




 Kafka作为实时信息收集平台,注重持久性和性能。它利用nio进行消息读写,通过buffer缓存批量写入磁盘,减少IO操作。采用文件存储消息,磁盘检索开支小。Producer和Consumer端批量缓存并压缩消息,提高网络IO效率。Kafka支持gzip和snappy等压缩方式,优化整体性能。
Kafka作为实时信息收集平台,注重持久性和性能。它利用nio进行消息读写,通过buffer缓存批量写入磁盘,减少IO操作。采用文件存储消息,磁盘检索开支小。Producer和Consumer端批量缓存并压缩消息,提高网络IO效率。Kafka支持gzip和snappy等压缩方式,优化整体性能。
kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力.
1、持久性:通过nio进行消息读写,同时利用buffer缓存数据,多次写入,大批量刷进磁盘,较少io.
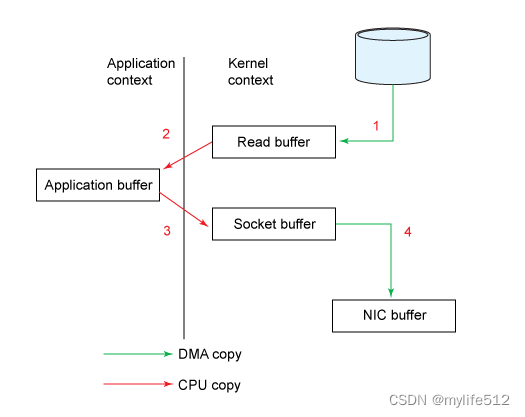
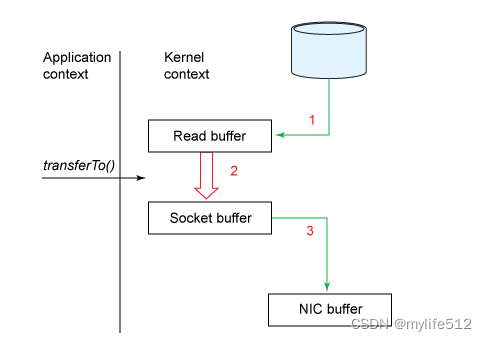
kafka使用文件存储消息,这就直接决定kafka在性能上严重依赖文件系统的本身特性.且无论任何OS下,对文件系统本身的优化几乎没有可能.文件缓存/直接内存映射等是常用的手段.因为kafka是对日志文件进行append操作,因此磁盘检索的开支是较小的;同时为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数.
2、性能:压缩+nio。producer和consumer都会缓存buffer,批量flush。
需要考虑的影响性能点很多,除磁盘IO之外,我们还需要考虑网络IO,这直接关系到kafka的吞吐量问题.kafka并没有提供太多高超的技巧;对于producer端,可以将消息buffer起来,当消息的条数达到一定阀值时,批量发送给broker;对于consumer端也是一样,批量fetch多条消息.不过消息量的大小可以通过配置文件来指定.对于kafka broker端,似乎有个sendfile系统调用可以潜在的提升网络IO的性能:将文件的数据映射到系统内存中,socket直接读取相应的内存区域即可,而无需进程再次copy和交换. 其实对于producer/consumer/broker三者而言,CPU的开支应该都不大,因此启用消息压缩机制是一个良好的策略;压缩需要消耗少量的CPU资源,不过对于kafka而言,网络IO更应该需要考虑.可以将任何在网络上传输的消息都经过压缩.kafka支持gzip/snappy等多种压缩方式.


















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











