






 本文详细介绍了如何从操作系统初始化配置开始,逐步搭建Kubernetes集群,包括etcd集群的部署、Docker引擎的安装、Master和Worker Node组件的配置、CNI网络组件如Flannel和Calico的部署,以及CoreDNS的安装。此外,还涵盖了多双Master集群的搭建和Nginx+keeplived的配置,确保高可用性。最后,通过Dashboard实现了Pod的创建和管理。
本文详细介绍了如何从操作系统初始化配置开始,逐步搭建Kubernetes集群,包括etcd集群的部署、Docker引擎的安装、Master和Worker Node组件的配置、CNI网络组件如Flannel和Calico的部署,以及CoreDNS的安装。此外,还涵盖了多双Master集群的搭建和Nginx+keeplived的配置,确保高可用性。最后,通过Dashboard实现了Pod的创建和管理。
目录
上传 etcd-v3.4.9-linux-amd64.tar.gz 到 /opt/k8s 目录中,启动etcd服务
部署 Calico #Flannel和Calico部署一个就行
把master01的k8s的master组件的工作目录复制到master02
把主节点nginx配置文件和keepalived配置文件复制到备节点
创建service account并绑定默认cluster-admin管理员集群角色
| 服务器类型 | 系统和IP地址 | 备注 |
|---|---|---|
| master01 | CentOS7.4(64 位) 192.168.217.100 | kube-apiserver,kube-controller-manager,kube-scheduler,etcd |
| node1 | CentOS7.4(64 位) 192.168.217.110 | kubelet,kube-proxy,docker etcd |
| node2 | CentOS7.4(64 位) 192.168.217.120 | kubelet,kube-proxy,docker etcd |
| master02 | CentOS7.4(64 位) 192.168.217.130 | kube-apiserver,kube-controller-manager,kube-scheduler,etcd |
| nginx01 | CentOS7.4(64 位) 192.168.217.140 | Nginx ,keepalived |
| nginx02 | CentOS7.4(64 位) 192.168.217.150 | Nginx ,keepalived |
操作系统初始化配置
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
关闭selinux
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
或
vim /etc/fstab #swap 
根据规划设置主机名
hostnamectl set-hostname master01
hostnamectl set-hostname node01
hostnamectl set-hostname node02在master添加hosts
vim /etc/hosts
192.168.217.100 master01
192.168.217.110 node01
192.168.217.120 node02
调整内核参数
vim /etc/sysctl.d/k8s.conf
#开启网桥模式,可将网桥的流量传递给iptables链
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
#关闭ipv6协议
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
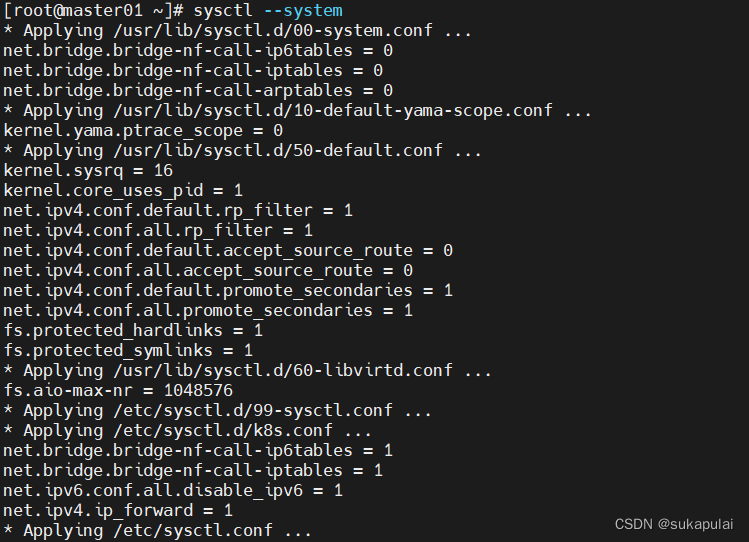
sysctl --system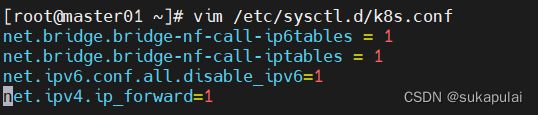
时间同步
yum install ntpdate -y
ntpdate time.windows.com
crontab -e
*/30 * * * * /usr/sbin/ntpdate time.wendows.com

部署 etcd 集群
etcd是Coreos团队于2013年6月发起的开源项目,的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd是go语言编写的。
etcd作为服务发现系统,有以下的特点: 简单:安装配置简单,而且提供了HTTPAPI进行交互,使用也很简单 安全:支持SSL证书验证 快速:单实例支持每秒2k+读操作 可靠:采用raft算法,实现分布式系统数据的可用性和一致性
etcd 目前默认使用2379端口提供日TTPAPI服务,2380端口和peer通信(这两个端口已经被IANA(互联网数字分配机构)官方预留给etcd)。 即etcd默认使用2379端口对外为客户端提供通讯,使用端口2380来进行服务器间内部通讯。 etcd 在生产环境中一般推荐集群方式部署。由于etcd的leader选举机制,要求至少为3台或以上的奇数台。
准备签发证书环境
CFSSL是CloudFlare公司开源的一款PKI/TLS工具。CFSSL,包含一个命令行工具和一个用于签名、验证和捆绑TLS证书的HTTP API服务。使用Go语言编 CFSSL使用配置文件生成证书,因此自签之前,需要生成它识别的json格式的配置文件,CFSSL提供了方便的命令行生成配置文件。 CFSSL用来为etcd提供TLS证书,它支持签三种类型的证书: 1、client 证书,服务端连接客户端时携带的证书,用于客户端验证服务端身份,如kube-apiserver访问etcd; 2、server证书,客户端连接服务端时携带的证书,用于服务端验证客户端身份,如etcd对外提供服务; 3、peer证书,相互之间连接时使用的证书,如etcd节点之间进行验证和通信。 这里全部都使用同一套证书认证。
在 master01 节点上操作
准备cfssl证书生成工具
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -O /usr/local/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -O /usr/local/bin/cfssljson
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -O /usr/local/bin/cfssl-certinfo
chmod +x /usr/local/bin/*
cfss1:证书签发的工具命令
cfssljson:将cfss1生成的证书(json格式)变为文件承载式证书
cfssl-certinfo:验证证书的信息
cfssl-certinfo-cert<证书名称> #查看证书的信息
生成Etcd证书
mkdir /opt/k8s
cd /opt/k8s/
vim etcd-cert.sh
#!/bin/bash
#配置证书生成策略,让 CA 软件知道颁发有什么功能的证书,生成用来签发其他组件证书的根证书
cat > ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
#ca-config.json:可以定义多个 profiles,分别指定不同的过期时间、使用场景等参数;
#后续在签名证书时会使用某个 profile;此实例只有一个 www 模板。
#expiry:指定了证书的有效期,87600h 为10年,如果用默认值一年的话,证书到期后集群会立即宕掉
#signing:表示该证书可用于签名其它证书;生成的 ca.pem 证书中 CA=TRUE;
#key encipherment:表示使用非对称密钥加密,如 RSA 加密;
#server auth:表示client可以用该 CA 对 server 提供的证书进行验证;
#client auth:表示server可以用该 CA 对 client 提供的证书进行验证;
