







什么是 RAG
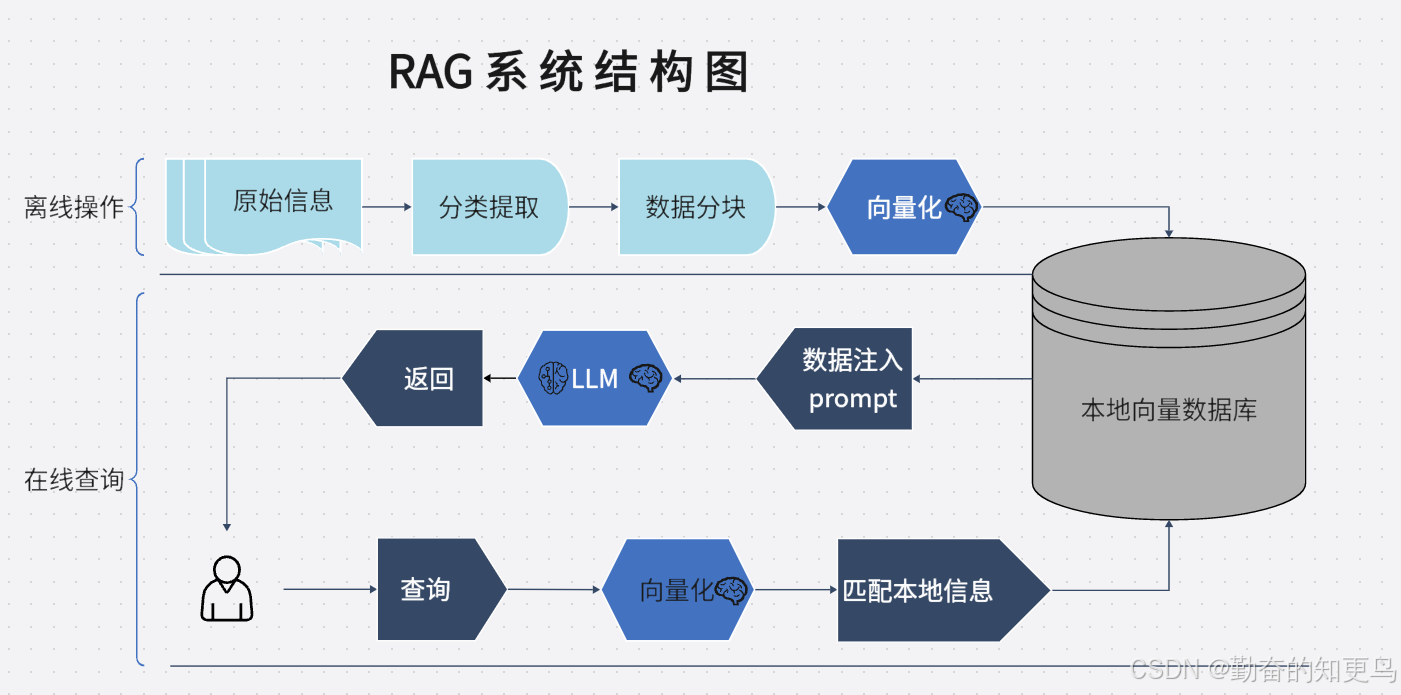
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将语言模型(如 ChatGPT)与外部知识库结合的技术,使其在生成回答时能够调用真实知识来源,而不仅依赖模型本身的参数记忆。
LangChain 是一个构建大语言模型(LLM)应用的强大框架,提供了连接向量数据库、检索器、提示模板和 LLM 的模块化工具链。
RAG 系统结构图
项目依赖安装
pip install langchain faiss-cpu tiktoken pymupdf python-dotenv gradio requests
pip install ollama
项目结构及实现步骤
rag/
├── docs/
│ ├── a.PDF
│ └── b.PDF
├── app.py
├── embedding_server.py
├── local_embed.py
├── requirement.txt
└── webapp.py
步骤一:加载文本、PDF 与网页内容 + 动态上传更新知识库(增量向量)
from langchain.document_loaders import TextLoader, PyMuPDFLoader, WebBaseLoader
from langchain.text_splitter import CharacterTextSplitter
import os
splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
# 初始化向量库(全量)
def load_all_documents():
docs_dir = "docs"
all_docs = []
for filename in os.listdir(docs_dir):
filepath = os.path.join(docs_dir, filename)
if filename.endswith(".txt"):
all_docs += TextLoader(filepath).load()
elif filename.endswith(".pdf"):
all_docs += PyMuPDFLoader(filepath).load()
all_docs += WebBaseLoader("https://en.wikipedia.org/wiki/Entropy").load()
return splitter.split_documents(all_docs)
def split_file(file_path):
if file_path.endswith(".pdf"):
return splitter.split_documents(PyMuPDFLoader(file_path).load())
elif file_path.endswith(".txt"):
return splitter.split_documents(TextLoader(file_path).load())
return []
docs = load_all_documents()
步骤二:构建向量数据库(FAISS)
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vectorstore = FAISS.from_documents(docs, embedding_model)
步骤三:支持多模型选择的 RAG 配置
from langchain_community.llms import Ollama
from langchain.chains import ConversationalRetrievalChain
MODEL_NAME = "qwen:7b"
