









数据结构
二叉查找树
正常情况下时间复杂度是O(logn) O(logn),当数据增大n倍时,耗时增大logn倍(这里的log是以2为底的,比如,当数据增大256倍时,耗时只增大8倍,是比线性还要低的时间复杂度)。二分查找就是O(logn)的算法,每找一次排除一半的可能,256个数据中查找只要找8次就可以找到目标。
最坏出现数据一边倒,时间复杂度是O(n)代表数据量增大几倍,耗时也增大几倍。比如常见的遍历算法。
B tree
B+tree
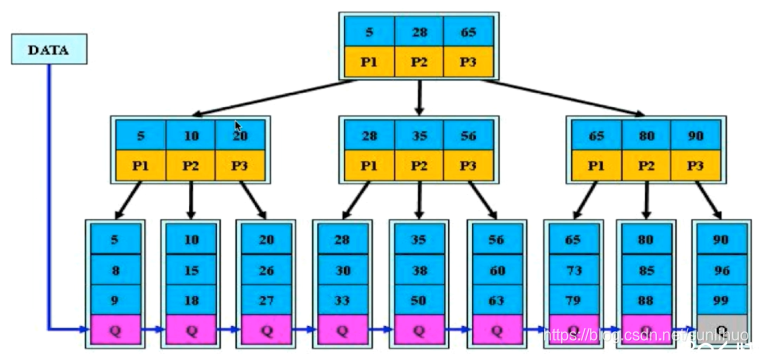
根节点,非叶子节点,叶子节点
所有叶子节点均有一个链指针指向下一个叶子节点
(主键索引中Q是数据,非主键索引中Q是主键id,需再次查询主键索引查出数据)
B+tree更适合用来做存储索引
B+树的磁盘读写代价更低
B+树的查询效率更加稳定
B+树更有利于对数据库的扫描
Hash索引
仅仅能满足“=”,“IN”,不能使用范围查询
无法被用来避免数据的排序操作
不能利用部分索引键查询
不能避免表扫描
hash值冲突后会出现大量数据在同一个地方,性能不一定比b+tree高
密集索引和稀疏索引的区别
密集索引文件中的每个搜索码值都对应一个索引值
稀疏索引文件只为索引码的某些值建立索引项
定位并优化慢查询sql
explain 慢sql日志
联合索引的最左匹配原则的成因
index('name','age')
走索引(where name='a' and age=1 或者 where name='a')
不走索引 where age=1
索引是建立得越多越好吗
数据量小的表不需要建立索引,建立增加额外的索引开销
数据变量需要维护索引,更多的维护成本
也需要更多的空间
MyISAM
MyISAM默认用的是表级锁,不支持行级锁
InnoDB默认用的是等级锁,也支持表级锁
频繁执行全表count语句
对数据进行增删改的频率不高,查询非常频繁
没有事务
InnoDB
InnoDB主键为密集索引,主键未定义,则生成一个隐藏主键
非主键索引存储相关键位和其对应的主键值,包含两次查找
数据增删改查都相当频繁
可靠性要求比较高,要求支持事务
IS 行锁 IX 表锁

















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