#注意标点符号,最后一个字段一般是没有逗号的。
#-----------------------
#生成CA证书和私钥(根证书和私钥)
#特别说明: cfssl和openssl有一些区别,openssl需要先生成私钥,然后用私钥生成请求文件,最后生成签名的证书和私钥等,但是cfssl可以直接得到请求文件。
cat > ca-csr.json <<EOF
{
"CN": "etcd",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
EOF
#CN:Common Name,浏览器使用该字段验证网站或机构是否合法,一般写的是域名
#key:指定了加密算法,一般使用rsa(size:2048)
#C:Country,国家
#ST:State,州,省
#L:Locality,地区,城市
#O: Organization Name,组织名称,公司名称
#OU: Organization Unit Name,组织单位名称,公司部门
cfssl gencert -initca ca-csr.json | cfssljson -bare ca
#生成的文件:
#ca-key.pem:根证书私钥
#ca.pem:根证书
#ca.csr:根证书签发请求文件
#cfssl gencert -initca <CSRJSON>:使用 CSRJSON 文件生成生成新的证书和私钥。如果不添加管道符号,会直接把所有证书内容输出到屏幕。
#注意:CSRJSON 文件用的是相对路径,所以 cfssl 的时候需要 csr 文件的路径下执行,也可以指定为绝对路径。
#cfssljson 将 cfssl 生成的证书(json格式)变为文件承载式证书,-bare 用于命名生成的证书文件。
#-----------------------
#生成 etcd 服务器证书和私钥
cat > server-csr.json <<EOF
{
"CN": "etcd",
"hosts": [
"192.168.217.100",
"192.168.217.110",
"192.168.217.120"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}
EOF
#hosts:将所有 etcd 集群节点添加到 host 列表,需要指定所有 etcd 集群的节点 ip 或主机名不能使用网段,新增 etcd 服务器需要重新签发证书。
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
#生成的文件:
#server.csr:服务器的证书请求文件
#server-key.pem:服务器的私钥
#server.pem:服务器的数字签名证书
#-config:引用证书生成策略文件 ca-config.json
#-profile:指定证书生成策略文件中的的使用场景,比如 ca-config.json 中的 www
vim etcd.sh
#!/bin/bash
#example: ./etcd.sh etcd01 192.168.217.100 etcd02=https://192.168.217.110:2380,etcd03=https://192.168.217.120:2380
#创建etcd配置文件/opt/etcd/cfg/etcd
ETCD_NAME=$1
ETCD_IP=$2
ETCD_CLUSTER=$3
WORK_DIR=/opt/etcd
cat > $WORK_DIR/cfg/etcd <<EOF
#[Member]
ETCD_NAME="${ETCD_NAME}"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://${ETCD_IP}:2380"
ETCD_LISTEN_CLIENT_URLS="https://${ETCD_IP}:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://${ETCD_IP}:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://${ETCD_IP}:2379"
ETCD_INITIAL_CLUSTER="etcd01=https://${ETCD_IP}:2380,${ETCD_CLUSTER}"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
#Member:成员配置
#ETCD_NAME:节点名称,集群中唯一。成员名字,集群中必须具备唯一性,如etcd01
#ETCD_DATA_DIR:数据目录。指定节点的数据存储目录,这些数据包括节点ID,集群ID,集群初始化配置,Snapshot文件,若未指定-wal-dir,还会存储WAL文件;如果不指定会用缺省目录
#ETCD_LISTEN_PEER_URLS:集群通信监听地址。用于监听其他member发送信息的地址。ip为全0代表监听本机所有接口
#ETCD_LISTEN_CLIENT_URLS:客户端访问监听地址。用于监听etcd客户发送信息的地址。ip为全0代表监听本机所有接口
#Clustering:集群配置
#ETCD_INITIAL_ADVERTISE_PEER_URLS:集群通告地址。其他member使用,其他member通过该地址与本member交互信息。一定要保证从其他member能可访问该地址。静态配置方式下,该参数的value一定要同时在--initial-cluster参数中存在
#ETCD_ADVERTISE_CLIENT_URLS:客户端通告地址。etcd客户端使用,客户端通过该地址与本member交互信息。一定要保证从客户侧能可访问该地址
#ETCD_INITIAL_CLUSTER:集群节点地址。本member使用。描述集群中所有节点的信息,本member根据此信息去联系其他member
#ETCD_INITIAL_CLUSTER_TOKEN:集群Token。用于区分不同集群。本地如有多个集群要设为不同
#ETCD_INITIAL_CLUSTER_STATE:加入集群的当前状态,new是新集群,existing表示加入已有集群。
#创建etcd.service服务管理文件
cat > /usr/lib/systemd/system/etcd.service <<EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=${WORK_DIR}/cfg/etcd
ExecStart=${WORK_DIR}/bin/etcd \
--cert-file=${WORK_DIR}/ssl/server.pem \
--key-file=${WORK_DIR}/ssl/server-key.pem \
--trusted-ca-file=${WORK_DIR}/ssl/ca.pem \
--peer-cert-file=${WORK_DIR}/ssl/server.pem \
--peer-key-file=${WORK_DIR}/ssl/server-key.pem \
--peer-trusted-ca-file=${WORK_DIR}/ssl/ca.pem \
--logger=zap \
--enable-v2
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
#--enable-v2:开启 etcd v2 API 接口。当前 flannel 版本不支持 etcd v3 通信
#--logger=zap:使用 zap 日志框架。zap.Logger 是go语言中相对日志库中性能最高的
#--peer开头的配置项用于指定集群内部TLS相关证书(peer 证书),这里全部都使用同一套证书认证
#不带--peer开头的的参数是指定 etcd 服务器TLS相关证书(server 证书),这里全部都使用同一套证书认证
systemctl daemon-reload
systemctl enable etcd
systemctl restart etcd
chmod +x etcd-cert.sh etcd.sh
