



 本文介绍了使用Python和ChatGPT技术抓取并分析电影《孤注一掷》的评论,通过分词和词频统计生成词云图,展示了如何利用编程工具进行影视作品的舆情分析。
本文介绍了使用Python和ChatGPT技术抓取并分析电影《孤注一掷》的评论,通过分词和词频统计生成词云图,展示了如何利用编程工具进行影视作品的舆情分析。
最近热映《孤注一掷》上映后观影效果非常好。我们一起来看下这部电影的评论分析。

这里面提到很多关键词,代表了这部作品的效果。
这样的案例我们如何实现呢,
可以用ChatGPT来帮我们实现。
在ChatGPT中我们进行提问。
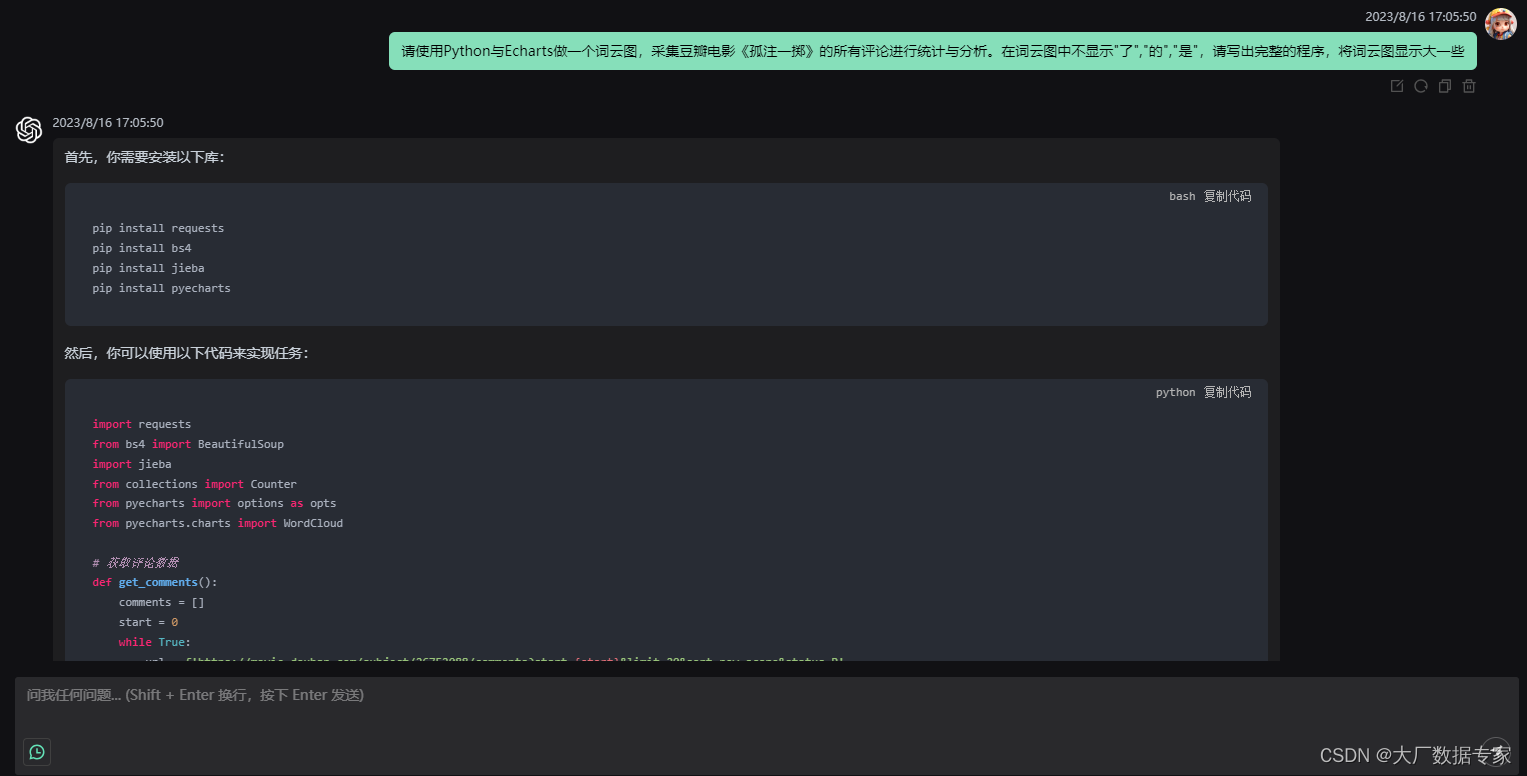
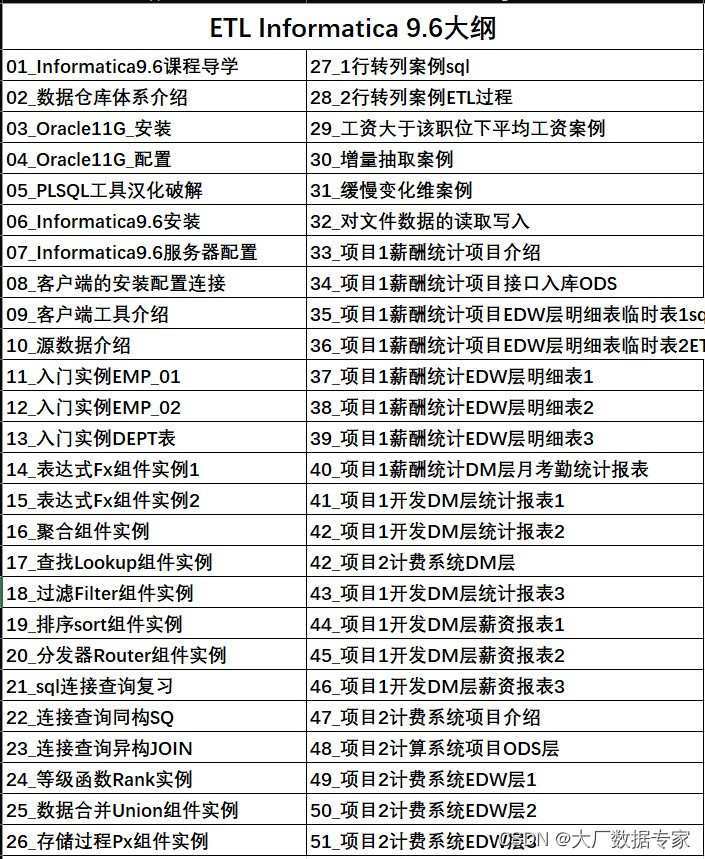
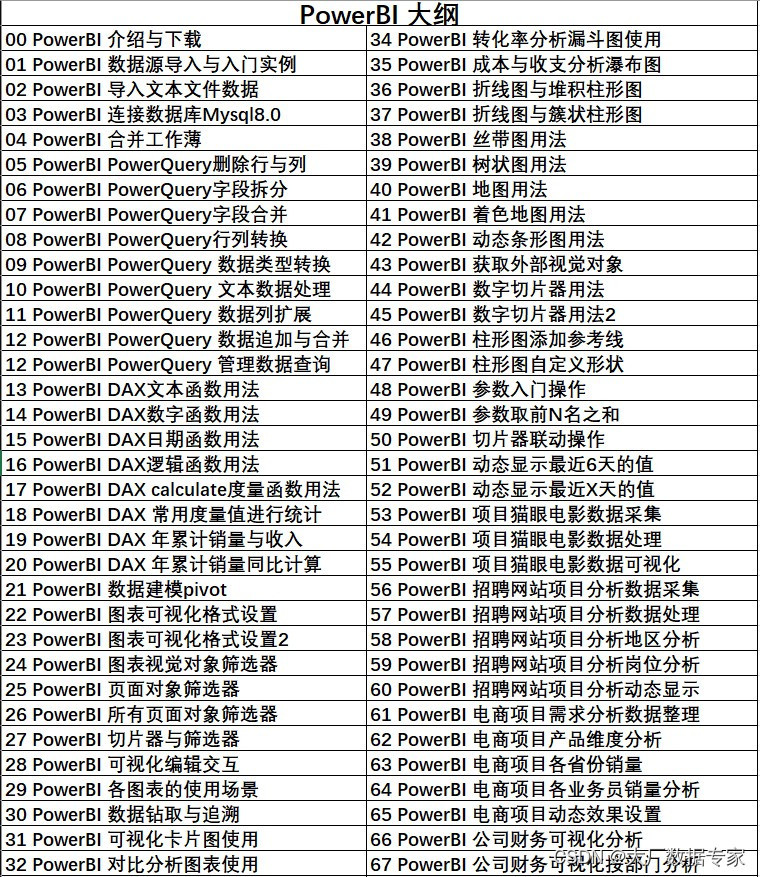
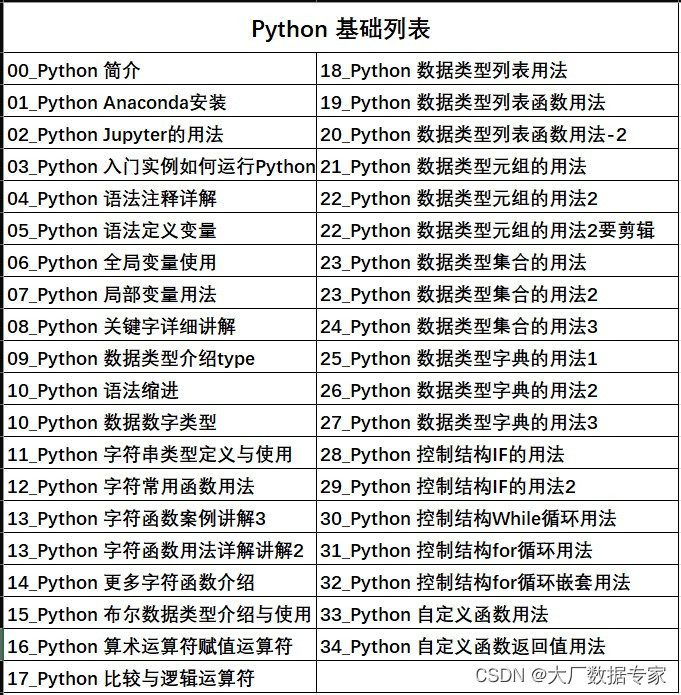
完整代码如下:
import requests
from bs4 import BeautifulSoup
import jieba
from collections import Counter
from pyecharts import options as opts
from pyecharts.charts import WordCloud
# 获取评论数据
def get_comments():
comments = []
start = 0
while True:
