



大数据时代
大数据的特征 3V——Volume(海量)、Variety(多样)、Velocity(实时)
- 海量:数据量巨大,TB(1TB=1024GB)、PB(1PB=1024TB)数据级的处理, 已经成为基本配置。
- 多样:处理多样性的数据类型,结构化数据和非结构化数据,能处理Web数据,能处理语音数据甚至是图像、视频数据。
- 实时:在客户每次浏览页面、每次下订单的过程中都存在、都会需要对用户进行实时的推荐,决策已经变得实时。
数据时代下的数据存储系统,需要具备:
- High performance –高并发的读写能力。高并发、实时动态获取和更新数据。
- Huge Storage –高效率的存储和访问能力。类似SNS(社交服务网站),海量用户信息的高效率实时存储和查询。
- High Scalability && High Availability –高可扩展性和高可用性。需要拥有快速横向扩展能力、提供7*24小时不间断服务。
大数据时代对数据存取技术的要求:
- 低延迟的读写速度
- 支撑海量的数据和流量
- 大规模集群的管理
数据库发展历程
上世纪七十年代:关系型数据库(TRDB,Traditional Relational Database)出现。
二十一世纪头十年:NoSQL数据库(NoSQL,Not only SQL)出现。
二十一世纪第二个十年:NewSQL数据库出现。
TRDB 在大数据下的局限性:
TRDB:基于单机管理数据,存储受限于单机(服务器)物理性能
解释:数据存储和访问能力受限于硬盘、主板总线、内存、CPU的硬件最大性能指标。解决办法:纵向扩充(基于服务器本身的功能挖掘)和横向扩充(基于多服务器)两种方式解决单机处理大数据的局限性。
TRDB:集中式数据库管理,可扩展性差
解释:关系数据库系统处理数据,一般只能在单机范围内(纵向扩充)实现,横向多级扩充(分布式应用)存在很大困难。
硬件环境直接影响不同数据库的存储容量和处理速度。