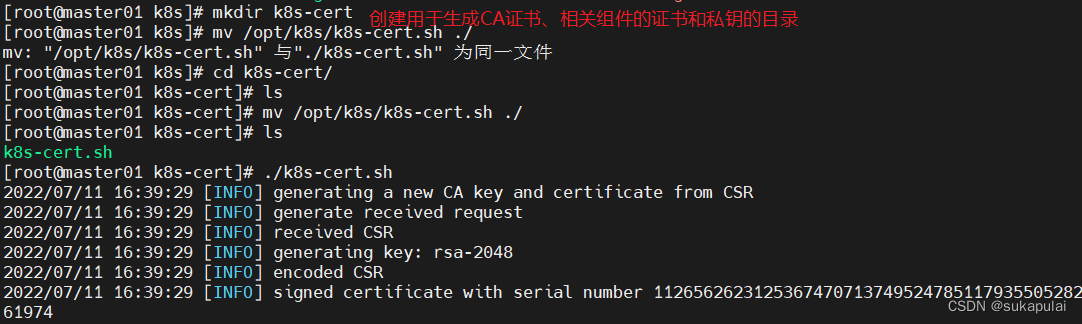
./etcd-cert.sh #创建用于生成CA证书、etcd 服务器证书以及私钥的目录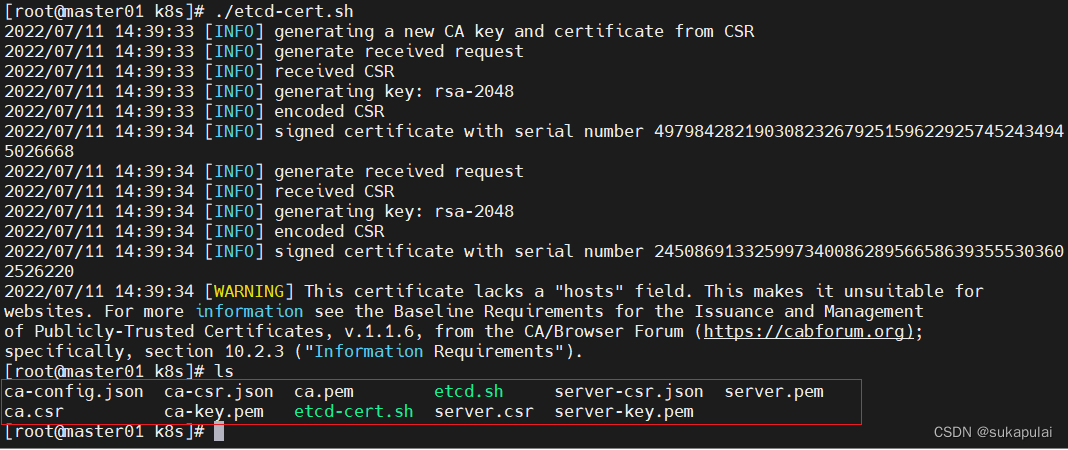
上传 etcd-v3.4.9-linux-amd64.tar.gz 到 /opt/k8s 目录中,启动etcd服务
cd /opt/k8s/
tar zxvf etcd-v3.4.9-linux-amd64.tar.gz
----------------------
etcd就是etcd服务的启动命令,后面可跟各种启动参数
etcdct1主要为etcd服务提供了命令行操作
----------------------
创建用于存放etcd配置文件,命令文件,证书的目录
mkdir -p /opt/etcd/{cfg,bin,ssl}
cd /opt/k8s/etcd-v3.4.9-linux-amd64/
mv etcd etcdctl /opt/etcd/bin/
cp /opt/k8s/etcd-cert/*.pem /opt/etcd/ssl/
cd /opt/k8s/
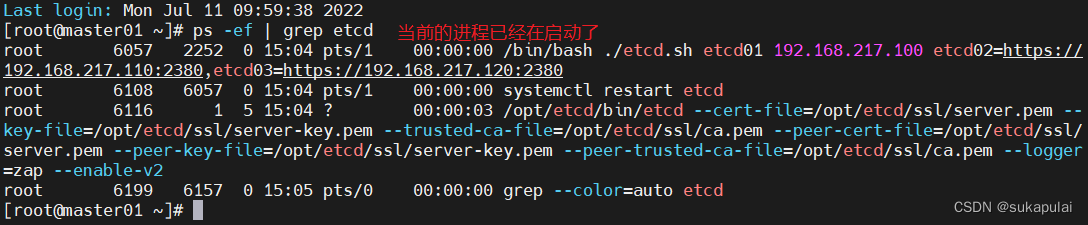
./etcd.sh etcd01 192.168.217.100 etcd02=https://192.168.217.110:2380,etcd03=https://192.168.217.120:2380
#进入卡住状态等待其他节点加入,这里需要三台etcd服务同时启动,如果只启动其中一台后,服务会卡在那里,直到集群中所有etcd节点都已启动,可忽略这个情况
#可另外打开一个窗口查看etcd进程是否正常
ps -ef | grep etcd
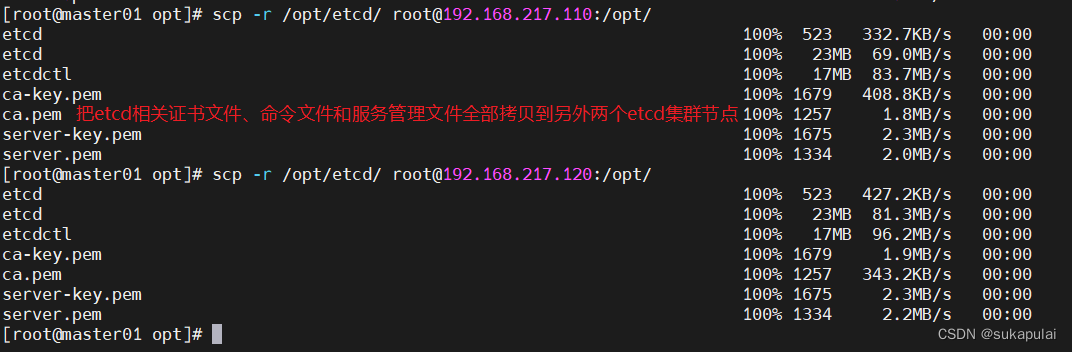
#把etcd相关证书文件、命令文件和服务管理文件全部拷贝到另外两个etcd集群节点
scp -r /opt/etcd/ root@192.168.217.110:/opt/
scp -r /opt/etcd/ root@192.168.217.120:/opt/
cd /usr/lib/systemd/system
scp etcd.service root@192.168.217.110:`pwd`
scp etcd.service root@192.168.217.120:`pwd`






在 node01 节点上操作
vim /opt/etcd/cfg/etcd
#[Member]
ETCD_NAME="etcd02" #修改
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.217.110:2380" #修改
ETCD_LISTEN_CLIENT_URLS="https://192.168.217.110:2379" #修改
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.217.110:2380" #修改
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.217.110:2379" #修改
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.217.100:2380,etcd02=https://192.168.217.110:2380,etcd03=https://192.168.217.120:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
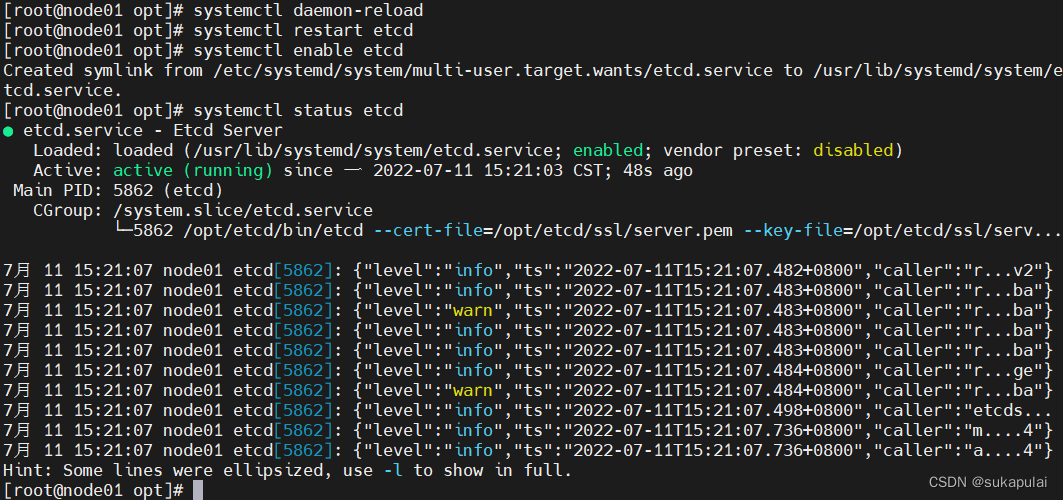
systemctl daemon-reload
systemctl restart etcd
systemctl enable etcd
systemctl status etcd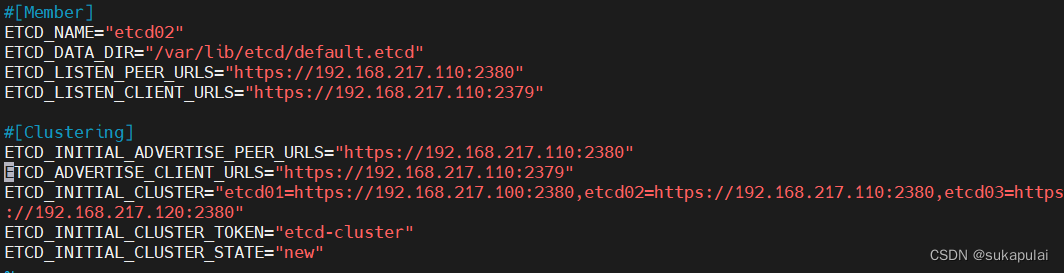
在 node02 节点上操作
vim /opt/etcd/cfg/etcd
#[Member]
ETCD_NAME="etcd03" #修改
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.217.120:2380" #修改
ETCD_LISTEN_CLIENT_URLS="https://192.168.217.120:2379" #修改
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.217.120:2380" #修改
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.217.120:2379" #修改
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.217.100:2380,etcd02=https://192.168.217.110:2380,etcd03=https://192.168.217.120:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
systemctl daemon-reload
systemctl restart etcd
systemctl enable etcd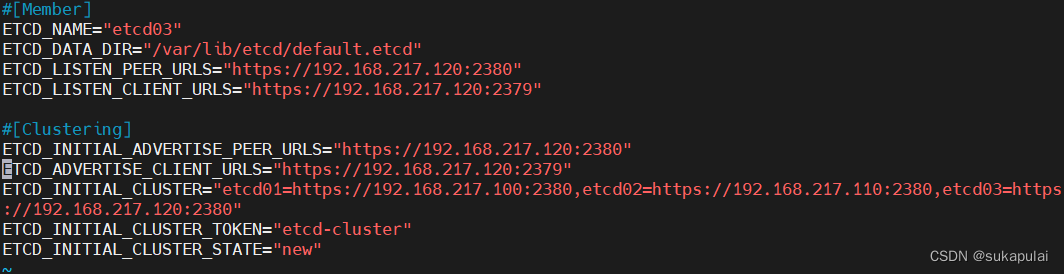
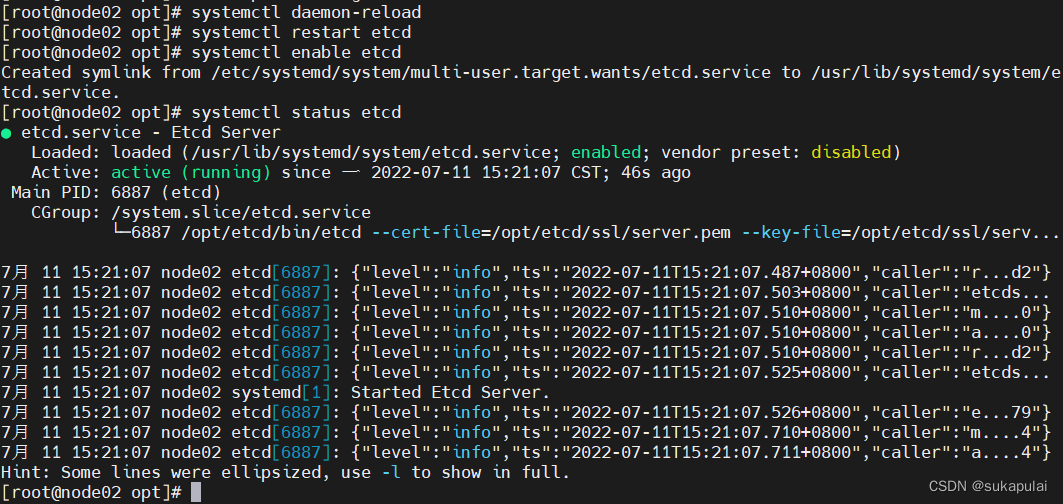
检查etcd群集状态
cd /opt/etcd/ssl
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=ca.pem --cert=server.pem --key=server-key.pem --endpoints="https://192.168.217.100:2379,https://192.168.217.110:2379,https://192.168.217.120:2379" endpoint health --write-out=table
-------------------------------------------------
--cert-file:识别HTTPS端使用SSL证书文件
--key-file:使用此SSt密钥文件标识HTTPS客户端
--ca-file:使用此CA证书验证启用https的服务器的证书
--endpoints:集群中以逗号分隔的机器地址列表
cluster-health:检查etcd集群的运行状况
-------------------------------------------------
etcd用https进行访问一定要指定证书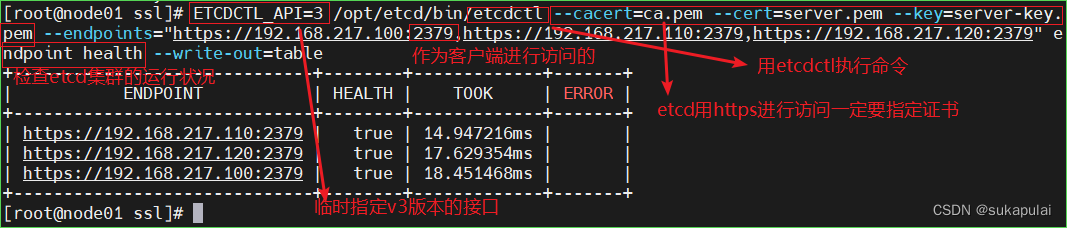
部署 docker引擎
//所有 node 节点部署docker引擎
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce docker-ce-cli containerd.io
systemctl start docker.service
systemctl enable docker.service 部署 Master 组件
在 master01 节点上操作
#上传 master.zip 和 k8s-cert.sh 到 /opt/k8s 目录中,解压 master.zip 压缩包
cd /opt/k8s/
unzip master.zip
chmod +x *.sh
#创建用于生成CA证书、相关组件的证书和私钥的目录
vim k8s-cert.sh
-----------------------------------------------------------
#!/bin/bash
#配置证书生成策略,让 CA 软件知道颁发有什么功能的证书,生成用来签发其他组件证书的根证书
cat > ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