llm = Ollama(model=MODEL_NAME)
qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
步骤四:多轮对话 + 气泡式上下文显示 + 模型描述信息 + 用户身份记忆 + Markdown 返回
chat_sessions = {} # 多用户支持:chat_sessions[user_id] = chat_history
MODEL_DESCRIPTIONS = {
"qwen:7b": "阿里巴巴 Qwen 通用对话模型(7B)",
"llama3": "Meta 发布的 LLaMA3 模型,支持多语言对话",
"chatglm3": "智谱 AI 的 ChatGLM 第三代模型",
"deepseek-llm": "DeepSeek 高性能代码+知识大模型"
}
Gradio 前端升级:增量更新 + 文档预览 + Markdown 格式 + 多用户会话支持
import gradio as gr
import uuid
def rag_chat_interface(query, model_name, file, user_id):
global qa_chain, vectorstore
if user_id not in chat_sessions:
chat_sessions[user_id] = []
chat_history = chat_sessions[user_id]
llm = Ollama(model=model_name)
qa_chain.llm = llm
file_preview = ""
if file is not None:
saved_path = os.path.join("docs", file.name)
with open(saved_path, "wb") as f:
f.write(file.read())
new_docs = split_file(saved_path)
vectorstore.add_documents(new_docs)
qa_chain.retriever = vectorstore.as_retriever()
file_preview = new_docs[0].page_content[:300] + "..."
result = qa_chain({"question": query, "chat_history": chat_history})
chat_history.append((query, result['answer']))
# 构建 markdown 聊天记录
chat_display = "\n\n".join([f"**🧑💻 用户:** {q}\n\n**🤖 回答:** {a}" for q, a in chat_history])
model_info = f"\n\n---\n📌 当前模型:**{model_name}** - {MODEL_DESCRIPTIONS.get(model_name, '')}"
if file_preview:
model_info += f"\n\n📄 文档预览:\n> {file_preview}"
return chat_display + model_info
# 自动生成用户 ID(模拟多用户)
def get_user_id():
return str(uuid.uuid4())[:8]
gr.Interface(
fn=rag_chat_interface,
inputs=[
gr.Textbox(label="提问内容"),
gr.Dropdown(["qwen:7b", "llama3", "chatglm3", "deepseek-llm"], value="qwen:7b", label="选择模型"),
gr.File(label="上传文档 (可选)"),