对内存的高度利用,发展出了基于内存的NoSQL数据库技术,如Redis、FastDB、Memcached等;基于多服务器的扩充思路,产生了以分布式处理为软件技术特点的其他NoSQL数据库系统。
NewSQL的设计者既实现了NoSQL的快速、有效的大数据处理能力,又实现了传统关系型数据库的SQL、事务处理等的优势,目的是结合传统关系型数据库与NoSQL数据库技术的优点,实现在大数据环境下的数据存储和处理。
什么是NoSQL?
- 最新NoSQL官网的定义:主体符合非关系型、分布式、开放源码和具有横向扩展能力的下一代数据库。
- Not Only SQL的缩写,它不一定遵循传统数据库的一些基本要求,比如说遵循SQL标准、表结构等等。
- 相比传统数据库,叫它分布式数据管理系统更贴切,数据存储被简化更灵活,重点被放在了分布式数据管理上。
NoSQL数据库所共同具备的特征:
- 不使用SQL。
- 通常都是开源项目。
- 大多NoSQL数据库的研发动机,为了在集群环境中运行。
- 使用弱存储模式技术:没有表结构强制定义,没有数据存入类型的强制检查,使得数据存入速度加快。NoSQL技术主要解决以互联网业务应用为主的大数据应用问题,主要关注存储速度和存储能力。
- 采用弱事物保证数据可用性及安全性或根本没有事物处理机制。
- 主要采用多机分布式处理(DP, Distributed Processing)方式。
- NoSQL数据库无需事先定义模式,可动态增添字段,这种特点在处理不规则数据和自定义字段时非常有用。
NoSQL与TRDB的比较
为深入理解NoSQL,必须区分清楚NoSQL软件技术与TRDB软件技术。
NoSQL与TRDB的实现技术比较:
- TRDB以集中部署一台物理机为最初出发点,而NoSQL的核心技术思路是分布式技术;
- TRDB基于单机的硬盘数据处理技术为主,NoSQL基于分布式的或者内存数据处理技术为主;
- 数据库数据存储模式不一样:TRDB为强数据存储模式,NoSQL为弱数据存储模式;
- TRDB的事务严遵循ACID原则,而NoSQL遵循Base原则或根本没有;
- TRDB都遵循SQL操作标准,NoSQL没有统一的操作标准。