#生成CA证书和私钥(根证书和私钥)
cat > ca-csr.json <<EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
#-----------------------
#生成 apiserver 的证书和私钥(apiserver和其它k8s组件通信使用)
#hosts中将所有可能作为 apiserver 的 ip 添加进去,后面 keepalived 使用的 VIP 也要加入
cat > apiserver-csr.json <<EOF
{
"CN": "kubernetes",
"hosts": [
"10.0.0.1",
"127.0.0.1",
"192.168.217.100", #master01
"192.168.217.130", #master02
"192.168.217.50", #vip,后面 keepalived 使用
"192.168.217.140", #load balancer01(master)
"192.168.217.150", #load balancer02(backup)
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes apiserver-csr.json | cfssljson -bare apiserver
#-----------------------
#生成 kubectl 连接集群的证书和私钥,具有admin权限
cat > admin-csr.json <<EOF
{
"CN": "admin",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes admin-csr.json | cfssljson -bare admin
#-----------------------
#生成 kube-proxy 的证书和私钥
cat > kube-proxy-csr.json <<EOF
{
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
----------------------------------------------------------
cd /opt
mkdir -p kubernetes/{bin,cfg,ssl,logs}
cd /opt/k8s
mkdir k8s-cert
mv /opt/k8s/k8s-cert.sh ./
cd /opt/k8s/k8s-cert/
./k8s-cert.sh
ls *pem
admin-key.pem apiserver-key.pem ca-key.pem kube-proxy-key.pem
admin.pem apiserver.pem ca.pem kube-proxy.pem
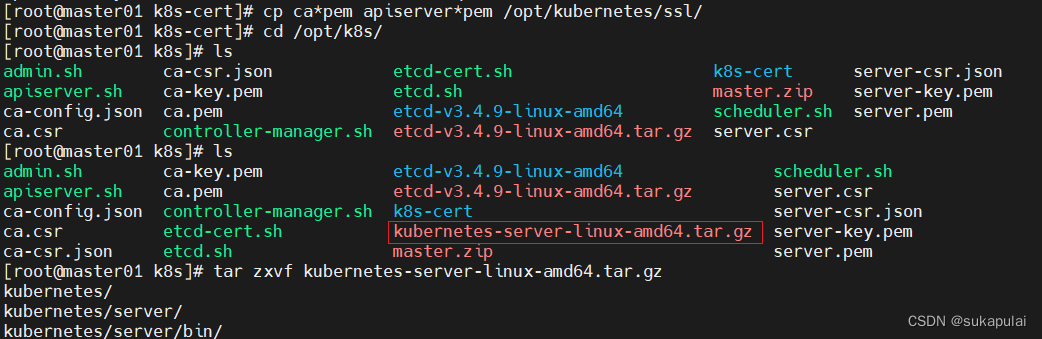
cp ca*pem apiserver*pem /opt/kubernetes/ssl/
#上传 kubernetes-server-linux-amd64.tar.gz 到 /opt/k8s/ 目录中,解压 kubernetes 压缩包
cd /opt/k8s/
tar zxvf kubernetes-server-linux-amd64.tar.gz
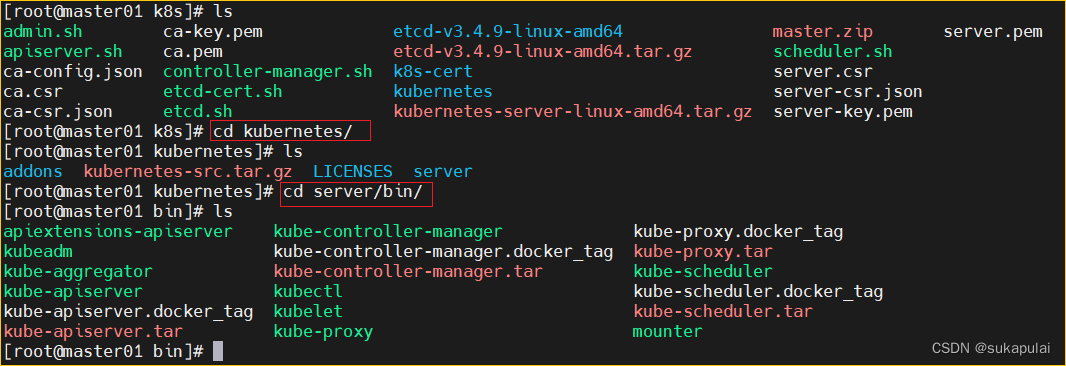
cd /opt/k8s/kubernetes/server/bin
scp kube-apiserver kubectl kube-controller-manager kube-scheduler /opt/kubernetes/bin/
ln -s /opt/kubernetes/bin/* /usr/local /bin/
#获取随机数前16个字节内容,以十六进制格式输出,并删除其中空格
head -c 16 /dev/urandom | od -An -t x | tr -d ' '
cd /opt/kubernetes/cfg
vim token.csv
#编写 token.csv 文件,按照 Token序列号,用户名,UID,用户组 的格式生成
bcae51383d5a73c200a7fd1c2350747a,kubelet-bootstrap,10001,"system:kubelet-bootstrap"
cd /opt/k8s/
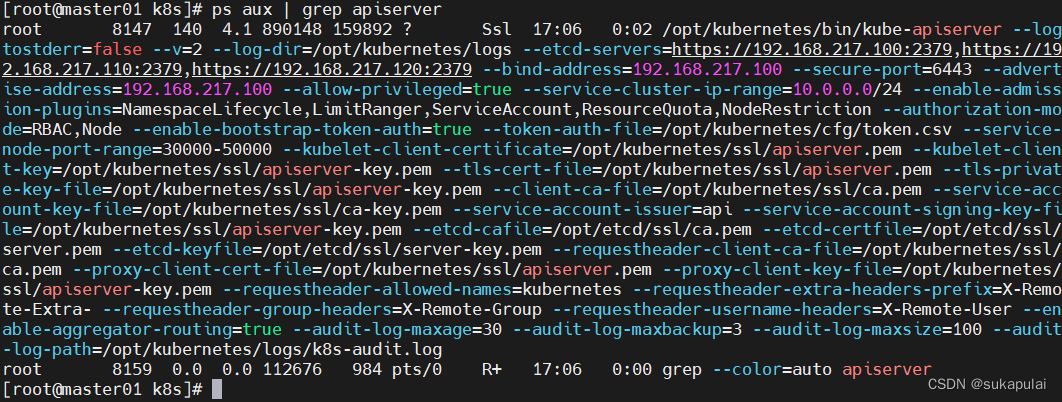
./apiserver.sh 192.168.217.100 https://192.168.217.100:2379,https://192.168.217.110:2379,https://192.168.217.120:2379
ps aux | grep kube-apiserver
netstat -nltp |grep api #安全端口6443用于接收HTTPS请求,用于基于Token文件或客户端证书等认证
cd /opt/k8s/
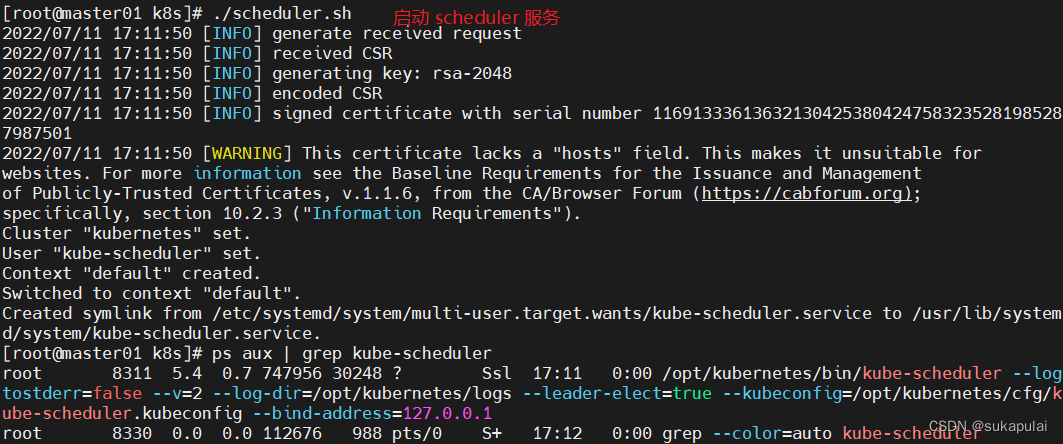
#启动 scheduler 服务
./scheduler.sh
ps aux | grep kube-scheduler
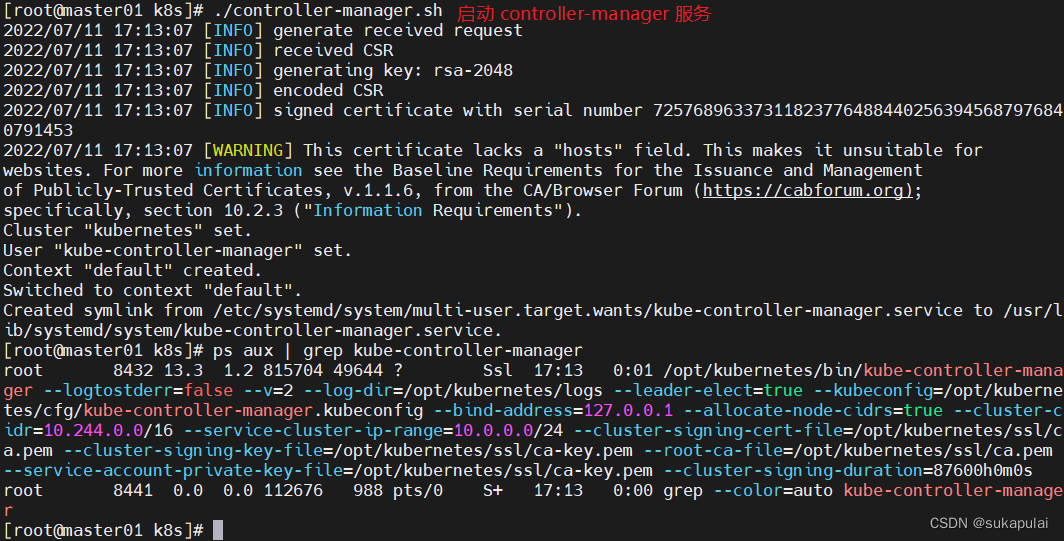
#启动 controller-manager 服务
./controller-manager.sh
ps aux | grep kube-controller-manager
#生成kubectl连接集群的证书
./admin.sh
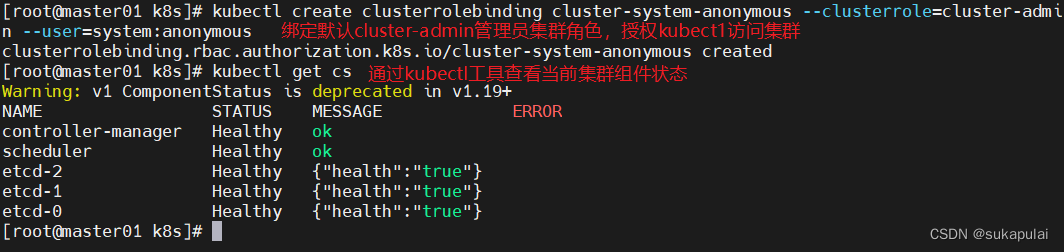
绑定默认cluster-admin管理员集群角色,授权kubect1访问集群
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
#通过kubectl工具查看当前集群组件状态
kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-2 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
#查看版本信息
kubectl version






部署 Worker Node 组件
在所有 node 节点上操作
#创建kubernetes工作目录
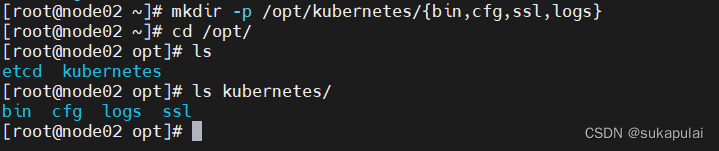
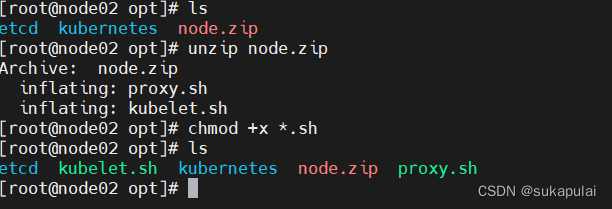
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
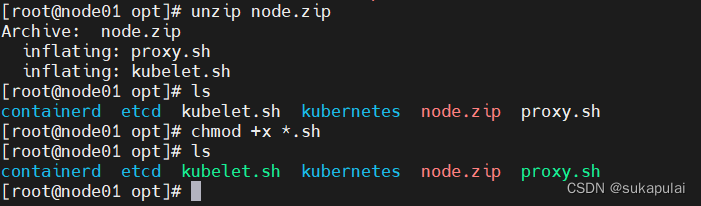
#上传 node.zip 到 /opt 目录中,解压 node.zip 压缩包,获得kubelet.sh、proxy.sh
cd /opt/
unzip node.zip
chmod +x *.sh
在 master01 节点上操作
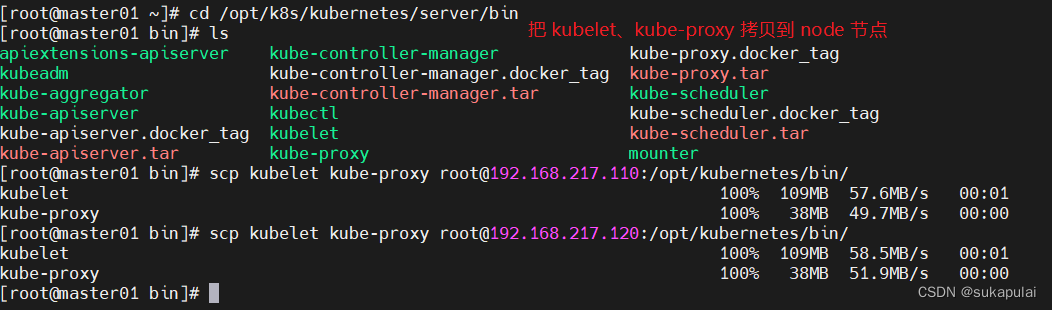
#把 kubelet、kube-proxy 拷贝到 node 节点
cd /opt/k8s/kubernetes/server/bin
scp kubelet kube-proxy root@192.168.217.110:/opt/kubernetes/bin/
scp kubelet kube-proxy root@192.168.217.120:/opt/kubernetes/bin/
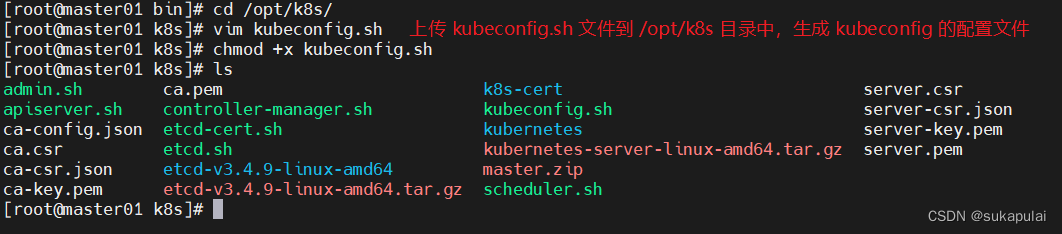
#上传 kubeconfig.sh 文件到 /opt/k8s 目录中,生成 kubeconfig 的配置文件
#kubeconfig 文件包含集群参数(CA证书、API Server地址),客户端参数(上面生成的证书和私钥),集群context 上下文参数(集群名称、用户名)。
Kubenetes组件(如kubelet、kube-proxy)通过启动时指定不同的kubeconfig文件可以切换到不同的集群,连接到apiserver。