gr.Textbox(label="用户 ID", value=get_user_id(), interactive=True)
],
outputs=gr.Markdown(label="问答结果"),
title="📚 RAG 问答系统 with LangChain(多模型 + Markdown + 文档预览 + 用户会话)"
).launch()
快速运行
ollama run qwen:7b # 启动本地模型
python webapp.py # 启动 Gradio 页面
一键打包项目模板
使用 zip 工具或如下命令打包为部署包:
zip -r rag_ollama_demo.zip rag/
推荐组件清单:pip freeze > requirements.txt
aiofiles==24.1.0
aiohappyeyeballs==2.6.1
aiohttp==3.12.13
aiosignal==1.3.2
annotated-types==0.7.0
anyio==4.9.0
asttokens==3.0.0
attrs==25.3.0
audioop-lts==0.2.1
beautifulsoup4==4.13.4
bleach==6.2.0
certifi==2025.4.26
charset-normalizer==3.4.2
click==8.2.1
colorama==0.4.6
comm==0.2.2
dataclasses-json==0.6.7
debugpy==1.8.14
decorator==5.2.1
executing==2.2.0
faiss-cpu==1.11.0
fastapi==0.115.13
ffmpy==0.6.0
filelock==3.18.0
frozenlist==1.7.0
fsspec==2025.5.1
gradio==5.34.2
gradio_client==1.10.3
greenlet==3.2.3
groovy==0.1.2
h11==0.16.0
hf-xet==1.1.4
httpcore==1.0.9
httpx==0.28.1
httpx-sse==0.4.0
huggingface-hub==0.33.0
idna==3.10
ipykernel==6.29.5
ipython==9.2.0
ipython_pygments_lexers==1.1.1
jedi==0.19.2
Jinja2==3.1.6
joblib==1.5.1
jsonpatch==1.33
jsonpointer==3.0.0
jupyter_client==8.6.3
jupyter_core==5.8.1
kaggle==1.7.4.5
langchain==0.3.25
langchain-community==0.3.25
langchain-core==0.3.65
langchain-huggingface==0.3.0
langchain-ollama==0.3.3
langchain-text-splitters==0.3.8
langsmith==0.3.45
markdown-it-py==3.0.0
MarkupSafe==3.0.2
marshmallow==3.26.1
matplotlib-inline==0.1.7
mdurl==0.1.2
mpmath==1.3.0
multidict==6.5.0
mypy_extensions==1.1.0
nest-asyncio==1.6.0
networkx==3.5
numpy==2.3.0
ollama==0.5.1
orjson==3.10.18
packaging==24.2
pandas==2.3.0
parso==0.8.4
pillow==11.2.1
platformdirs==4.3.8
prompt_toolkit==3.0.51
propcache==0.3.2
protobuf==6.31.1
