



 本文讨论了在实际数据抓取中遇到的挑战,如IP限制和使用代理服务器,以及作者以京东miaosha为例,展示如何编写PHP爬虫抓取生活必需品优惠券。同时提到利用GPT进行辅助,强调提出问题和有效应用的重要性。
本文讨论了在实际数据抓取中遇到的挑战,如IP限制和使用代理服务器,以及作者以京东miaosha为例,展示如何编写PHP爬虫抓取生活必需品优惠券。同时提到利用GPT进行辅助,强调提出问题和有效应用的重要性。
没事总分享一些抓取方案的简单代码,实际中爬虫涉及的内容知识点其实很多,一般数据较少或非频繁的时候还是容易处理的。但是简单的时候也有问题的时候,比如ip经常被封,被限制等等问题。如果抓取的时候时间短或可以外赚费用的时候还是建议可以付费下,建议使用不限量的模式,便宜,可以按天甚至按小时。
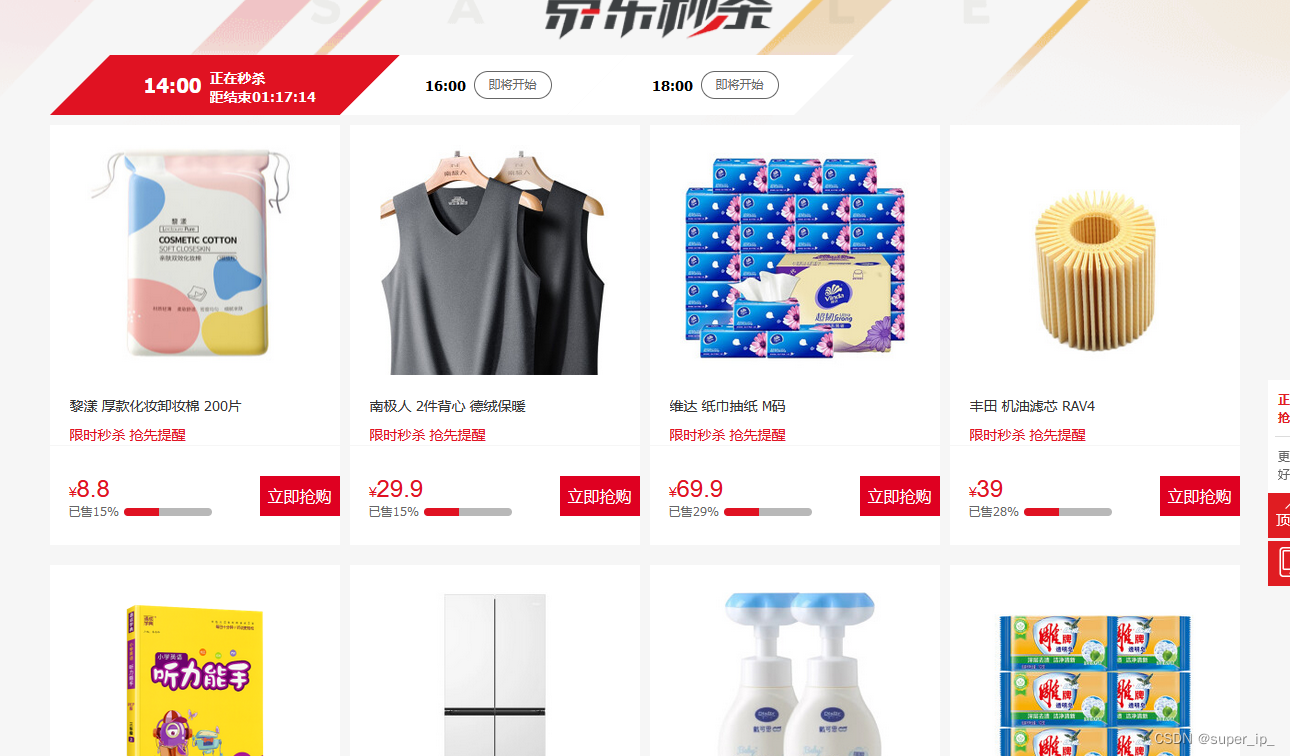
比如我普通人,关心的是啥,关心的当然是日常用品的存储,现在钱不好挣,这些还是可以日常储备的,比如米,纸,油的生活必须品,为此写个爬虫专门爬自己所需产品的活动优惠券。省钱也是挣钱的一种方式是不是?
<?php
// 创建一个新cURL资源
$ch = curl_init();
// 设置URL和相应的选项
curl_setopt($ch, CURLOPT_URL, "https://miaosha.jd.com/");
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// 设置代理服务器
//免费获取爬虫ip:http://www.jshk.com.cn/mb/reg.asp?kefu=xjy
curl_setopt($ch, CURLOPT_PROXY, "http://api.hahado.cn/dmgetip.asp?apikey=xxx&pwd=xxx&getnum=50&httptype=1&geshi=1&fenge=1&fengefu=&Contenttype=1&operate=all");
// 抓取URL并把它传递给浏览器
$output = curl_exec($ch);
// 关闭cURL资源,并且释放系统资源
curl_close($ch);
// 解析HTML内容
$dom = new DOMDocument();
@$dom->loadHTML($output);
// 用XPath查找需要的元素
$xpath = new DOMXPath($dom);
// 假设你要找的商品在一个class为"product"的div中
$products = $xpath->query("//div[@class='product']");
foreach($products as $product) {
// 做你需要的处理
echo $product->nodeValue;
}
?>
现在都可以借助gpt来辅助,还是很方便的,不仅仅这方面的应用。要学会提出问题,才能更好的应用,大概就是这样 ,欢迎交流沟通,欢迎留言和私信。


















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