TRDB(传统数据库)在具体数据处理过程,常用到事务处理功能,目的为了保证数据处理的ACID,即原子性(A, Atomicity)、一致性(C, Consistency)、隔离性(I, Isolation)、持久性(D, Durability)。这四个属性通常称为ACID特性。
NoSQL技术诞生那一刻,就定位于非结构性很强的数据,如网页、网站访问点击量、大量的视频存储、地理位置的最优路径处理、广告智能推送等。而这些数据允许插入出错,给客户带来的损失往往是可以接受的。BASE:基本可用(BA, Basically Available)、软状态(S, Soft State)、最终一致性(E, Eventually Consistent)
总的来说,在设计上,NoSQL更关注对数据高并发地读写和对海量数据的存储等,相比关系型数据库,它们在架构和数据模型方面做了“减法”,而在扩展和并发等方面做了“加法”。
NoSQL相较于TRDB的优势:
- 易扩展
- 灵活的数据模型
- 高可用
- 大数据量,高性能
NoSQL常见的四类数据库存储模式
NoSQL的四类数据库存储模式:键值存储模式、文档存储模式、列族存储模式、图存储模式。
键值数据库:
键值数据库(Key Value Database)是一类轻量级(存储结构简单)结合内存处理为主(更快实现对大数据的处理)的NoSQL数据库。数据存储结构最简单的一类NoSQL数据库;
键值数据库使用简单的键值方法来存储数据,将数据存储为键值对集合,其中键作为唯一标识符。键和值都可以是从简单对象到复杂复合对象的任何内容。
是一张简单的哈希表。应用程序提供键和值,并将这一键值对持久化。
Key-Value数据模型实际上是一个映射,即key是查找每条数据地址的唯一关键。数据模型典型的是采用哈希函数实现关键字到值的映射。
查询时,基于key的hash值直接定位到数据所在的点,实现快速查询,并支持大数据量和高并发查询。
由于键值数据库总是通过主键访问,所以它们一般性能较高,且易于扩展。