psutil==7.0.0
pure_eval==0.2.3
pydantic==2.11.7
pydantic-settings==2.9.1
pydantic_core==2.33.2
pydub==0.25.1
Pygments==2.19.1
PyMuPDF==1.26.1
python-dateutil==2.9.0.post0
python-dotenv==1.1.0
python-multipart==0.0.20
python-slugify==8.0.4
pytz==2025.2
pywin32==310
PyYAML==6.0.2
pyzmq==26.4.0
regex==2024.11.6
requests==2.32.3
requests-toolbelt==1.0.0
rich==14.0.0
ruff==0.12.0
safehttpx==0.1.6
safetensors==0.5.3
scikit-learn==1.7.0
scipy==1.15.3
semantic-version==2.10.0
sentence-transformers==4.1.0
setuptools==80.9.0
shellingham==1.5.4
six==1.17.0
sniffio==1.3.1
soupsieve==2.7
SQLAlchemy==2.0.41
stack-data==0.6.3
starlette==0.46.2
sympy==1.14.0
tenacity==9.1.2
text-unidecode==1.3
threadpoolctl==3.6.0
tiktoken==0.9.0
tokenizers==0.21.1
tomlkit==0.13.3
torch==2.7.1
tornado==6.5.1
tqdm==4.67.1
traitlets==5.14.3
transformers==4.52.4
typer==0.16.0
typing-inspect==0.9.0
typing-inspection==0.4.1
typing_extensions==4.14.0
tzdata==2025.2
urllib3==2.4.0
uvicorn==0.34.3
wcwidth==0.2.13
webencodings==0.5.1
websockets==15.0.1
yarl==1.20.1
zstandard==0.23.0
项目结构
1. app.py
import os
from langchain.document_loaders import TextLoader, PyMuPDFLoader, WebBaseLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain_community.llms import Ollama
from langchain.chains import ConversationalRetrievalChain
splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
def load_all_documents():
docs_dir = "docs"
all_docs = []
for filename in os.listdir(docs_dir):
filepath = os.path.join(docs_dir, filename)
if filename.endswith(".txt"):
all_docs += TextLoader(filepath).load()
elif filename.endswith(".pdf"):
all_docs += PyMuPDFLoader(filepath).load()