cd /opt/k8s/
vim kubeconfig.sh
------------------------------------------------------------
#!/bin/bash
#example: kubeconfig 192.168.80.10 /opt/k8s/k8s-cert/
#创建bootstrap.kubeconfig文件
#该文件中内置了 token.csv 中用户的 Token,以及 apiserver CA 证书;kubelet 首次启动会加载此文件,使用 apiserver CA 证书建立与 apiserver 的 TLS 通讯,使用其中的用户 Token 作为身份标识向 apiserver 发起 CSR 请求
BOOTSTRAP_TOKEN=$(awk -F ',' '{print $1}' /opt/kubernetes/cfg/token.csv)
APISERVER=$1
SSL_DIR=$2
export KUBE_APISERVER="https://$APISERVER:6443"
# 设置集群参数
kubectl config set-cluster kubernetes \
--certificate-authority=$SSL_DIR/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=bootstrap.kubeconfig
#--embed-certs=true:表示将ca.pem证书写入到生成的bootstrap.kubeconfig文件中
# 设置客户端认证参数,kubelet 使用 bootstrap token 认证
kubectl config set-credentials kubelet-bootstrap \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=bootstrap.kubeconfig
# 设置上下文参数
kubectl config set-context default \
--cluster=kubernetes \
--user=kubelet-bootstrap \
--kubeconfig=bootstrap.kubeconfig
# 使用上下文参数生成 bootstrap.kubeconfig 文件
kubectl config use-context default --kubeconfig=bootstrap.kubeconfig
#----------------------
#创建kube-proxy.kubeconfig文件
# 设置集群参数
kubectl config set-cluster kubernetes \
--certificate-authority=$SSL_DIR/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-proxy.kubeconfig
# 设置客户端认证参数,kube-proxy 使用 TLS 证书认证
kubectl config set-credentials kube-proxy \
--client-certificate=$SSL_DIR/kube-proxy.pem \
--client-key=$SSL_DIR/kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=kube-proxy.kubeconfig
# 设置上下文参数
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=kube-proxy.kubeconfig
# 使用上下文参数生成 kube-proxy.kubeconfig 文件
kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
------------------------------------------------------------
chmod +x kubeconfig.sh
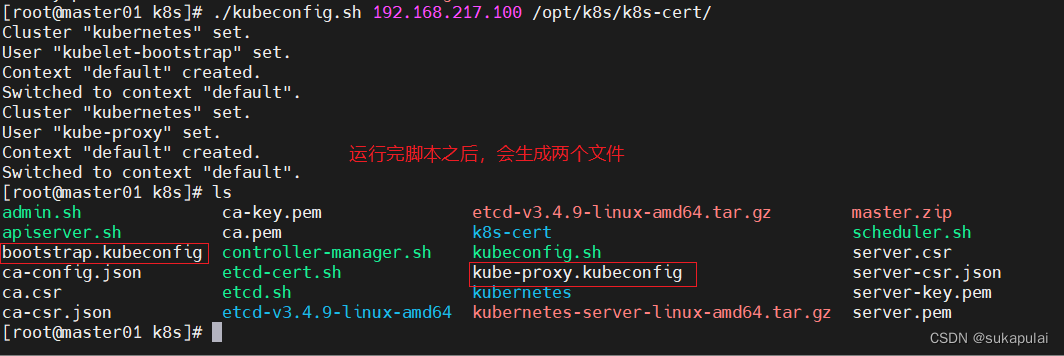
./kubeconfig.sh 192.168.217.100 /opt/k8s/k8s-cert/
#把配置文件bootstrap-kubeconfig、kube-proxy.kubecontig 拷贝到node节点
scp bootstrap.kubeconfig kube-proxy.kubeconfig root@192.168.217.110:/opt/kubernetes/cfg/
scp bootstrap.kubeconfig kube-proxy.kubeconfig root@192.168.217.120:/opt/kubernetes/cfg/
#RBAC授权,使用户 kubelet-bootstrap 能够有权限发起 CSR 请求证书
kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
若执行失败,可先给kubect1绑定默认cluster-admin管理员集群角色,授权集群操作权限
kubectl create clusterrolebinding cluster-system-anonymous--clusterrole=cluster-admin--user=system:anonymous
-----------------------------------------------------------------
kubelet 采用TLS Bootstrapping 机制,自动完成到kube-apiserver的注册,在node节点量较大或者后期自动扩容时非常有用。
Master apiserver 启用TIs认证后,node节点kubelet 组件想要加入集群,必须使用CA签发的有效证书才能与apiserver通信,
当node节点很多时,签署证书是一件很繁琐的事情。因此Kubernetes引入了TLS bootstraping机制来自动颁发客户端证书,
kubelet 会以一个低权限用户自动向apiserver申请证书,kubelet 的证书由 apiserver动态签署。
kubelet 首次启动通过加载 bootstrap.kubeconfig 中的用户Token和apiserver CA证书发起首次CSR请求,这个Token被预先内置在apiserver节点的
token.csv中,其身份为kubelet-bootstrap用户和system:kubelet-bootstrap用户组;想要首次SR请求能成功(即不会被 apiserver 401
拒绝),则需要先创建一个clusterRoleBinding,将kubelet-bootstrap用户和system:node-bootstrapper内置clusterRole绑定(通过kubectl get
clusterroles可查询),使其能够发起CSR认证请求。
TLS bootstrapping 时的证书实际是由kube-controller-manager组件来签署的,也就是说证书有效期是kube-controller-manager
组件控制的;kube-controller-manager 组件提供了一个--experimental-cluster-signing-duration 参数来设置签署的证书有效时间;默认为8760h0m0s,将其改为
87600h0m0s,即10年后再进行TLS bootstrapping 签署证书即可。
也就是说kubelet 首次访问API Server时,是使用token做认证,通过后,Controller Manager会为kubelet生成一个证书,以后的访问都是用证书做认证了。
-----------------------------------------------------------------


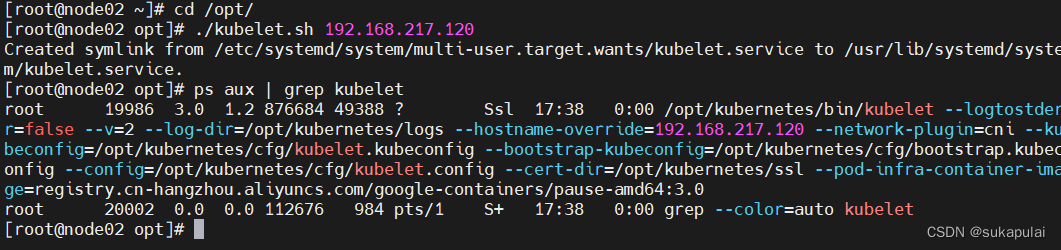
在 node01 02 节点上操作
#启动 kubelet 服务
