




1 简介
提示词工程(prompt engineering)是自然语言处理(NLP)中重要技术,主要目的是设计、优化、调整用于指导预训练语言模型的输入提示。
- 重要性
- 引导输出:预训练模型虽然有大量的知识,但其输出往往取决于提示词,通过优化提示词可以引导模型输出更有价值的信息
- 提高模型适应性:不同场景需要模型有不同输出,通过提示词可以定制化模型输出,提升模型适应性
- 简化模型使用:对于非专业人士,对模型进行训练是一项复杂工程,具有挑战性,通过提示词引导,可以简化模型使用
- 提示词价值
- 提升生成质量
- 提高准确性
- 提高相关性
- 改进交互性
- 关键技术
- 提示词设计:作为提示词工程核心工作,需要充分考虑模型的特点、任务需求、用户期望等因素;同时提示词的设计需要遵循一定原则,如简洁明了、具体明确、具有指导性
- 提示词优化:通过不断改进和优化提示词来提升模型性能,同时提升输出的价值;一般可以修改提示词、调整提示词数量、位置、给出示例等
- 提示词评估:通过期望输出和模型输出进行对比,评估提示词效果。一般可以通过召回率、准确率、F1值等方式评估
2 模型常见参数设置
在调用模型时,可以先进行一些参数设置,常见的参数包含:温度(Temperature)、顶部概率(Top P/K)、最大长度(Max Length)、停止序列(Stop Sequences)、频率惩罚(Frequency Penalty)、存在惩罚(Presence Penalty)
- 2.1 温度(Temperature)
- Temperature参数用于调整语言模型生成文本的随机性。简单来说Temperature设置的越小输出的内容越确定,值越大结果越随机。Temperature参数实际上是在抽样策略阶段,对这些概率进行调整,以控制生成文本的多样性和可预测性,通常是大于0的实数,但是值太大意义不大,为0输出最保守,较多的模型将值定义在【0,1】的范围
- 高Temperature :增加生成文本的随机性,使得不太可能的词汇有更高的出现概率。比较适合创作场景,但结果可能太发散、不连贯等
- 低Temperature :减少随机性,使得更可能的词汇出现概率更高。比较适合学术等对确定性要求高的场景,但是会丧失多样性

- 原理
- Temperature参数通过对模型输出的概率分布进行缩放来起作用。具体来说,对于每个可能的下一个词,模型计算出一个原始概率分布,然后使用以下公式进行调整:
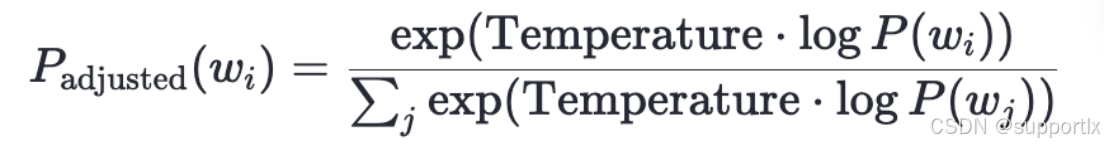
- 2.2 Top P/K
- &
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