url = f'https://movie.douban.com/subject/35267224/comments?start={start}&limit=20&sort=new_score&status=P'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
page_comments = soup.find_all('span', class_='short')
if not page_comments:
break
comments.extend([comment.get_text() for comment in page_comments])
start += 20
return comments
# 分词并统计词频
def count_words(comments):
stopwords = ['了', '的', '是']
words = []
for comment in comments:
seg_list = jieba.cut(comment)
for seg in seg_list:
if seg not in stopwords:
words.append(seg)
word_counts = Counter(words)
return word_counts.most_common(100)
# 生成词云图
def generate_wordcloud(word_counts):
wordcloud = (
WordCloud()
.add("", word_counts, word_size_range=[20, 200]) # 调整词云图大小
.set_global_opts(title_opts=opts.TitleOpts(title="《孤注一掷》评论词云图"))
)
wordcloud.render('wordcloud.html')
# 主函数
def main():
comments = get_comments()
word_counts = count_words(comments)
generate_wordcloud(word_counts)
if __name__ == "__main__":
main()
在PyCharm中进行运行就可以显示了。

以上内容在:https://edu.youkuaiyun.com/lecturer/840?spm=1002.2001.3001.4144
以上内容在:https://edu.youkuaiyun.com/lecturer/840?spm=1002.2001.3001.4144
 以上内容在:https://edu.youkuaiyun.com/lecturer/840?spm=1002.2001.3001.4144
以上内容在:https://edu.youkuaiyun.com/lecturer/840?spm=1002.2001.3001.4144
以上内容在:https://edu.youkuaiyun.com/lecturer/840?spm=1002.2001.3001.4144
以上内容在:https://edu.youkuaiyun.com/lecturer/840?spm=1002.2001.3001.4144


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