cd /opt/
./kubelet.sh 192.168.217.110
ps aux | grep kubelet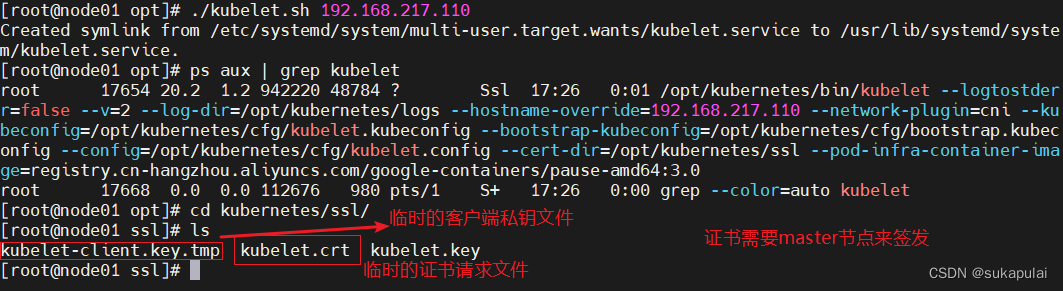
在 master01 节点上操作,通过 CSR 请求
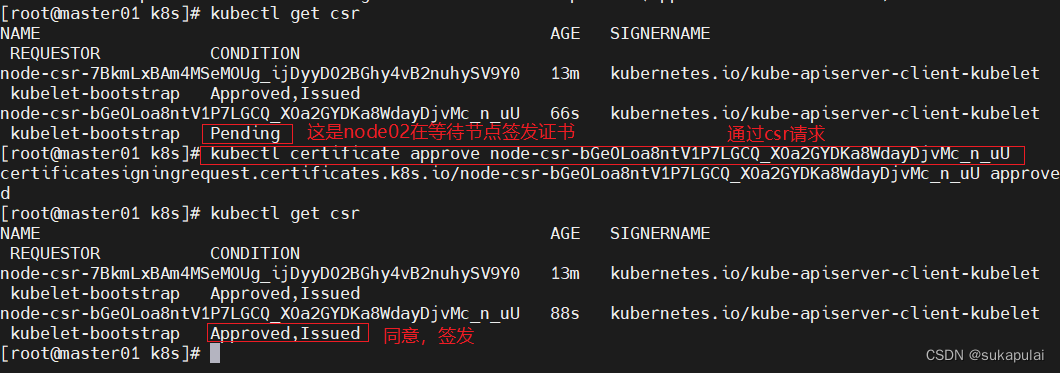
#检查到 node01 节点的 kubelet 发起的 CSR 请求,Pending 表示等待集群给该节点签发证书
kubectl get csr
Pending 集群在等待节点签发证书
#通过 CSR 请求
kubectl certificate approve node-csr-7BkmLxBAm4MSeMOUg_ijDyyDO2BGhy4vB2nuhySV9Y0
#Approved,Issued 表示已授权 CSR 请求并签发证书
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-7BkmLxBAm4MSeMOUg_ijDyyDO2BGhy4vB2nuhySV9Y0 5m28s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued
#查看节点,由于网络插件还没有部署,节点会没有准备就绪 NotReady
kubectl get node
NAME STATUS ROLES AGE VERSION
192.168.217.110 NotReady <none> 4m26s v1.20.11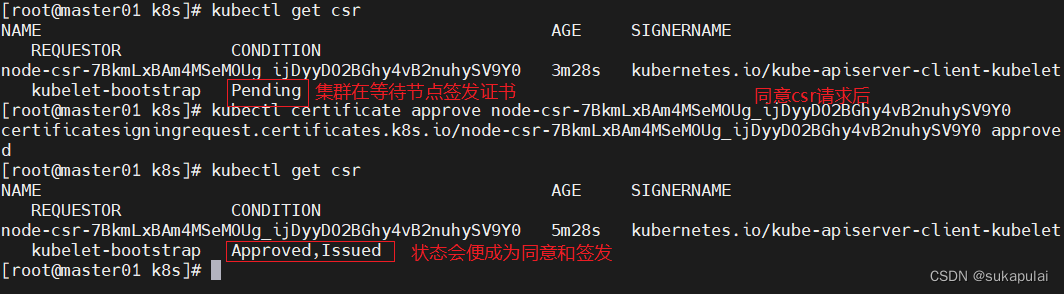




在 node01 02节点上操作
#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
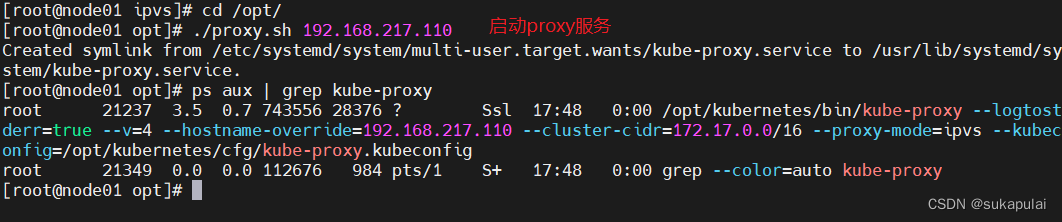
#启动proxy服务
cd /opt/
./proxy.sh 192.168.217.110
ps aux | grep kube-proxy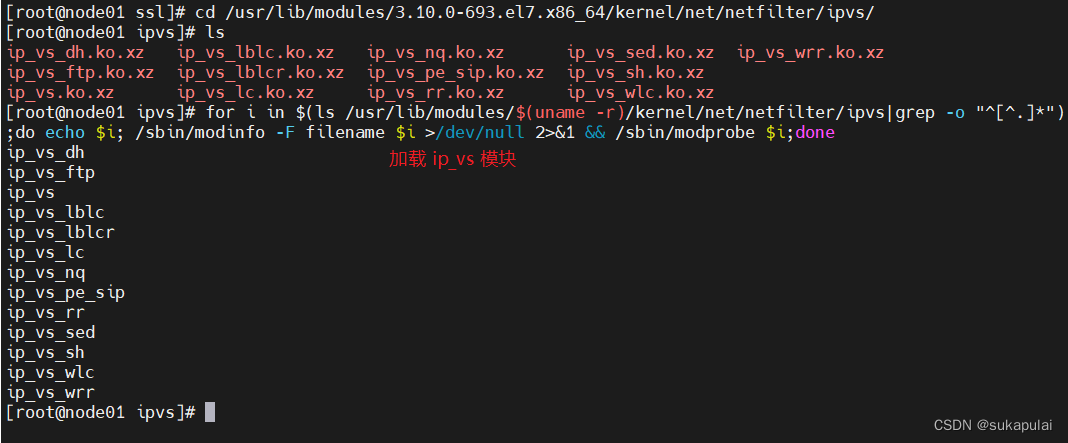
部署CNI网络组件
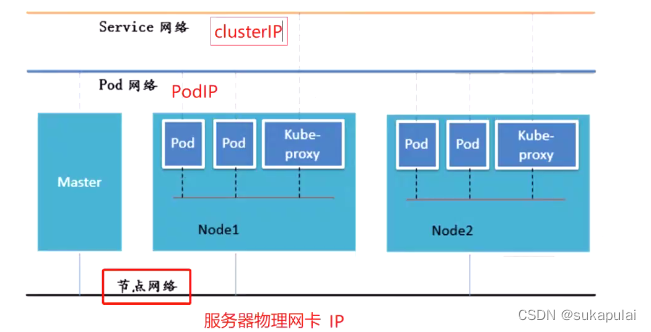
Kubernetes的三种网络
部署 flannel
K8S中Pod 网络通信:
-
Pod 内容器与容器之间的通信 在同一个pod内的容器(Pod内的容器是不会跨宿主机的)共享同一个网络命名空间,相当于它们在同一台机器上一样,可以用1ocalhost地址访问彼此的端口。
-
同一个Node内Pod之间的通信 每个pod都有一个真实的全局P地址,同一个Node内的不同Pod之间可以直接采用对方pod的IP地址进行通信,Pod1与Pod2都是通过veth连接到同一个 dockero/cni0网桥,网段相同,所以它们之间可以直接通信。
-
不同Node上Pod之间的通信 Pod 地址与dockero在同一网段,dockero网段与宿主机网卡是两个不同的网段,且不同Node之间的通信只能通过宿主机的物理网卡进行。 要想实现不同Node 上Pod之间的通信,就必须想办法通过主机的物理网卡IP地址进行寻址和通信。因此要满足两个条件:Pod的IP不能冲突;将Pod的IP和所在的Node的IP关联起来,通过这个关联让不同Node上Pod之间直接通过内网IP地址通信。
Overlay Network:
叠加网络,在二层或者三层基础网络上叠加的一种虚拟网络技术模式,该网络中的主机通过虚拟链路隧道连接起来。 通过overlay技术(可以理解成隧道技术),在原始报文外再包一层四层协议(UDP协议),通过主机网络进行路由转发。这种方式性能有一定损耗,主要体现在对原始报文的修改。目前overlay主要采用VXLAN。
VXLAN:
将源数据包封装到UDP中,并使用基础网络的IP/MAC作为外层报文头进行封装,然后在以太网上传输,到达目的地后由隧道端点解封装并将数据发送给日标地址。
Flannekl:
Flannel的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。 Flannel是overlay 网络的一种,也是将TCP源数据包封装在另一种网络包里面进行路由转发和通信,目前支持UDP、VXLAN、Host-gw3种数据转发方式。
FlannelUDP模式的工作原理:
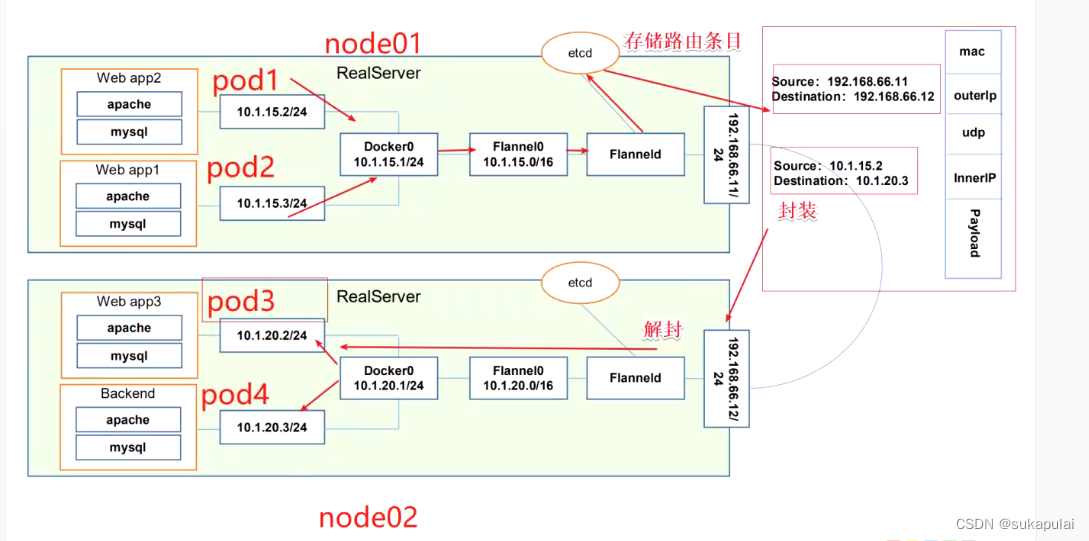
实现pod1和pod3之间的通信,首先数据从pod容器发送出来,发送到docker0网桥,接受但数据后会转发到flannel0虚拟网卡,flanneld服务监听flannel0网卡同时在etcd数据库当中维护着一张路由表,路由表里面就保存着podIP与node节点IP地址相对应的关系,想要转发哪个地址,flanneld都会通过etcd查得到,查到路由表之后,会把原来的报文给封装,封装到自己的数据包当中,发送到目标主机,目标主机发送到自己的Flanneld服务当中,对数据包进行解封装,暴露出里面的报文,里面的报文再根据IP地址,通过flannel0网卡转发到docker0,docker0转发到对应的pod容器当中
ETCD之Flannel提供说明:
存储管理Flannel可分配的IP地址段资源监控ETCD中每个pod的实际地址,并在内存中建立维护Pod节点路由表
由于UDP模式是在用户态做转发,会多一次报文隧道封装,因此性能上会比在内核态做转发的VXLAN模式差。
VXLAN模式:
VXLAN模式使用比较简单,flannel会在各节点生成一个flannel.1的VXLAN网卡(VTEP设备,负责VXLAN封装和解封装)。 VXLAN模式下封包与解包的工作是由内核进行的。flanne1不转发数据,仅动态设置P表和MAC表项。 UDP模式的flanne10网卡是三层转发,使用flanne10时在物理网络之上构建三层网络,属于ip in udp;VXLAN模式是二层实现,overlay是数据帧,属于mac in udp
FlannelVXLAN模式跨主机的工作原理:
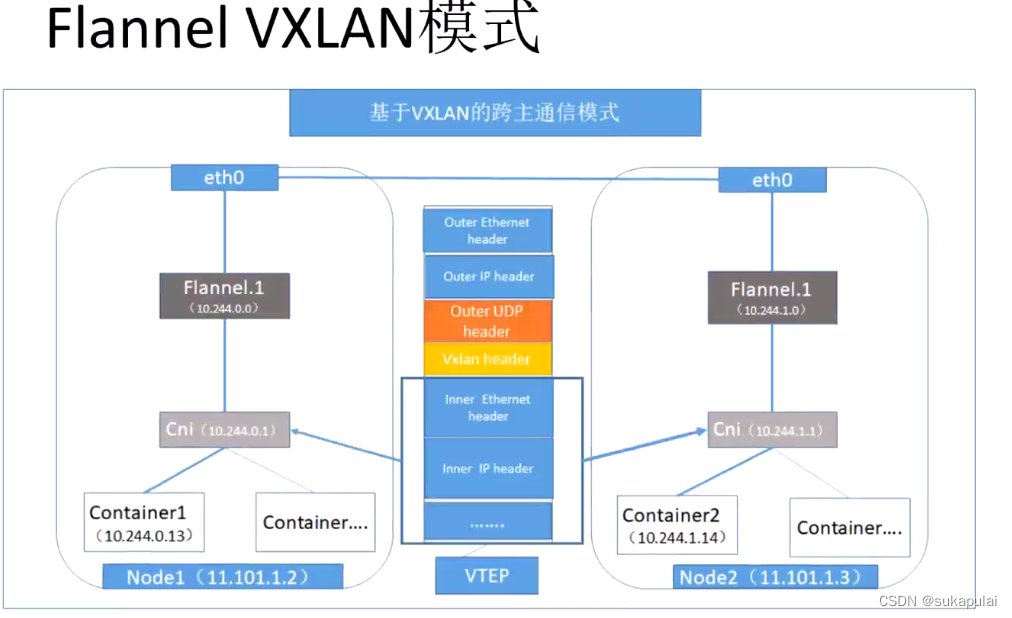
数据帧里面包含那些(数据先经过网络层,封装一个tcp头部,变成数据段,到网络层封装一个IP头部,变成数据包, 到数据链路层接收数据包 加入 MAC 头部 变成 数据帧 )
首先通过数据帧发送的,数据从容器发送出来后,到cni网络接口,由cni转发到flannel.1接口,flannel.1收到数据帧后添加VXLAN头部,封装在UDP报文中,在通过物理网卡发送到对方主机,发送时会指定4789 端口,4789端口会发送到flannel.1接口,发送过来之后flannel.1会进行内核解封装,把外面的头部和vxlan头部脱掉,暴露出内部的数据帧,内部的数据帧在根据里面的网卡进行转发,转发到目标容器当中,完成了数据跨主机的传送
在 node01 02节点上操作
#上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
mkdir /opt/cni/bin -p
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
cd /opt/
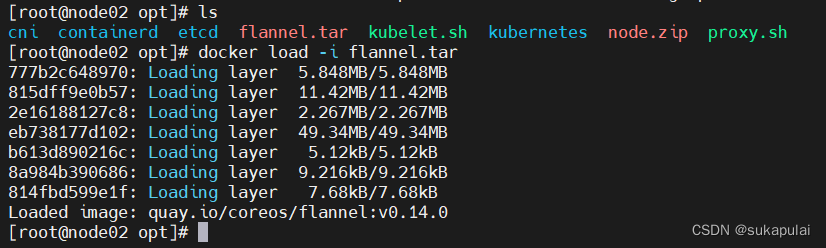
docker load -i flannel.tar
//node02节点操作
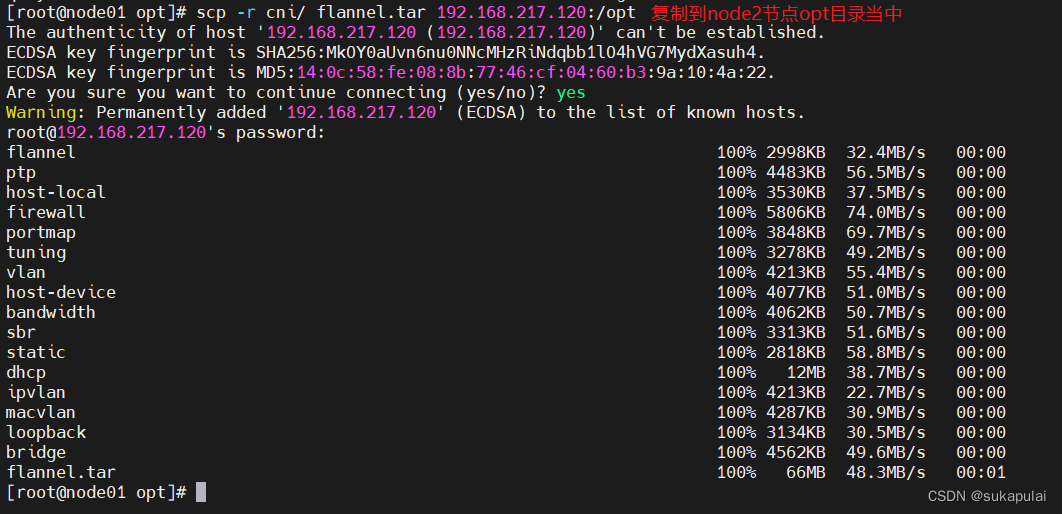
scp -r cni/ flannel.tar 192.168.217.120:/opt
docker load -i flannel.tar #把镜像加载到本地
在 master01 节点上操作
#上传 kube-flannel.yml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
kubectl apply -f kube-flannel.yml
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-hjtc7 1/1 Running 0 7s
kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.217.110 Ready <none> 81m v1.20.11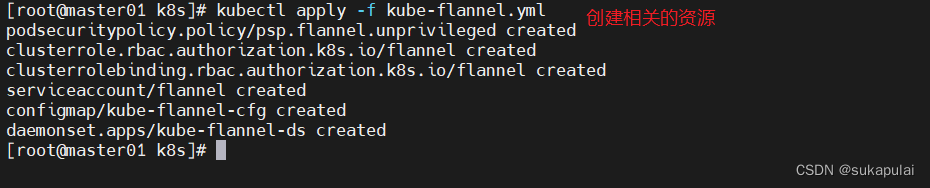


部署 Calico #Flannel和Calico部署一个就行
k8s组网方案对比:
-
flannel方案 需要在每个节点上把发向容器的数据包进行装后,再用隧道将封装后的数据包发送到运行着目标Pod的node节点上。目标node节点再负责去掉封装,将去除封装的数据包发送到目标Pod上。数据通信性能则大受影响。
-
Calico方案 Calico不使用隧道或NAT来实现转发,而是把Host当作Internet中的路由器,使用BGp同步路由,并使用iptables来做安全访问策略,完成跨Host转发来。 采用直接路由的方式,这种方式性能损耗最低,不需要修改报文数据,但是如果网络比较复杂场景下,路由表会很复杂,对运维同事提出了较高的要求。
Calico主要由三个部分组成
calico CNI插件:主要负责与kubernetes对接,供kubelet调用使用。 Felix:负责维护宿主机上的路由规则、FIB转发信息库等。 BIRD:负责分发路由规则,类似路由器。 Confd:配置管理组件。
calico工作原理
calico 是通过路由表来维护每个pod的通信。Calico的CNI插件会为每个容器设置一个veth pair设备,然后把另一端接入到宿主机网络空间,由于没有网桥,CNI还需宿主机上为每个空器的veth bair 设备配置一条路由规则,用于接收传入的Ip包有了这样的 veth pair 设备以后,容器发出的Ip包就会通过 veth pair 设备到达宿主机,然后宿主机根据路由规则的下一跳地址,发送给正确的网关,然后到达目标信主机,再到达目标容器。 这些路由规则都是Felix维护配置的,而路由信息则是Calico BIRD组件基于BGP分发而来。 calico 实际上是将集群里所有的节点都当做边界路由器来处理,他们一起组成了一个全互联的网络,彼此之间通过BGP交换路由,这些节点我们叫做BGP Peer。
目前比较常用的CNI网络组件是flannel和calico,flannel的功能比较简单,不具备复杂的网络策略配置能力,calico是比较出色的网络管理插件,但具备复杂网络配置能力的同时,往往意味着本身的配置比较复杂,所以相对而言,比较小而简单的集群使用flannel,考虑到日后扩容,未来网络可能需要加入更多设备,配置更多网络策略,则使用calico更好。
在 master01 节点上操作
#上传 calico.yaml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
vim calico.yaml
#修改里面定义Pod网络(CALICO_IPV4POOL_CIDR),与前面kube-controller-manager配置文件指定的cluster-cidr网段一样
- name: CALICO_IPV4POOL_CIDR
value: "192.168.0.0/16"
kubectl apply -f calico.yaml
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-659bd7879c-4h8vk 1/1 Running 0 58s
calico-node-nsm6b 1/1 Running 0 58s
calico-node-tdt8v 1/1 Running 0 58s
#等 Calico Pod 都 Running,节点也会准备就绪
kubectl get nodes部署 CoreDNS
CoreDNS:可以为集群中的service 资源创建一个域名与IP的对应关系解析
在所有 node 节点上操作
#上传 coredns.tar 到 /opt 目录中
cd /opt
docker load -i coredns.tar

在 master01 节点上操作
#上传 coredns.yaml 文件到 /opt/k8s 目录中,部署 CoreDNS
cd /opt/k8s
kubectl apply -f coredns.yaml
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5ffbfd976d-j6shb 1/1 Running 0 32s
#DNS 解析测试
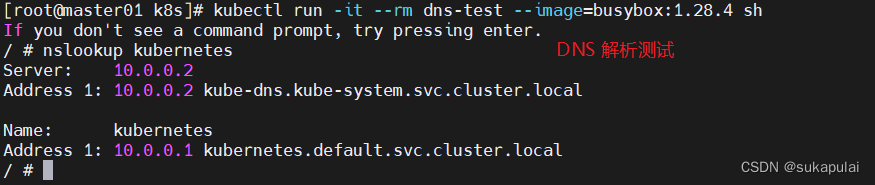
kubectl run -it --rm dns-test --image=busybox:1.28.4 sh
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes #输入资源名称可以解析到对应的IP地址
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
Kubernetes多双Master集群
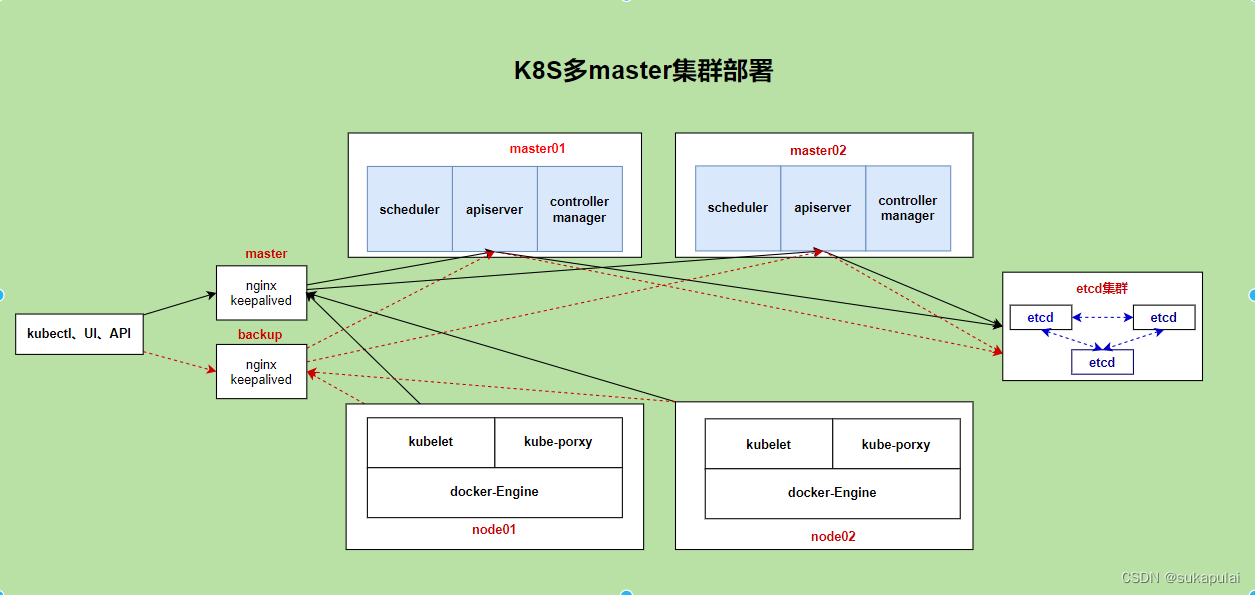
操作系统初始化配置
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X关闭selinux
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
或
vim /etc/fstab #swap 根据规划设置主机名
hostnamectl set-hostname master02在master node节点添加hosts
vim /etc/hosts
192.168.217.100 master01
192.168.217.130 master02
192.168.217.110 node01
192.168.217.120 node02把master01的k8s的master组件的工作目录复制到master02
scp -r kubernetes/ master02:/opt
#让系统识别命令
ln -s /opt/kubernetes/bin/* /usr/local/bin/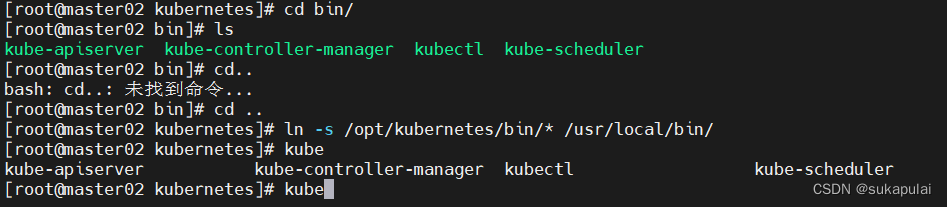
修改kube-apiserver配置文件
vim kube-apiserver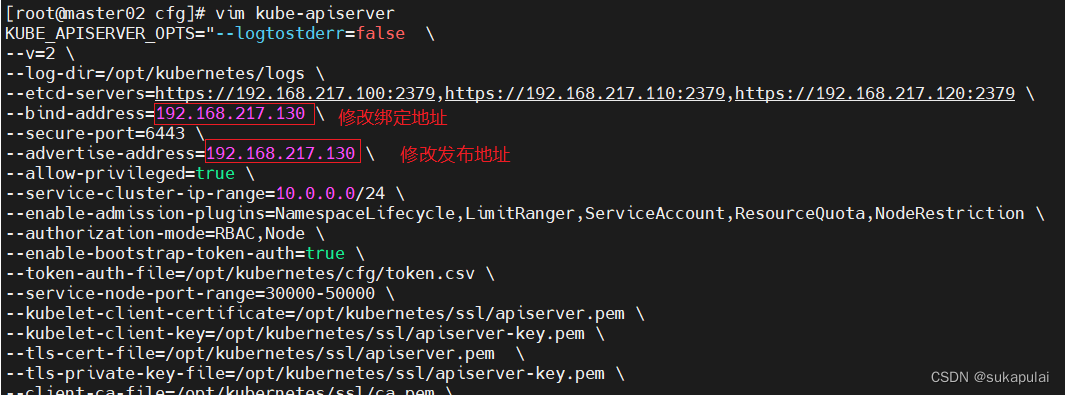
把master01的etcd证书复制到master02
scp -r etcd/ master02:/opt
使用证书进行认证
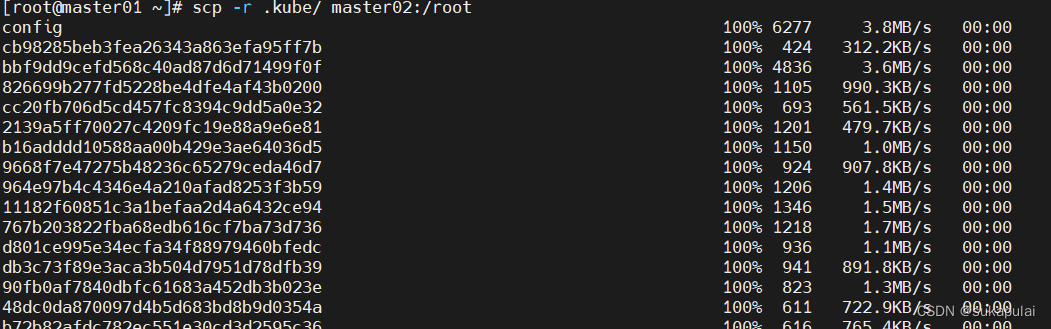
到master01节点
scp -r .kube/ master02:/root
到master02节点查看节点状态
kubectl get node

启动master上面的组件
到master01节点上把服务文件复制到master02
cd /usr/lib/systemd/system
scp kube* master02:`pwd`
在到master02启动
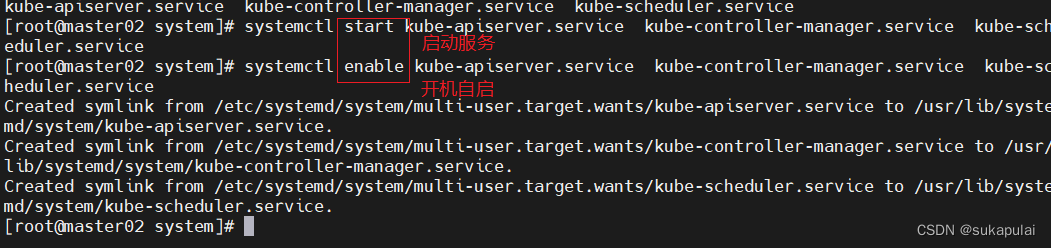
systemctl start kube-apiserver.service kube-controller-manager.service kube-scheduler.service
systemctl enable kube-apiserver.service kube-controller-manager.service kube-scheduler.service
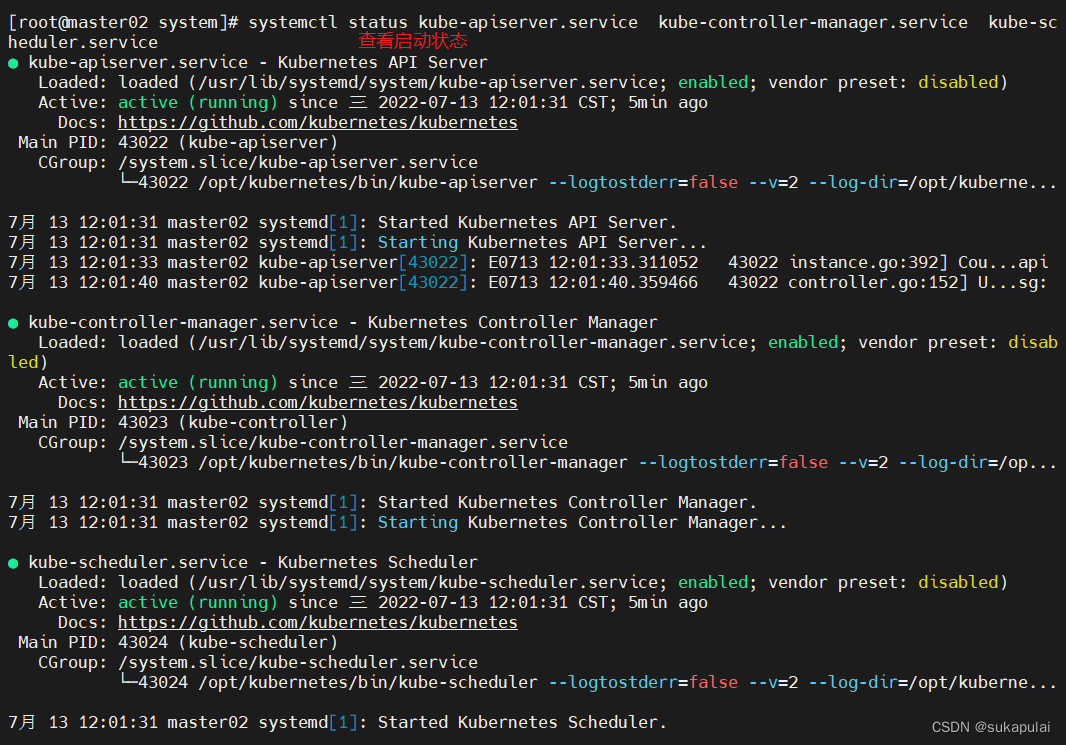
systemctl status kube-apiserver.service kube-controller-manager.service kube-scheduler.service
部署Nginx+keeplived
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0上传nginx的yum源
cd /etc/yum.repos.d/
yum install nginx -y