# 加载一个示例网页内容
all_docs += WebBaseLoader("https://blog.youkuaiyun.com/superfreeman?spm=1000.2115.3001.10640").load()
return splitter.split_documents(all_docs)
def split_file(file_path):
if file_path.endswith(".pdf"):
return splitter.split_documents(PyMuPDFLoader(file_path).load())
elif file_path.endswith(".txt"):
return splitter.split_documents(TextLoader(file_path).load())
return []
docs = load_all_documents()
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
vectorstore = FAISS.from_documents(docs, embedding_model)
MODEL_NAME = "qwen:7b"
llm = Ollama(model=MODEL_NAME)
qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
MODEL_DESCRIPTIONS = {
"qwen:7b": "阿里巴巴 Qwen 通用对话模型(7B)",
"llama3": "Meta 发布的 LLaMA3 模型,支持多语言对话",
"chatglm3": "智谱 AI 的 ChatGLM 第三代模型",
"deepseek-llm": "DeepSeek 高性能代码+知识大模型"
}
chat_sessions = {} # 多用户会话管理
2. webapp.py
import gradio as gr
import os
import uuid
from app import qa_chain, vectorstore, split_file, MODEL_DESCRIPTIONS, chat_sessions
from langchain_community.llms import Ollama
def rag_chat_interface(query, model_name, file, user_id):
if user_id not in chat_sessions:
chat_sessions[user_id] = []
chat_history = chat_sessions[user_id]
llm = Ollama(model=model_name)
qa_chain.llm = llm
file_preview = ""
if file is not None:
saved_path = os.path.join("docs", file.name)
with open(saved_path, "wb") as f:
f.write(file.read())
new_docs = split_file(saved_path)
vectorstore.add_documents(new_docs)
qa_chain.retriever = vectorstore.as_retriever()
file_preview = new_docs[0].page_content[:300] + "..."
result = qa_chain({"question": query, "chat_history": chat_history})
chat_history.append((query, result['answer']))
chat_display = "\n\n".join([f"**🧑💻 用户:** {q}\n\n**🤖 回答:** {a}" for q, a in chat_history])