以提升数据处理速度为第一目标,采用去规则化、约束化以提升数据执行效率。
代表:Redis、Memcached、Amazon DynamoDB、etcd。
键值数据库存储模式—存储结构基本要素
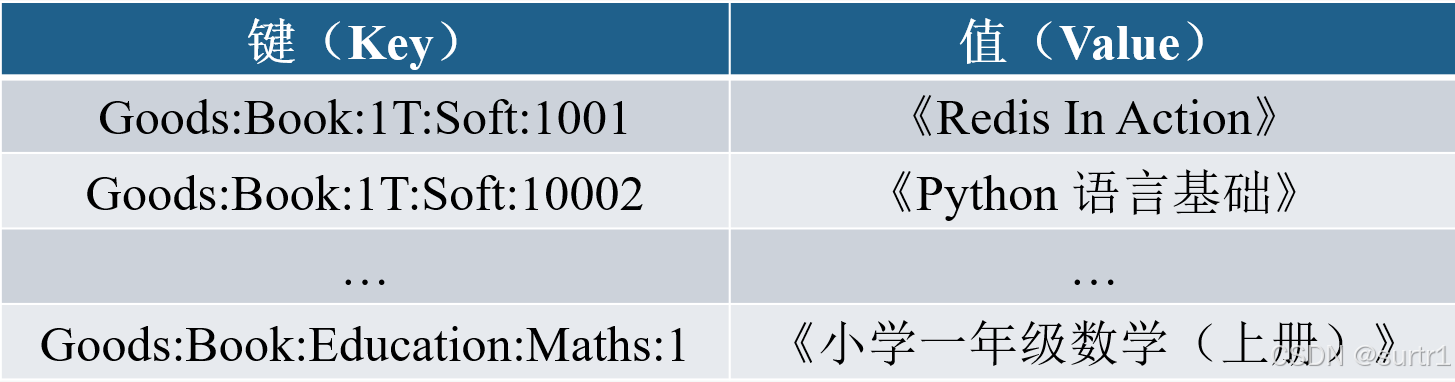
- 键(Key):键起唯一索引值的作用。键内容可采用复杂的自定义结构,以允许键的内容有实际意义。
- 值(Value):值是对应键相关的数据,通过键来获取,可以存放任何类型的数据。值由BLOB(Binary Large object,二进制大对象)进行存储,这意味着任何类型的数据都可以保存,键值数据库无预先定义数据类型的要求。
- 键值对(Key-Value Pair):键和值的组合就形成了键值对,它们之间的关系是一对一映射的关系。
- 命名空间Namespace:由键值对所构成的集合。通常由一类键值对数据构成一个集合。在键值对基础上增加命名空间,保证所命名数据集在内存中的唯一性。
- 值的访问方式:命名空间+键内容
应用场景:少量数据存储,高速读写访问。
优点: 简单;快速;高效计算;分布式处理
缺点:对值进行多值查找功能很弱;缺少约束,更容易出错;难以建立复杂关系
文档存储数据库
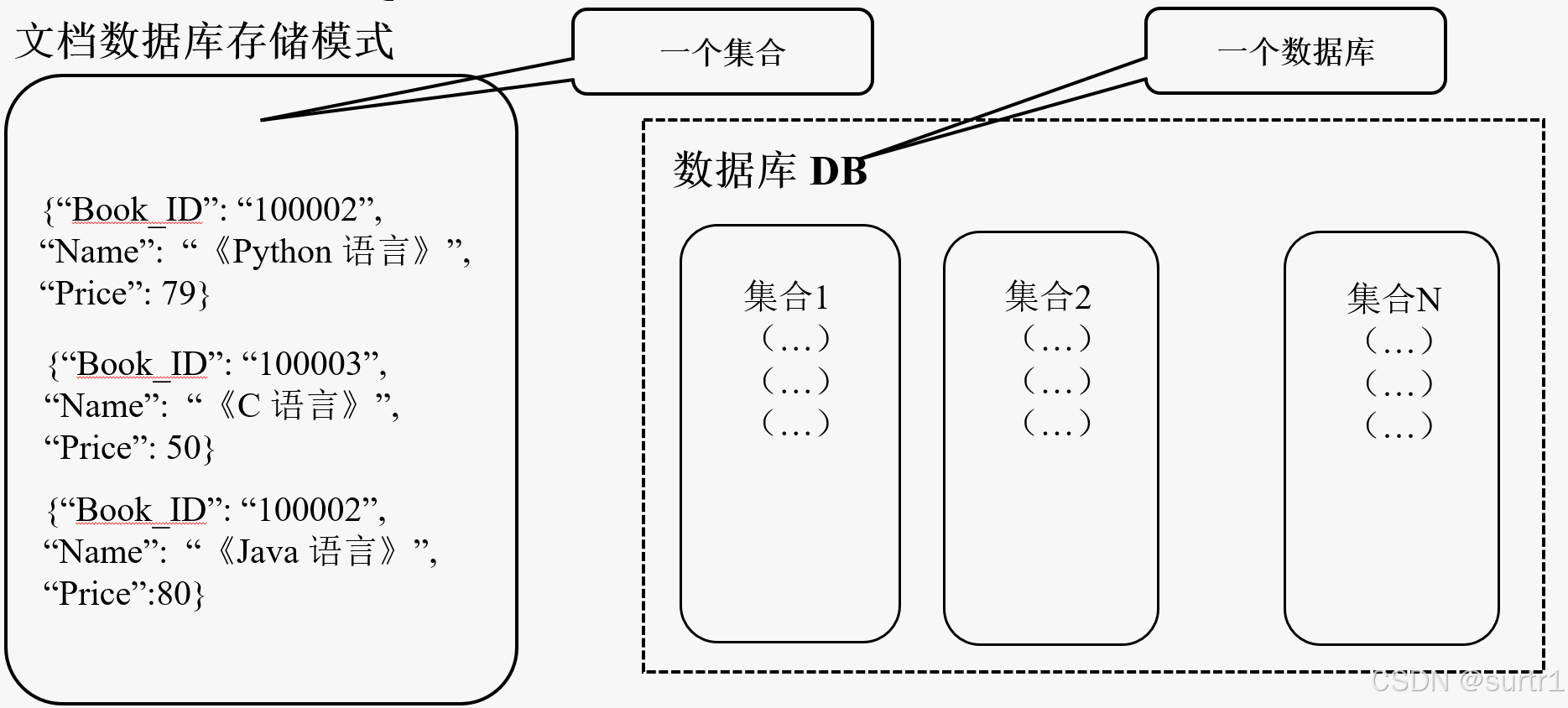
文档数据库与TRDB一样,建立在对磁盘的读写的基础上,对数据进行各种操作。数据存储结构基本形式为键值对;
可存放并获取文档,相当于键值数据库所存放的“值”,其格式可以是XML、JSON、BSON等,这些文档具备可述性,呈现分层的树状结构,可以包含映射表、集合和纯量值;
数据类型:BSON,是一种类json(javascript object notation)的一种二进制形式的存储格式,简称binary json,它和json一样,支持内嵌的文档对象和数组对象
文档数据库的设计思路是针对传统数据库低效的操作性能,首先考虑的是读写性能,为此需要去掉各种传统数据库规则的约束;
文档数据库的设计思路是针对传统数据库低效的操作性能,首先考虑的是读写性能,为此需要去掉各种传统数据库规则的约束;
