



大数据中的 UDF、UDAF、UDTF:详解与应用场景
在大数据处理中,用户自定义函数(UDF、UDAF、UDTF)是非常强大的工具,能够帮助我们实现复杂的数据处理逻辑。本文将详细介绍这三种函数的定义、特点、应用场景以及注意事项,并附上 Hive 中的示例代码。
一、UDF(User-Defined Function)
-
定义
UDF(用户自定义函数)是一种针对单行数据进行处理的函数,返回单个值(如字符串、数字、日期等)。 -
核心特点
输入一行,输出一值:针对单行数据进行计算或转换。
无状态:每次处理独立,不依赖其他行的数据。
常见用途:数据清洗、格式转换、简单计算(如字符串处理、日期转换)。 -
应用场景
将字段中的手机号脱敏(如 substr(phone, 1, 3) + ‘****’)。
计算两个日期的差值(如 datediff(end_date, start_date))。
拼接多个字段(如 concat(name, ‘-’, age))。 -
示例(Hive)sql
-- 自定义 UDF 函数:将字符串转为大写
ADD JAR /path/to/udf.jar;
CREATE TEMPORARY FUNCTION my_upper AS 'com.example.MyUpperUDF';
SELECT my_upper(name) FROM users;
- 注意事项
需注意输入参数的类型匹配。
大量复杂计算的 UDF 可能影响性能。
二、UDAF(User-Defined Aggregate Function)
-
定义
UDAF(用户自定义聚合函数)是一种对多行数据进行聚合操作的函数,返回单个聚合结果(如总和、平均值、最大值等)。 -
核心特点
输入多行,输出一值:对一组数据进行聚合运算。
有状态:需要维护中间状态(如累加器)。
常见用途:自定义统计指标(如分位数、去重计数)。 -
实现原理
通常分两步:
Resolver:类型检查和参数校验。
Evaluate:实现聚合逻辑(如初始化、迭代、合并、输出结果)。 -
应用场景
自定义加权平均值(如 weighted_avg(score, weight))。
统计字符串字段的拼接结果(如 concat_agg(str))。 -
示例(Hive)sql
-- 自定义 UDAF 函数:计算字段的中位数
ADD JAR /path/to/udaf.jar;
CREATE TEMPORARY FUNCTION median AS 'com.example.MedianUDAF';
SELECT department, median(salary) FROM employees GROUP BY department;
- 注意事项
需处理分布式环境下的中间结果合并。
避免内存溢出(如聚合大量数据时)。
三、UDTF(User-Defined Table-Generating Function)
-
定义
UDTF(用户自定义表生成函数)是一种将单行输入转换为多行输出的函数(类似 explode 函数)。 -
核心特点
输入一行,输出多行:用于展开复杂结构(如数组、JSON)。
生成虚拟表:可与原表字段联合查询。
常见用途:解析嵌套数据(如 JSON 数组、Map 结构)。 -
应用场景
将 JSON 数组展开为多行(如 {“tags”: [“A”, “B”, “C”]} → 3 行)。
拆分复合字段(如 “1:2:3” → 3 行 1、2、3)。 -
示例(Hive)sql
-- 自定义 UDTF 函数:拆分字符串为多行
ADD JAR /path/to/udtf.jar;
CREATE TEMPORARY FUNCTION split_to_rows AS 'com.example.SplitUDTF';
SELECT user_id, split_word
FROM users
LATERAL VIEW split_to_rows(text, ':') t AS split_word;
- 注意事项
需使用 LATERAL VIEW 语法展开结果。
输出字段需显式命名(如 t AS split_word)。
四、三者的对比
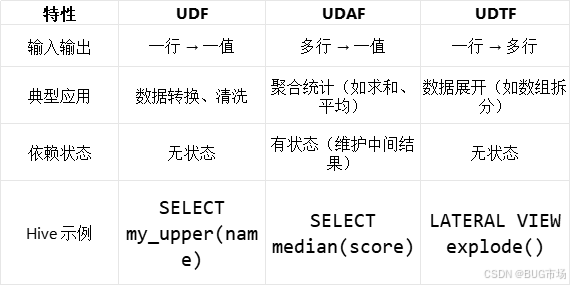
五、使用场景总结
UDF:字段级别的简单转换(如格式处理)。
UDAF:分组后的聚合计算(如自定义统计指标)。
UDTF:复杂数据结构的展开(如 JSON、数组解析)。
六、注意事项
性能优化:避免在 UDF/UDAF/UDTF 中执行复杂逻辑(如网络请求)。
数据倾斜:UDTF 可能因生成大量数据导致 Shuffle 压力。
类型安全:确保输入输出类型与函数定义一致。

















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









