






英伟达针对企业级服务器推出了两种不同版本的显卡,一种是Nvlink版本,另一种是PCIE版本,这两种究竟有何区别,我们用于ai训练的时候又该如何选择呢?
首先我们来看看PCIE版本的,
PCIe版显卡
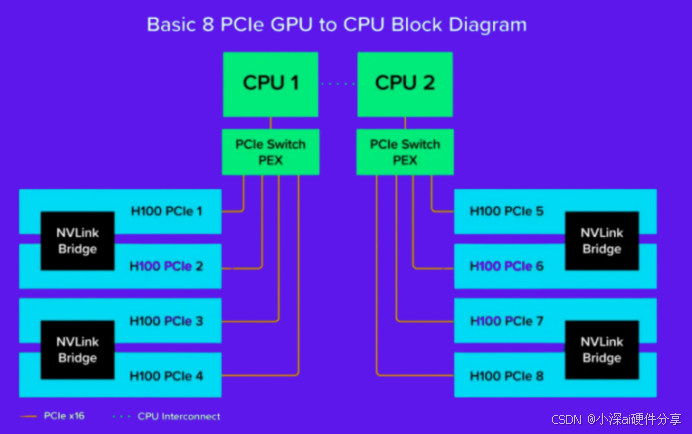 对于PCIE版本的GPU而言,仅能通过桥接器与相邻的GPU相连,如下图的GPU1只能直接访问GPU2,而不能直接访问GPU5,GPU1和GPU5的通信只能通过PCIE信道通信,而且带宽很低,甚至最先进的PCIE协议只有128GB/s,而NVLink的带宽却能高达900GB/s。
对于PCIE版本的GPU而言,仅能通过桥接器与相邻的GPU相连,如下图的GPU1只能直接访问GPU2,而不能直接访问GPU5,GPU1和GPU5的通信只能通过PCIE信道通信,而且带宽很低,甚至最先进的PCIE协议只有128GB/s,而NVLink的带宽却能高达900GB/s。
NVlink版本显卡
而Nvlink版本的就不一样了,Nvlink版的有着SXM架构,是英伟达专为实现GPU间超高速互连而研发的一种高带宽接口,让GPU能够无缝对接于英伟达自家的DGX和HGX系统,目前的话主流的计算卡(A100、H100、V100等)以及消费级旗舰显卡如3090等都具有特定的SXM接口,能实现GPU之间的高速通信。
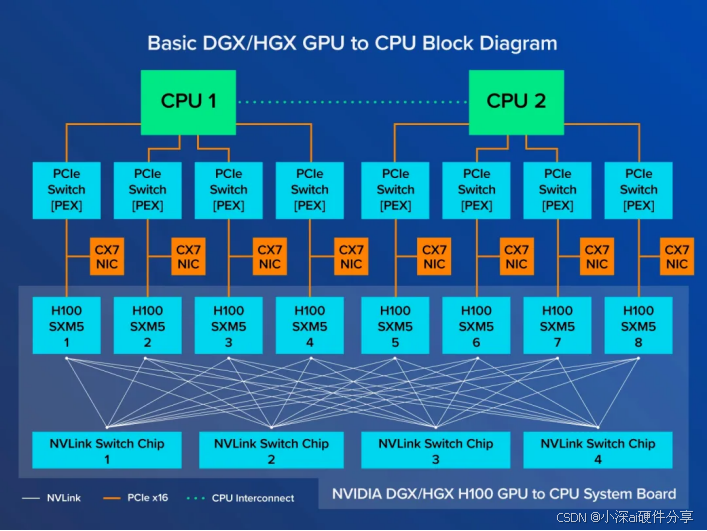
如下图所示:通过NVLink技术,8个GPU被紧密地连接在一起,形成了一个前所未有的高带宽互连网络。具体来说,每个H100 GPU会与4个NVLink交换芯片相连接,以实现GPU间高达900 GB/s的惊人数据传输速率。同时,每个H100 SXM GPU也通过PCIe接口与CPU相连,确保任何GPU生成的数据都能迅速传输至CPU进行处理。
NVSwitch芯片可以将系统中的所有SXM规格GPU连接起来,构建一个高效的数据交换网络,A100 GPU能够实现600GB/s的NVLink数据传输速率,A100的阉割版A800也有400GB/s的传输速率。
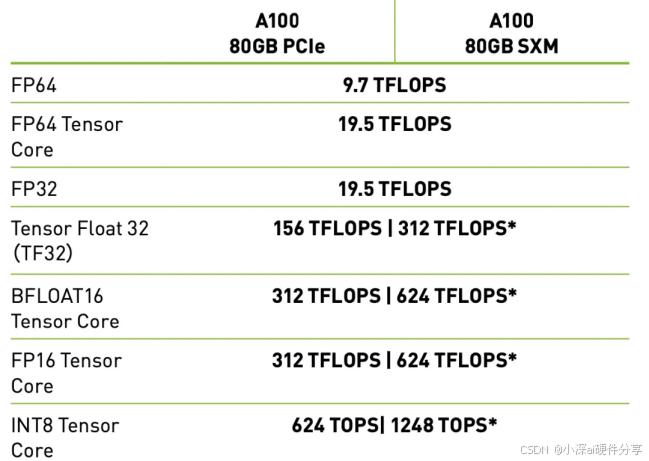
尽管PCIe接口的GPU在GPU间互连带宽上略为逊色,但在单个GPU卡的计算能力上,PCIe版本与SXM版本并没有明显的区别。对于那些不特别依赖GPU间高速连接的应用,例如中小规模的模型训练、推理应用的部署等,GPU间的互连带宽对整体性能的影响并不大。
如下图是A100PCIE版本和NVlink版本的性能对比,可以看出二者单卡的性能完全一致,并不存在SXM比PCIE版本强的情况。
那我们到底该如何选择呢?
如果不想建立一个大规模的集群服务器如8卡或者8卡以上的,仅仅是需要单卡或者4卡以下的性能的话,那我们可以选择PCIE版本的。PCIE版本的可以方便的实现服务器的小型化,节约实验室空间,而且PCIE版本功耗比较小,能效比也会与高很多,价格方面也会低一些
如果我们是想训练大数据集的模型,170B以上的话,可以采用NVlink版本的,这种模型对GPU之间的带宽要求很高,需要GPU保持高速的通信,因此NVlink版本的是最合适的。
不管是选择何种服务器,我们一定要根据自己的实际需求和预算来选择,以便保持最高的投入产出比。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