代表:MongoDB,Apache Couchbase;

文档数据库存储模式特点
优点:
- 简单:没有结构定义、数据写入、集合间关系等约束
- 相对高效:(几十万条的数据写入、上百万条数据读出)/每秒
- 文档格式处理
- 查询功能强大
- 分布式处理
缺点:
- 缺少约束
- 数据出现冗余
- 相对低效:相对于基于内存的键值数据库
列族数据库
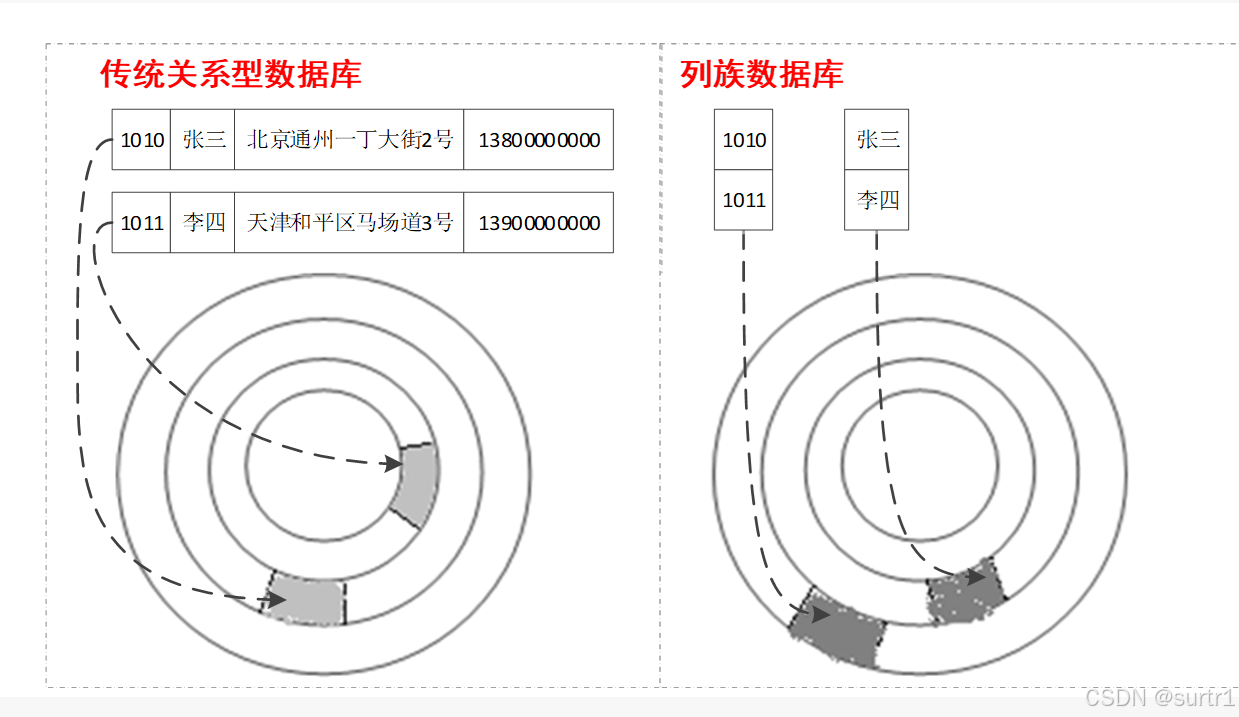
列族数据库为了解决大数据存储问题,引入了分布式处理技术,为了提高数据操作效率,针对传统数据库的弱点,采用了去规则去约束化的思路。
按列存储数据。最大的特点是方便存储结构和半结构化数据,方便做数据压缩,对针对某一列或者是某几列的查询有非常大的io优势
代表性:HBase、Cassandra
提供读、写、删除基本方式。
对于那些零元素数目远远多于非零元素数目,并且非零元素的分布没有规律的矩阵称为稀疏矩阵(sparse)。
由于稀疏矩阵中非零元素较少,零元素较多,因此可以采用只存储非零元素的方法来进行压缩存储。
列族数据库—存储结构基本元素
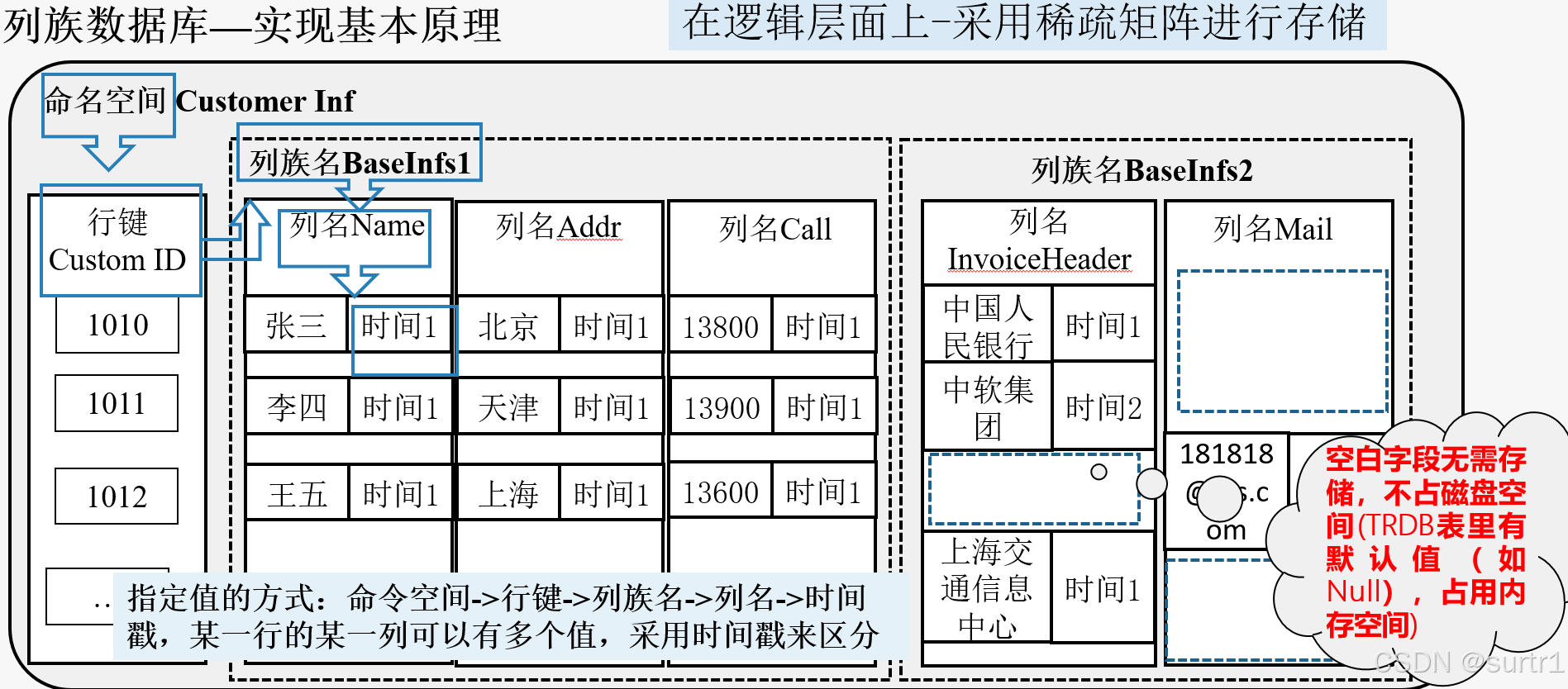
- 命名空间(NameSpace)
列族数据库的顶级数据库结构。相当于关系数据库的表名。 - 行键(Row Key)
唯一区别不同行数据的标识符,具有分区和排序作用。行是虚的,只存在逻辑关系,不存值。 - 列族(Column Family)
由若干个列所构成的一个集合叫列族。 - 列(Column)
列是列族数据库里用来存放单个数值的数据结构。
列的每个值(Value)都附带时间戳(Time Stamp)。通过时间戳来区分值的不同版本。
列族数据库—存储特点 - 擅长大数据处理,特别是 PB 、EB 级的大数据存储和上万台的服务器分布式存储管理,高可扩展性和高可用性。
- 对于命名空间、行键、列族需要预先定义,列无须提早定义,随时可以增加。
