




 本文介绍了如何使用Mycat实现多租户分库方案,重点在于主键生成策略确保全局无冲突且包含租户信息。配置包括server.xml与数据源定义,同时提出了实际项目中租户编码的传递与处理机制,如通过cookie或本地缓存存储,以及后端API的filter处理来确保租户编码在SQL执行中的应用。
本文介绍了如何使用Mycat实现多租户分库方案,重点在于主键生成策略确保全局无冲突且包含租户信息。配置包括server.xml与数据源定义,同时提出了实际项目中租户编码的传递与处理机制,如通过cookie或本地缓存存储,以及后端API的filter处理来确保租户编码在SQL执行中的应用。
方案一:
租户共享MyCat中的schema,schema中的表会跨越多个datanode,因此每个表应该指定primary key, sharding rule可以解析primary key中包含的租户code,从而进一步确定每个租户对应的datanode.这就要求每个表的主键生成必须要主键生成器来生成(key generator),主键生成器要满足以下要求:
- 主键生成效率高
- 生成的主键全局无冲突
- 生成的主键要包含租户code信息,并可被反向解析出来
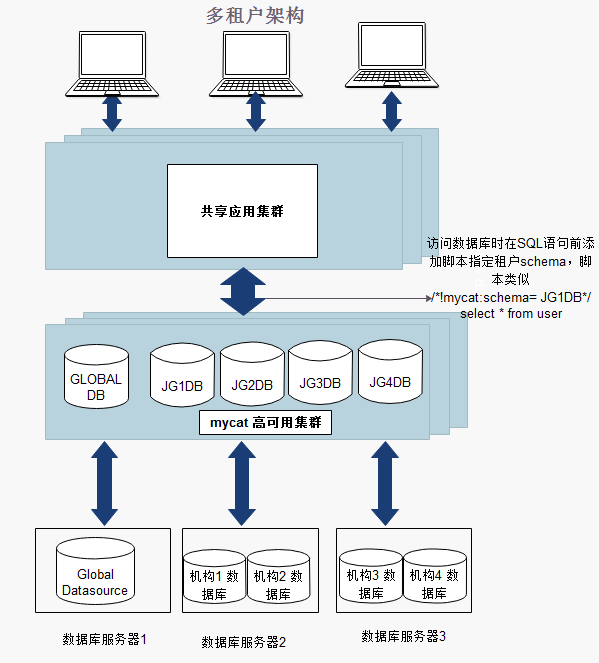
方案二:
每个租户独占MyCat中的一个schema,schema的表不会跨datanode,类似的拓扑如下:
MyCat核心配置:
- server.xml
<user name="root">
<property name="password">password</property>
<property name="schemas">
GLOBALDB,JG1DB,JG2DB,JG3DB,JG4DB,JG5DB
</property>
</user>
2. schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="GLOBALDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<table name="orgmapping" primaryKey="id" type="global" dataNode="gdn" />
</schema>
<schema name="JG1DB" checkSQLschema="false" sqlMaxLimit="100">
<table name="user" primaryKey="id" autoIncrement="true" dataNode="jg1dn" />
<table name="user_order" primaryKey="id" autoIncrement="true" dataNode="jg1dn" />
</schema>
<schema name="JG2DB" checkSQLschema="false" sqlMaxLimit="100">
<table name="user" primaryKey="id" autoIncrement="true" dataNode="jg2dn" />
<table name="user_order" primaryKey="id" autoIncrement="true" dataNode="jg2dn" />
</schema>
<schema name="JG3DB" checkSQLschema="false" sqlMaxLimit="100">
<table name="user" primaryKey="id" autoIncrement="true" dataNode="jg3dn" />
<table name="user_order" primaryKey="id" autoIncrement="true" dataNode="jg3dn" />
</schema>
<schema name="JG4DB" checkSQLschema="false" sqlMaxLimit="100">
<table name="user" primaryKey="id" autoIncrement="true" dataNode="jg4dn" />
<table name="user_order" primaryKey="id" autoIncrement="true" dataNode="jg4dn" />
</schema>
<schema name="JG5DB" checkSQLschema="false" sqlMaxLimit="100">
<table name="user" primaryKey="id" autoIncrement="true" dataNode="jg5dn" />
<table name="user_order" primaryKey="id" autoIncrement="true" dataNode="jg5dn" />
</schema>
<dataNode name="gdn" dataHost="globalhost" database="wymglobal" />
<dataNode name="jg1dn" dataHost="g1host" database="jg1" />
<dataNode name="jg2dn" dataHost="g1host" database="jg2" />
<dataNode name="jg3dn" dataHost="g2host" database="jg3" />
<dataNode name="jg4dn" dataHost="g2host" database="jg4" />
<dataNode name="jg5dn" dataHost="g2host" database="jg5" />
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1783
1783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