model_info = f"\n\n---\n📌 当前模型:**{model_name}** - {MODEL_DESCRIPTIONS.get(model_name, '')}"
if file_preview:
model_info += f"\n\n📄 文档预览:\n> {file_preview}"
return chat_display + model_info
def get_user_id():
return str(uuid.uuid4())[:8]
gr.Interface(
fn=rag_chat_interface,
inputs=[
gr.Textbox(label="提问内容"),
gr.Dropdown(["qwen:7b", "llama3", "chatglm3", "deepseek-llm"], value="qwen:7b", label="选择模型"),
gr.File(label="上传文档 (可选)"),
gr.Textbox(label="用户 ID", value=get_user_id(), interactive=True)
],
outputs=gr.Markdown(label="问答结果"),
title="📚 RAG 问答系统 with LangChain(多模型 + Markdown + 文档预览 + 用户会话)"
).launch()
3. local_embed.py
from langchain.embeddings.base import Embeddings
import requests
class LocalEmbedding(Embeddings):
def __init__(self, endpoint="http://127.0.0.1:9000/embed"):
self.endpoint = endpoint
def embed_documents(self, texts):
response = requests.post(self.endpoint, json={"texts": texts})
return response.json()["embeddings"]
def embed_query(self, text):
return self.embed_documents([text])[0]
4. docs/
- 这是你的本地知识库目录,放入
.txt和.pdf文件即可自动加载索引。
快速启动步骤
- 安装依赖:
pip install -r requirements.txt
- 启动 Ollama 本地模型服务:
ollama run qwen:7b
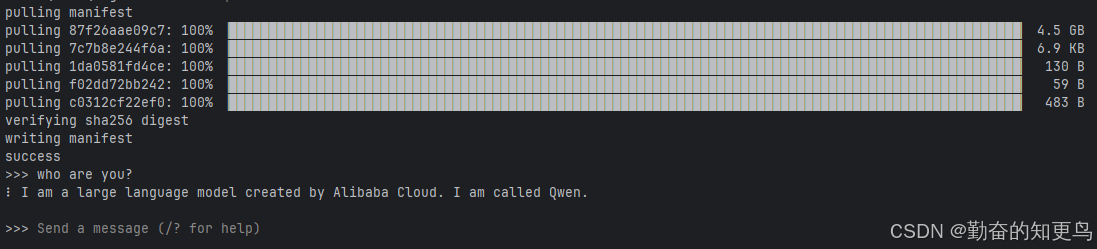
- 启动 Web 服务:
在启动时候,如果做本地embedded模型部署,建议先启动本地服务,具体见代码里的介绍。
python webapp.py
成功启动后,Gradio 会自动开启一个本地 Web 服务,终端中通常会出现如下提示:
Running on local URL: http://127.0.0.1:7860,打开如下,一个简单的RAG本地模型就完成了,是不是很简单。
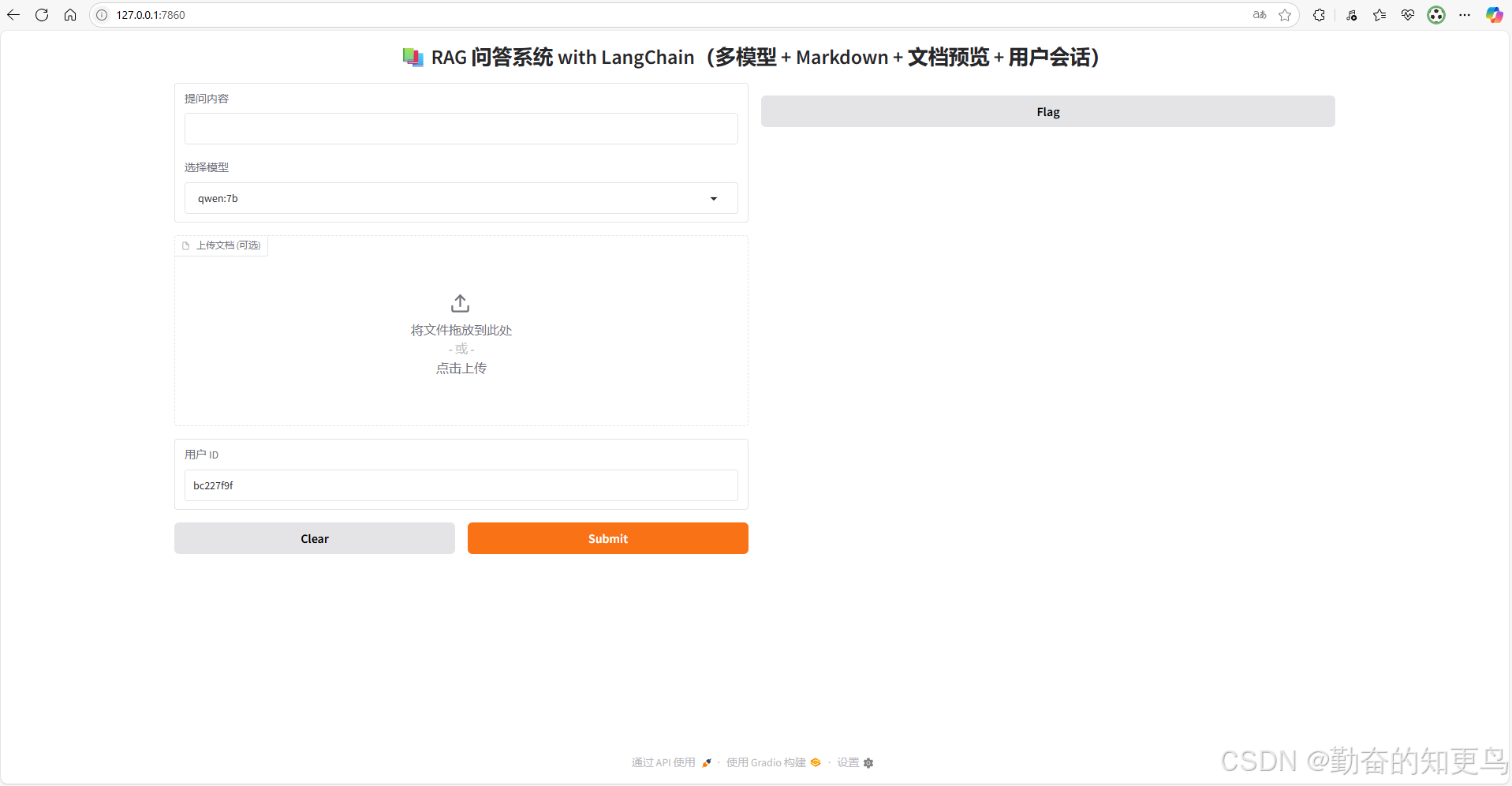
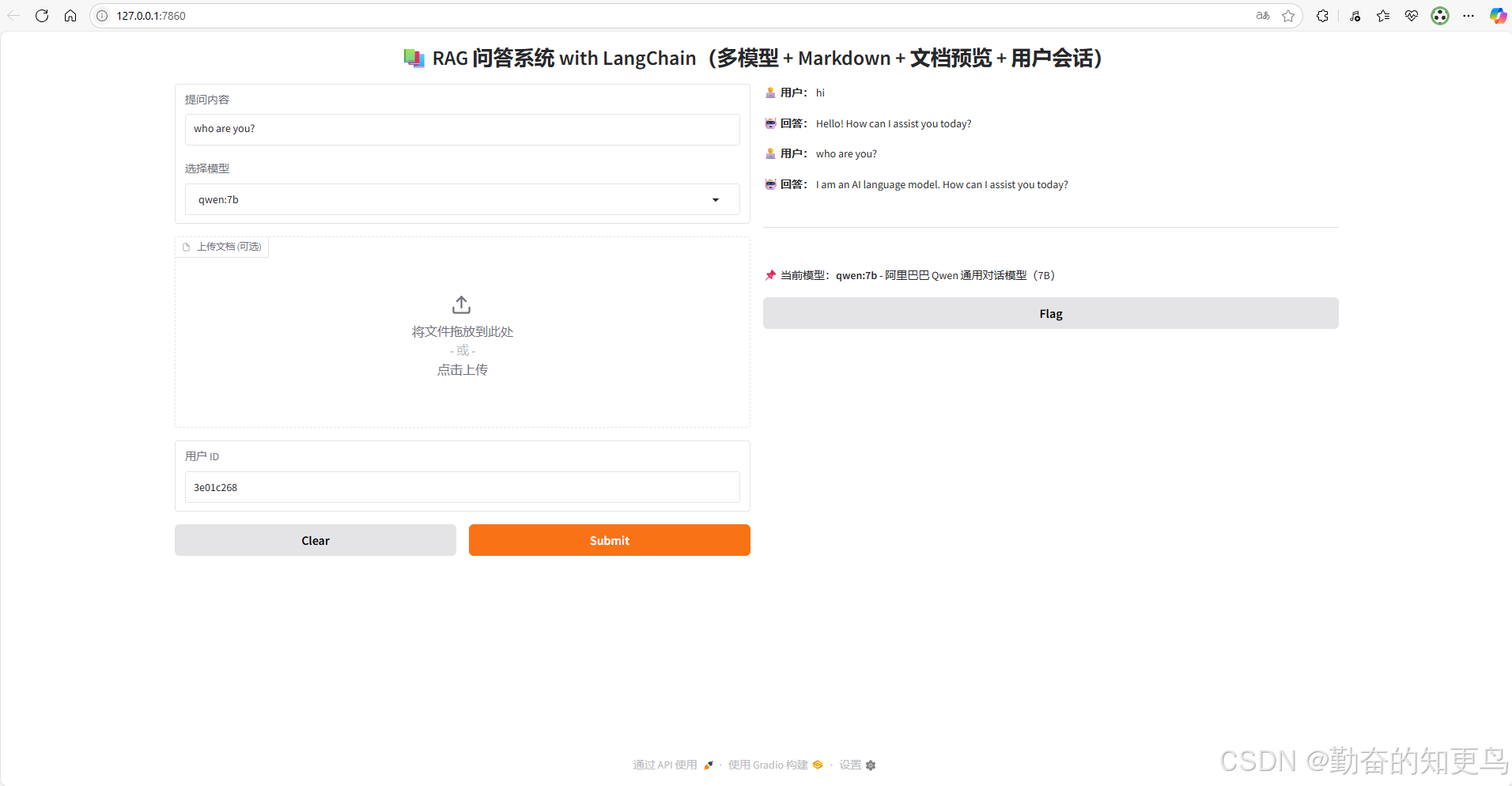
由于LLM模型用的是本地部署的ollama加qwen模型,嵌入式模型也是本地模型,占用的是本地的CPU的计算资源,故要求本地配置至少32G的内存,CPUi512以上,否则非常卡。
参考资源
-
后续如有源码需要,我也上传到csdn上,或者加微信联系我免费获取。



















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