- 在大数据应用环境下,管理复杂,必须借助各种高效的管理工具来监控系统的正常运行。
- Hadoop生态系统为基于列族的大数据分析,提供了各种开发工具
- 数据存储模式相对键值数据库、文档数据库要复杂。
- 查询功能相对更加丰富
- 高密集写入处理能力
图数据库
如果把传统关系型数据库比做火车的话,那么到现在大数据时代,图数据库可比做高铁。它已成为NoSQL中关注度最高,发展趋势最明显的数据库。
数据类型:不是图形,而是关系,比如:朋友圈社交网络,广告推荐系统等,专注于构建关系图谱;
代表性:Neo4j/
图数据存储模式:
- 节点(Node):代表一个个实体,如上述的各个城市名称;
- 边(Edge):表明实体之间的关系,如连接各个城市间的铁路;
- 无向边:指铁路是可以双向通行的,不受方向限制,相关的边就是无向边(Undirected Edge);
- 相对无向边,就是有向边(Directed Edge),
- 节点、边,都可以附加属性(Attribute)。
- 图存储是一个包含若干个节点、节点之间存在边关系,节点和边可以附加相关属性的结合系统,简称图(Graph)。
图数据库—基本操作
对于单个节点,提供建立(Create)、删除(Delete)、更新(Update)、(移动Remove)、合并(Merge)等操作;
对于图,提供图的交集、图的并集、图的遍历等操作功能。
图数据库—适用场景
应用领域相对明确:节点、边、属性三要素特征,使图数据库的应用领域很有鲜明特点:
- 具有关系的互联网社交,如QQ、微信里的群及成员关系;
- 基于地图的交通运输,如物流公司用来选择最佳派送路径;
- 生物领域比较研究,如传染病、蛋白质等相关关系的专业研究;
- 物联网跟踪,如汽配企业全球范围配件使用跟踪;
- 游戏开发,如建立玩家与道具的关系;
- 规则推理,如根据网评决定去哪家餐馆
四类NoSQL数据库


















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









