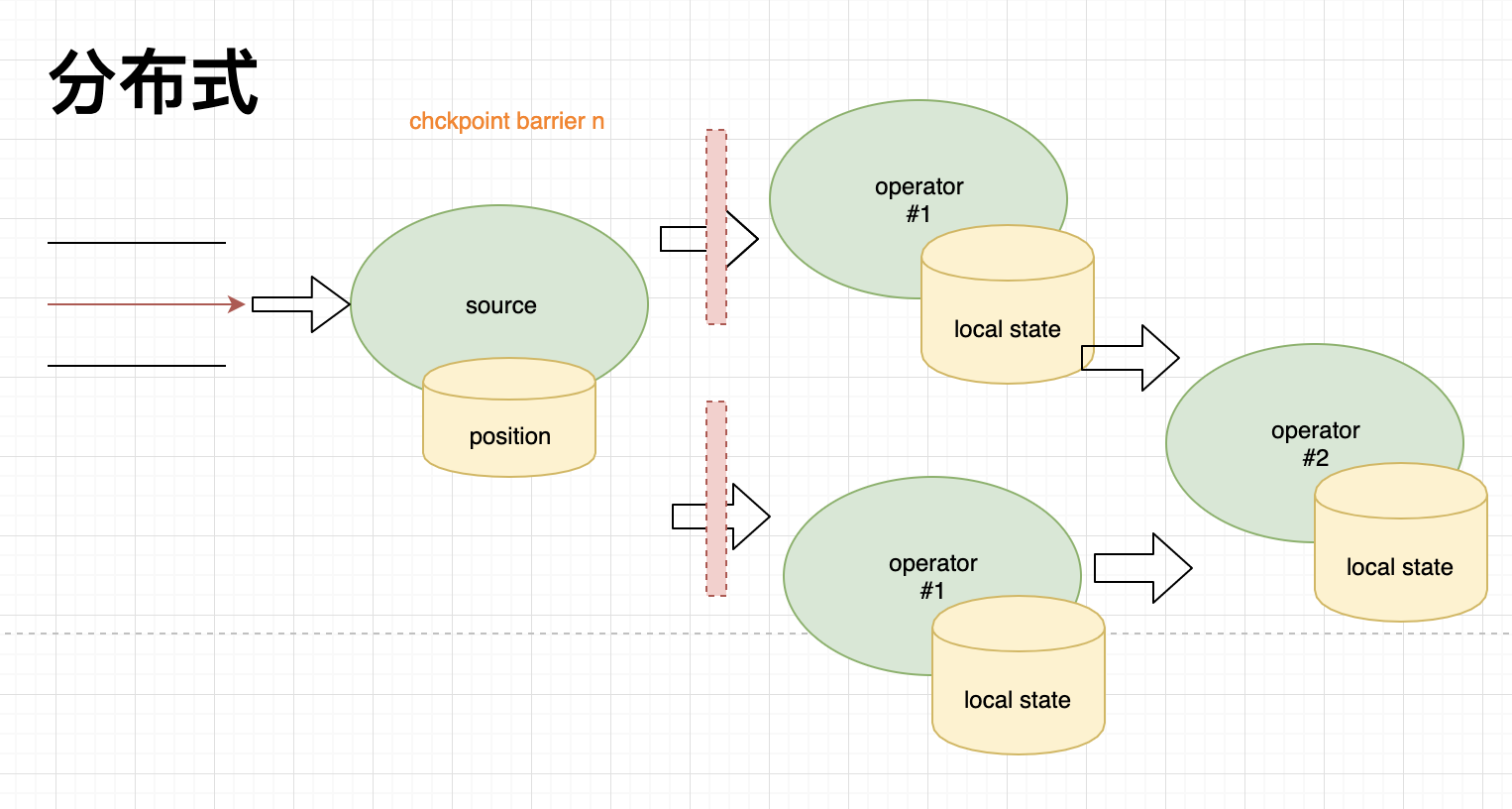
如图,Flink 会在数据流中插入 checkpoint barrier n ,他们会随着数据的流向流入下游的算子,首先记录
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