修改nginx配置文件
cd /etc/nginx/
vim nginx.conf
添加stream模块
stream {
upstream k8s-masters {
server 192.168.217.100:6443;
server 192.168.217.130:6443;
}
server {
listen 6443;
proxy_pass k8s-masters;
}
}
nginx -t #查看语法错误
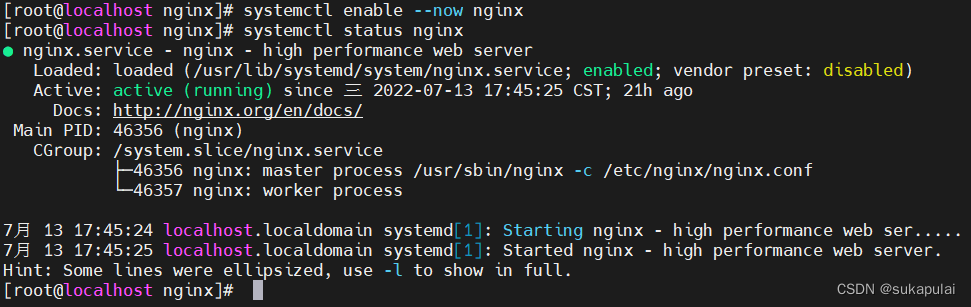
systemctl enable --now nginx #设置开机自启nginx
yum install keepalived -y #安装高可用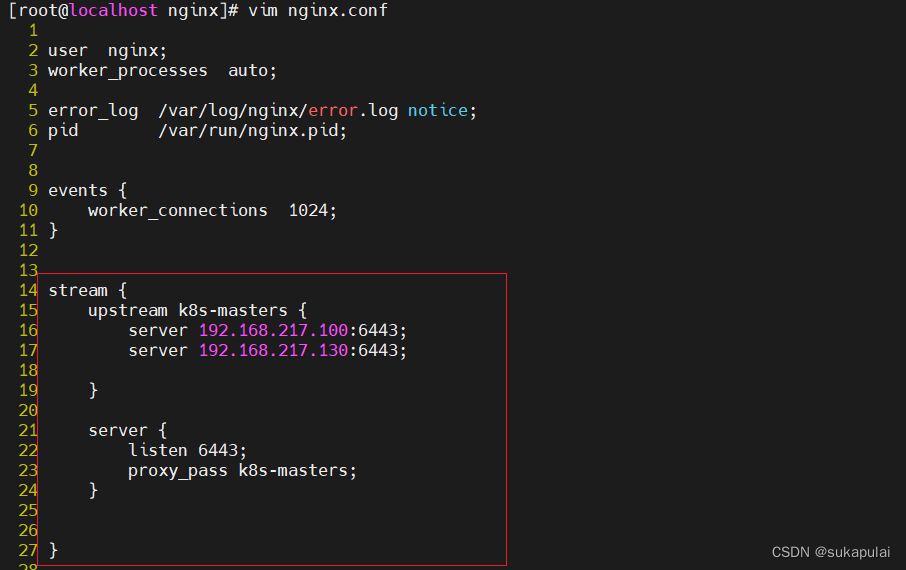

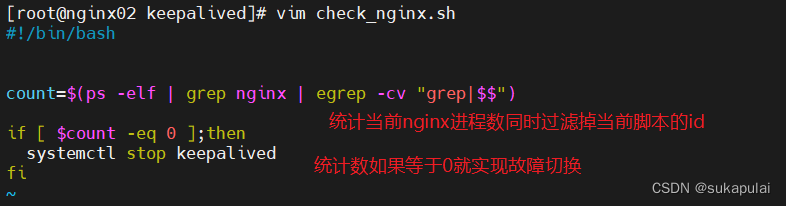
准备监控脚本监控nginx服务运行状态
cd /etc/keepalived/
ps -elf |grep nginx |egrep -cv "grep" #
vim check_nginx.sh
#!/bin/bash
count=$(ps -elf |grep nginx | egrep -cv "grep|$$")
if [ $count -eq 0 ];then
systemctl stop keepalived
fi
chmod +x check_nginx.sh

修改keepalived的配置文件
vim keepalived.conf
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX01
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh“
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.217.50
}
track_script {
check_nginx
}
}
systemctl enable --now keepalived.service #启动keepalived服务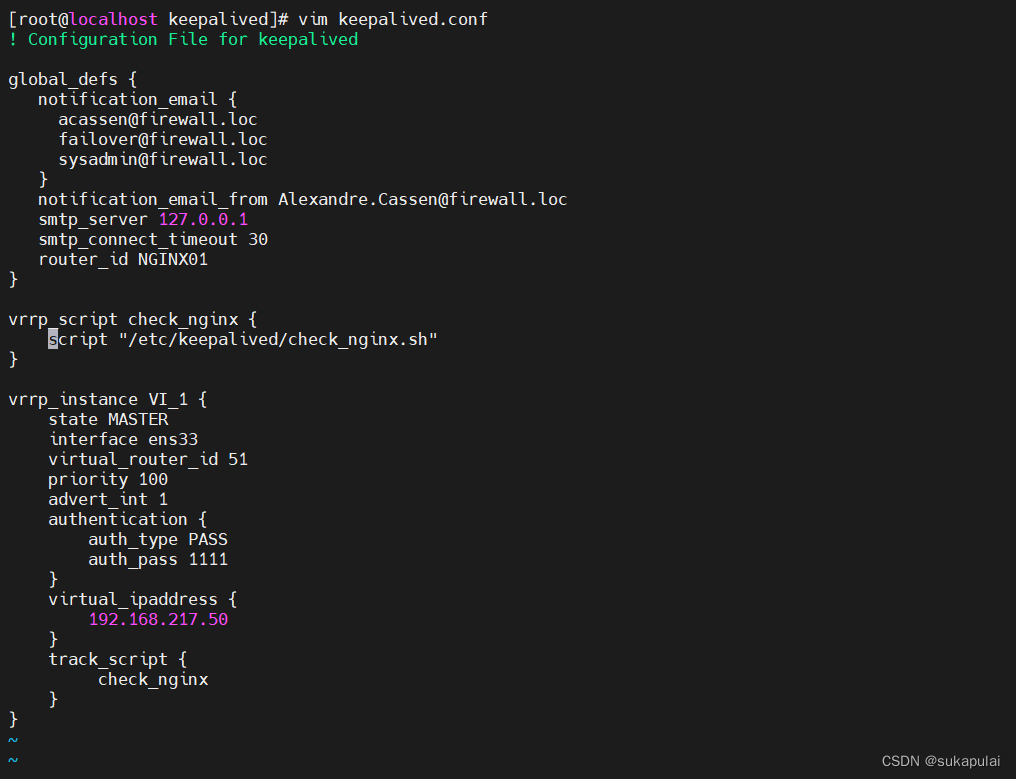
在备节点上传nginx的yum源
cd /etc/yum.repos.d/
yum install nginx -y
yum install keepalived -y #安装高可用把主节点nginx配置文件和keepalived配置文件复制到备节点
cd /etc/nginx/
scp nginx.conf 192.168.217.150:`pwd`
cd /etc/keepalived/
scp * 192.168.217.150:`pwd`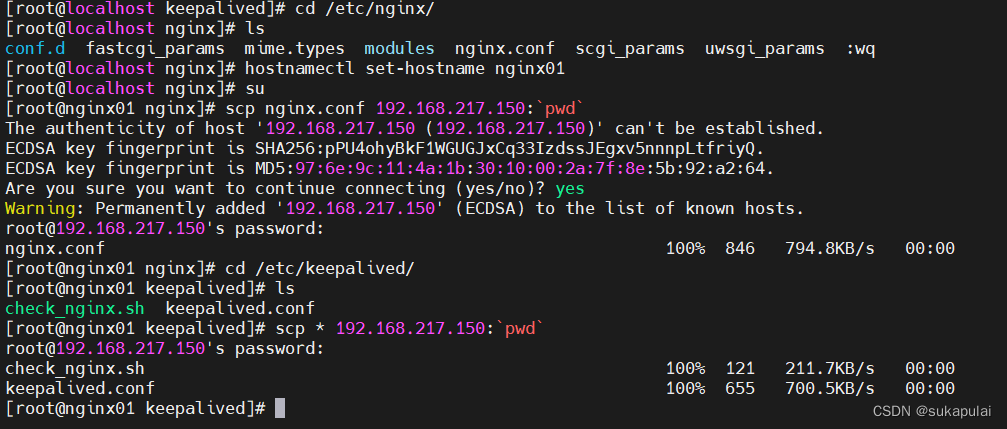
到备节点修改keepalived配置文件
cd /etc/keepalived/
vim keepalived.conf
#12行
router_id NGINX02
#20行
state BACKUP
#23行
priority 90
systemctl enable --now nginx #启动nginx服务
systemctl enable --now keepalived.service #启动keepalived服务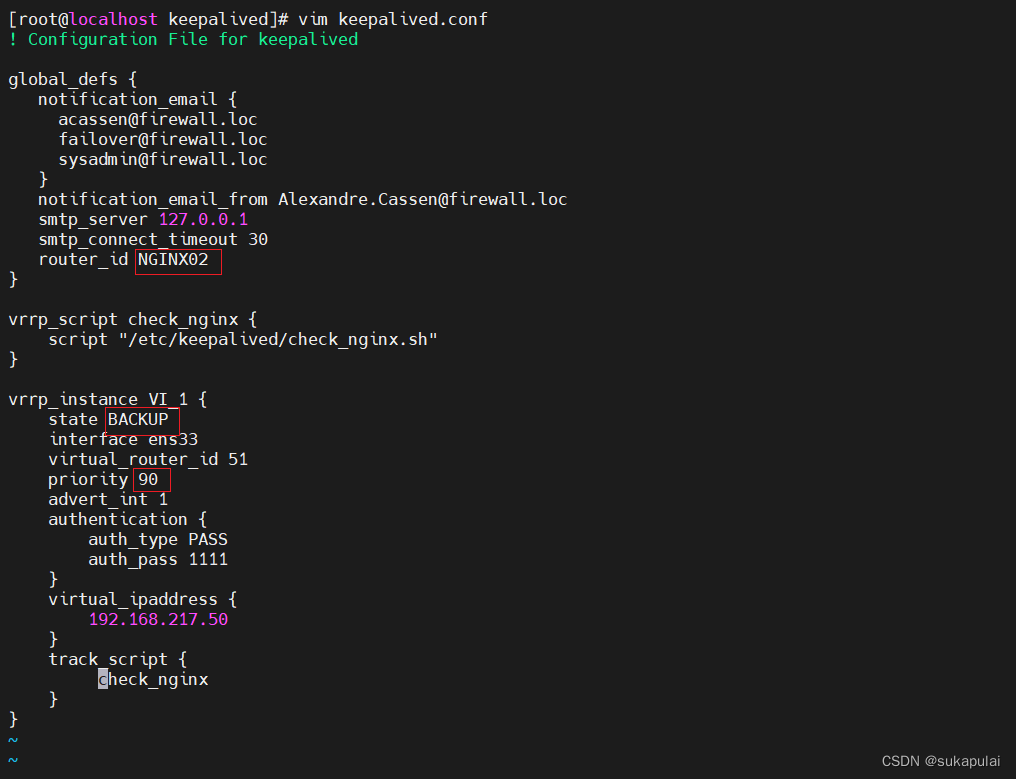
在主节点查看vip
ip a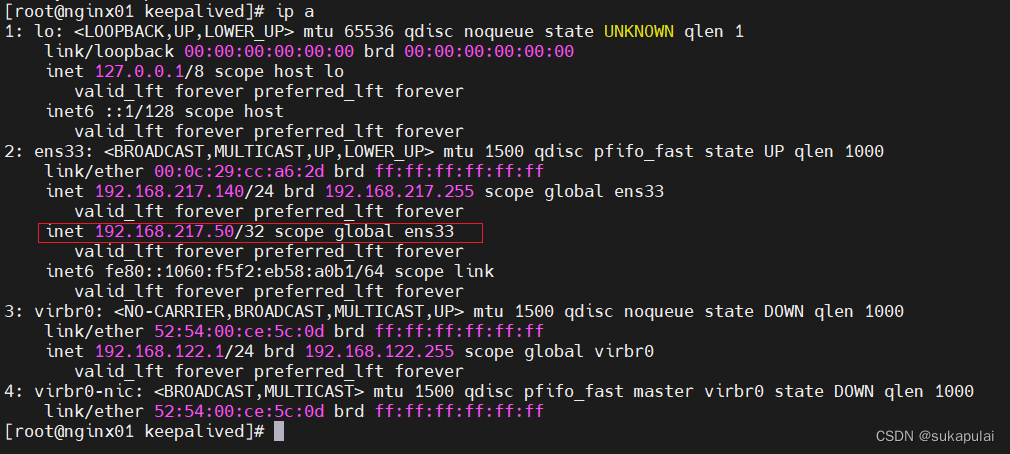
修改node节点对接到VIP地址
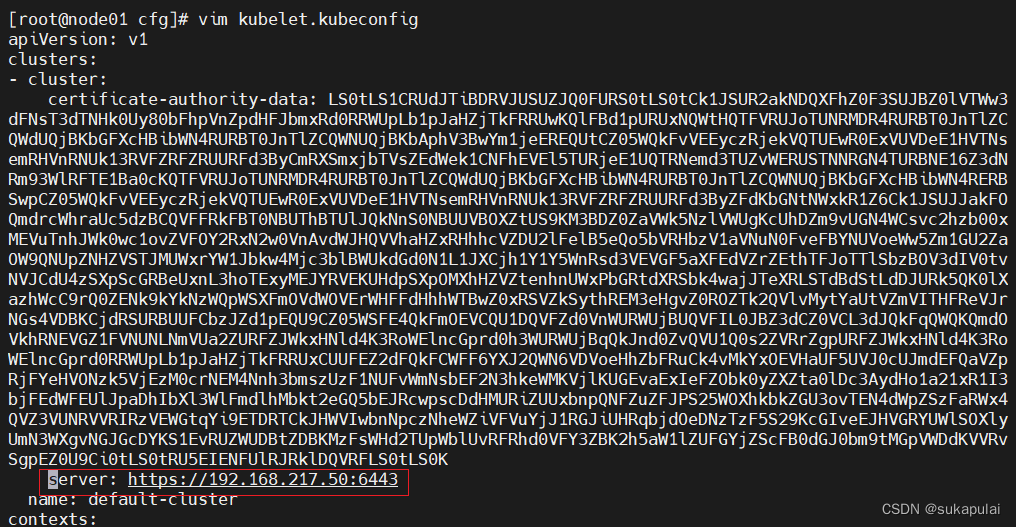
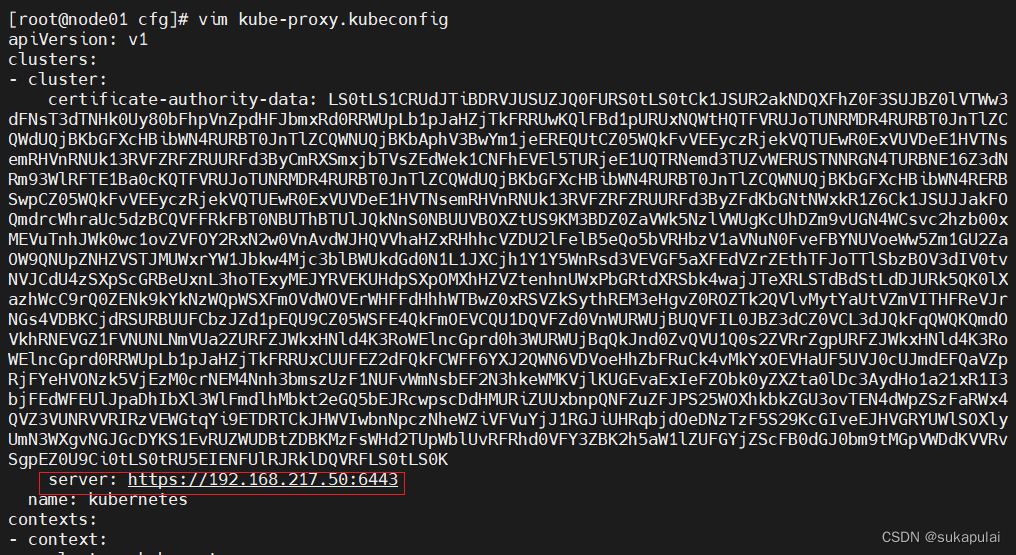
cd /opt/kubernetes/cfg
vim bootstrap.kubeconfig
修改server项
server: https://192.168.217.50:6443
vim kubelet.kubeconfig
vim kube-proxy.kubeconfig
systemctl restart kubelet kube-proxy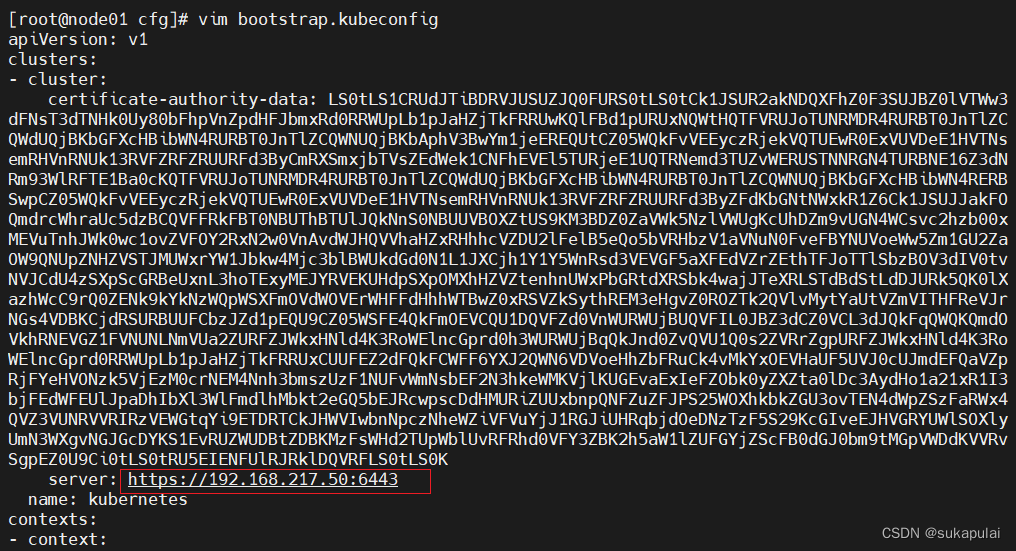

再到负载均衡器查看
netstat -natp |grep nginx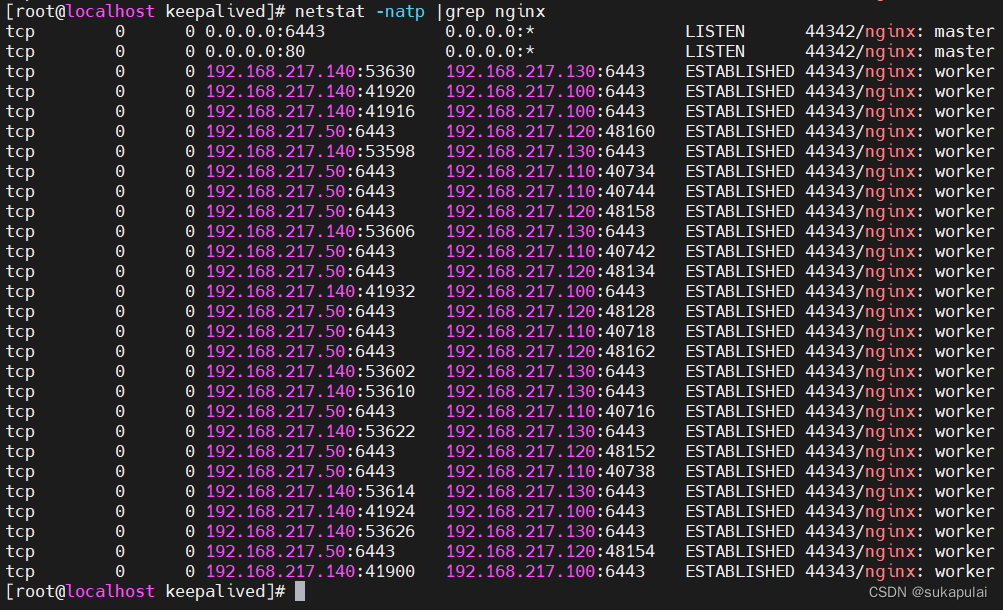
修改master节点对接到VIP地址
cd .kube/
vim config
server: https://192.168.217.50:6443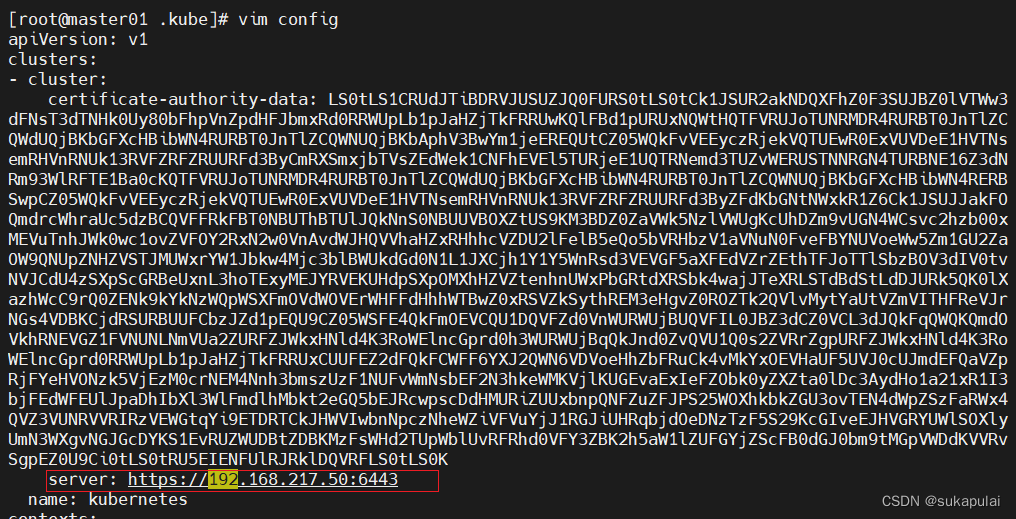
在master创建进入容器
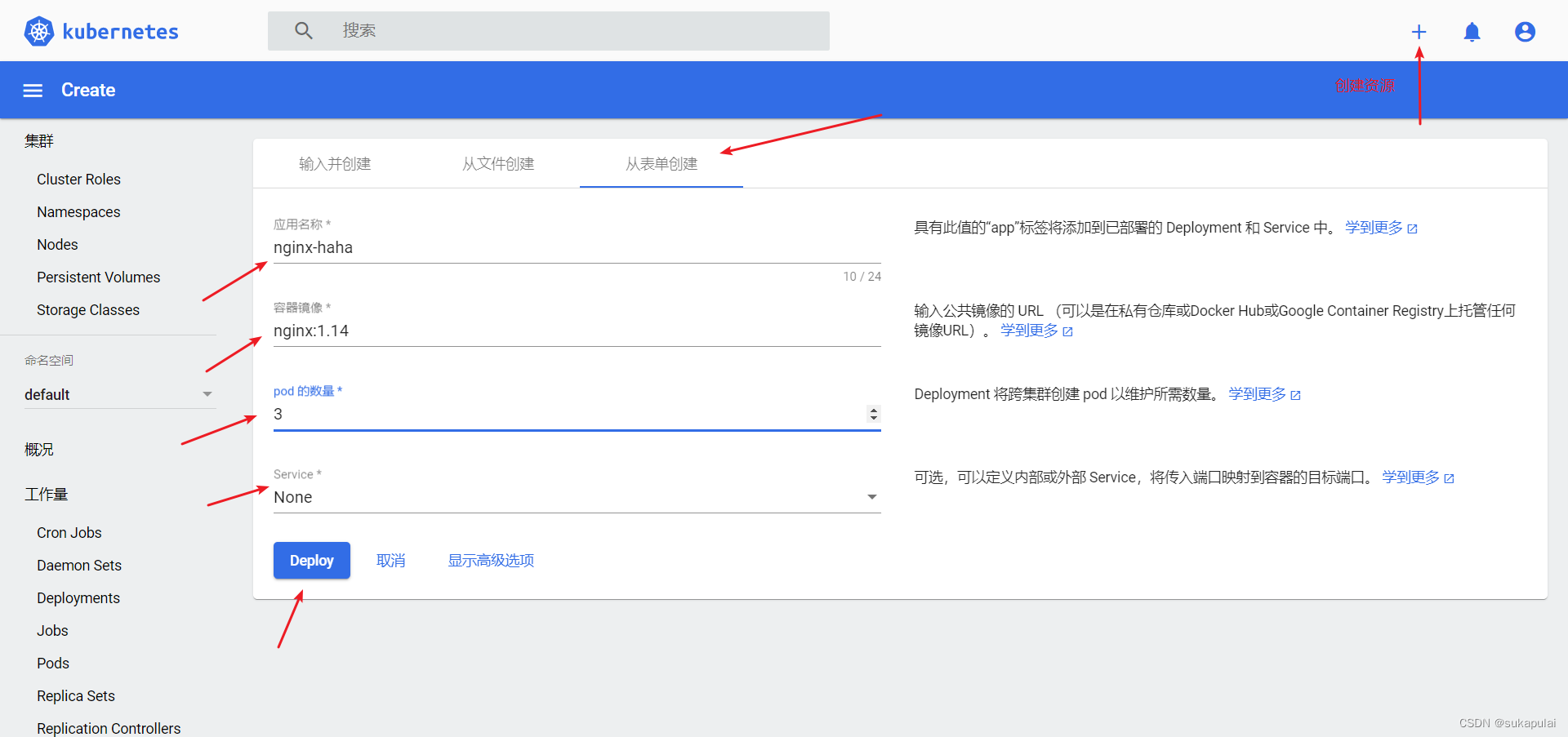
#开多台master主机
kubectl run centos7-qq -it --image=centos:7
kubectl run centos7-ww -it --image=centos:7
kubectl run centos7-ee -it --image=centos:7
kubectl run centos7-aa -it --image=centos:7
查看创建pod
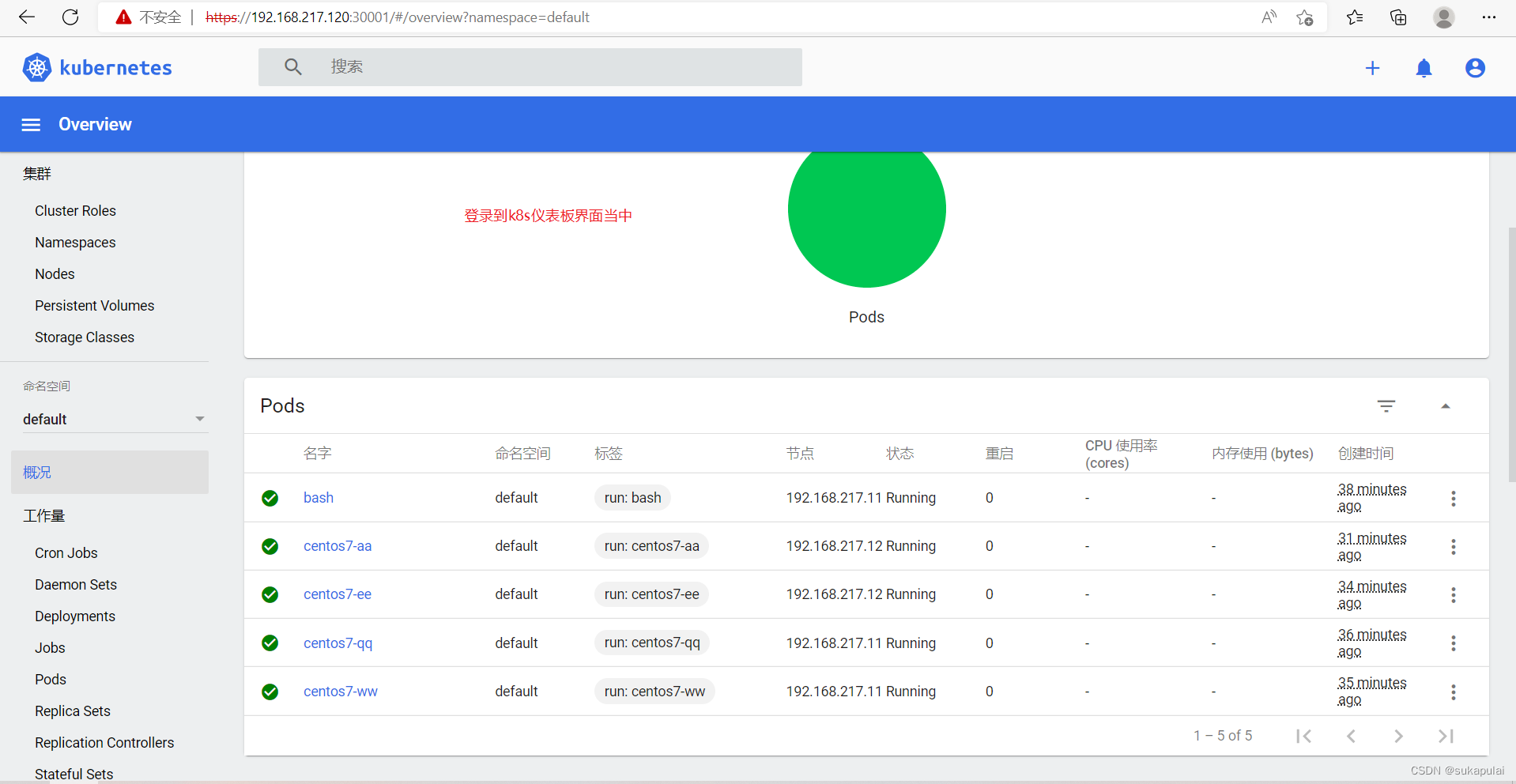
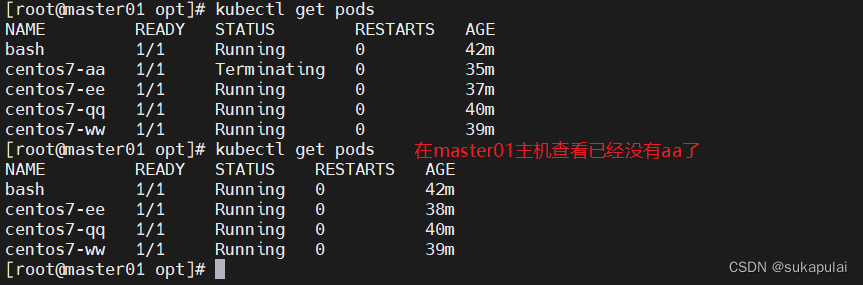
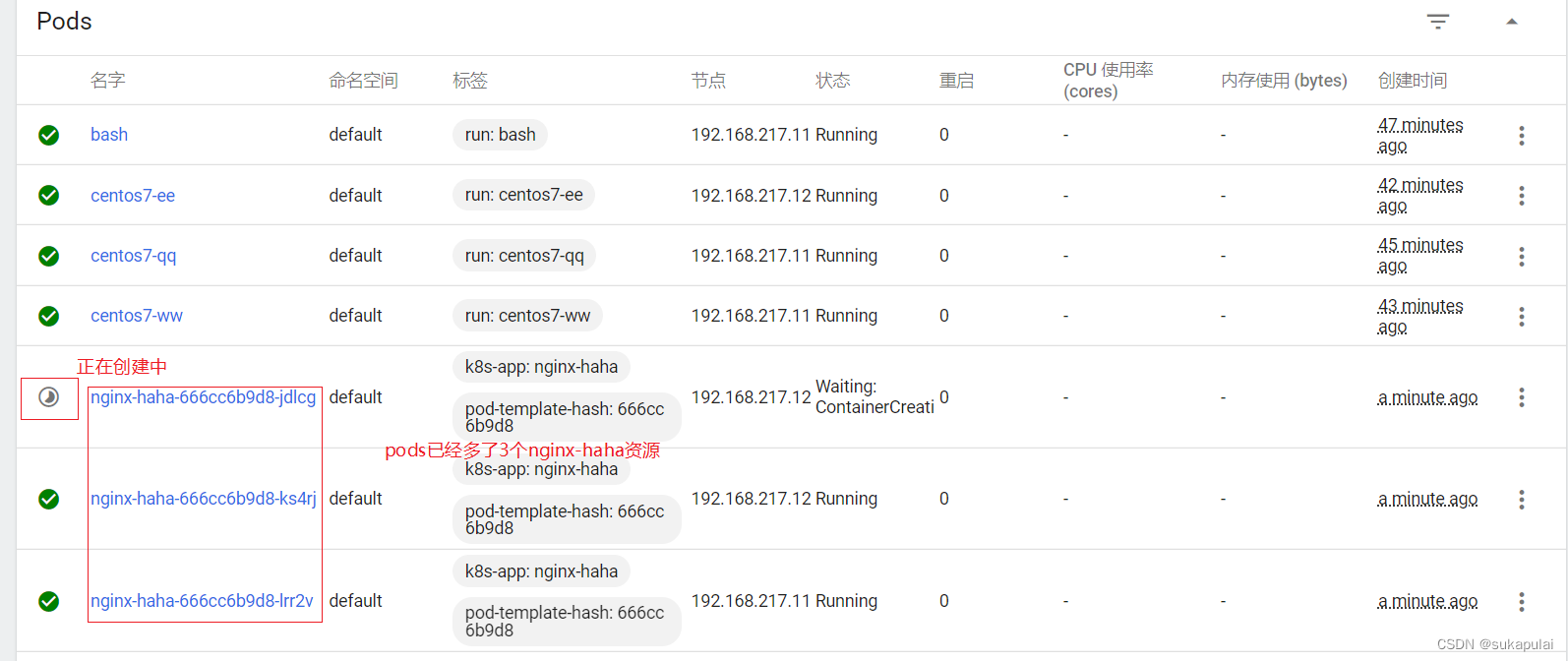
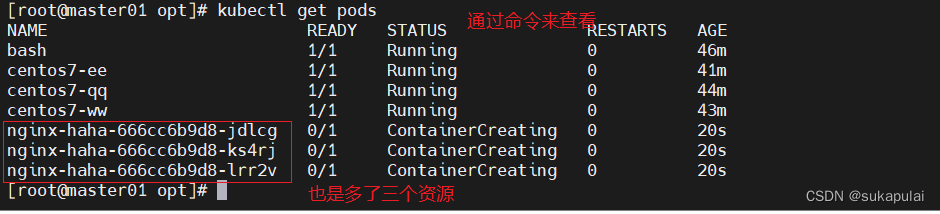
kubectl get pods -owide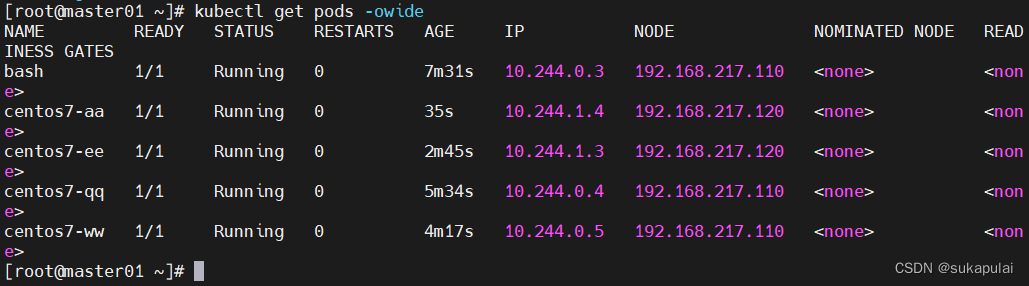
尝试pod与pod之间能不能通信
ping 10.244.1.3
ping 10.244.0.5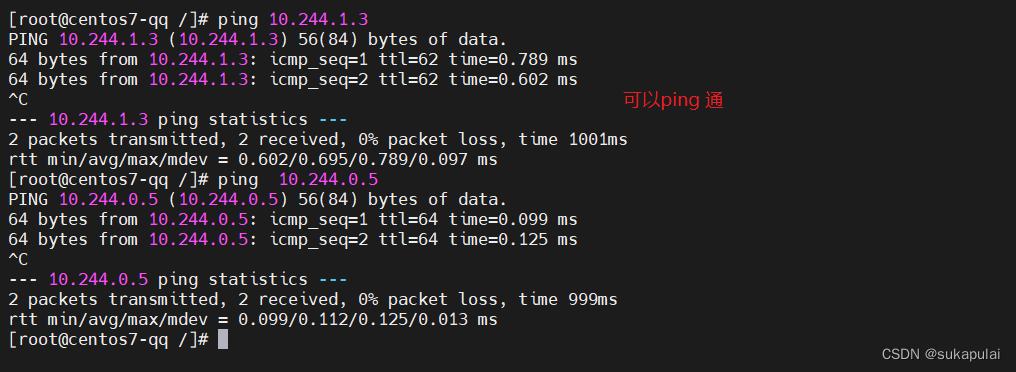
通过仪表板实现pod的创建
部署 Dashboard
在两个node节点上传两个镜相包
加载两个镜像
docker load -i dashboard.tar
docker load -i metrics-scraper.tar
在 master01 节点上操作
上传 recommended.yaml 文件到 /opt/k8s 目录中,部署 CoreDNS
cd /opt/k8s
vim recommended.yaml
#默认Dashboard只能集群内部访问,修改Service为NodePort类型, 暴露到外部:
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
nodePort: 30001 #添加
type: NodePort #添加
selector:
k8s-app: kubernetes-dashboard
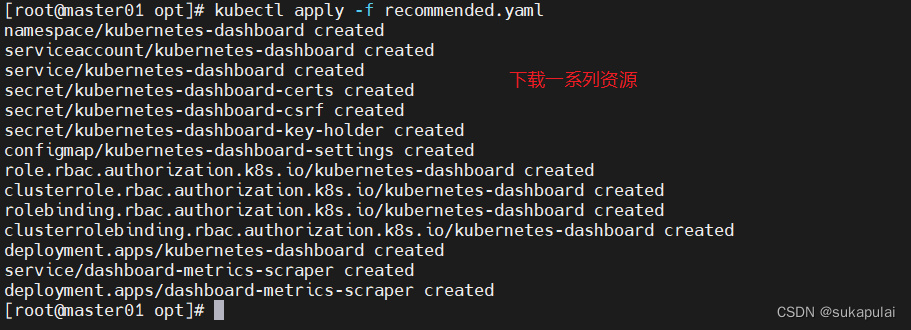
kubectl apply -f recommended.yaml
kubectl get pods -n kubernetes-dashboard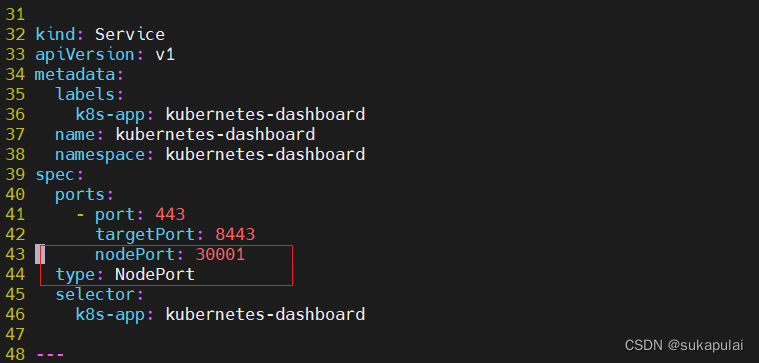

去网页访问
https://192.168.217.120:30001/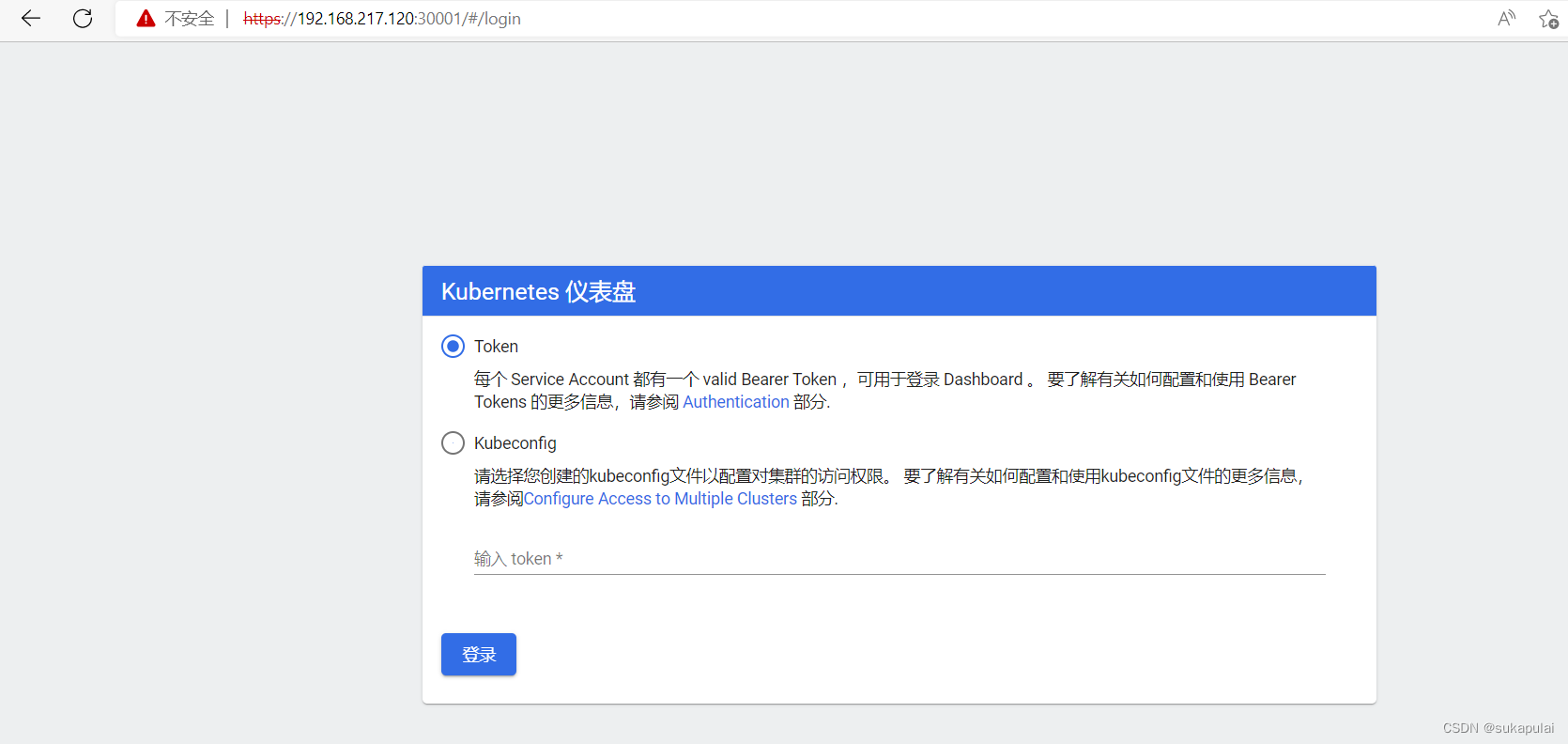
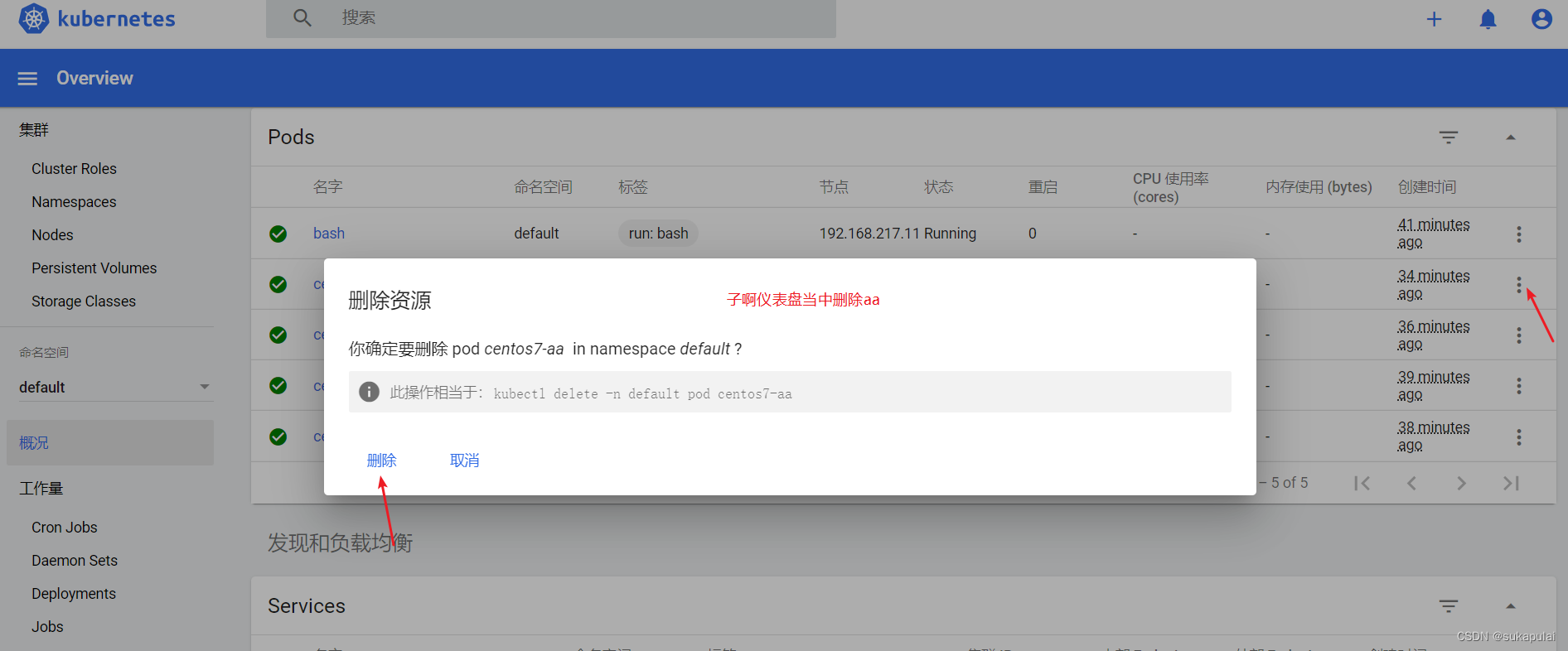
创建service account并绑定默认cluster-admin管理员集群角色
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
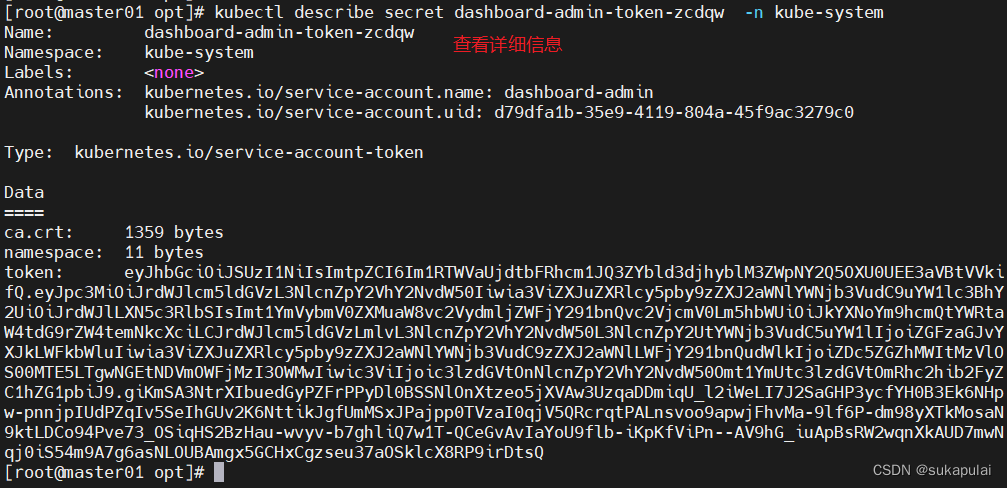
kubectl get secret -n kube-system #获得名称
kubectl describe secret dashboard-admin-token-zcdqw -n kube-system

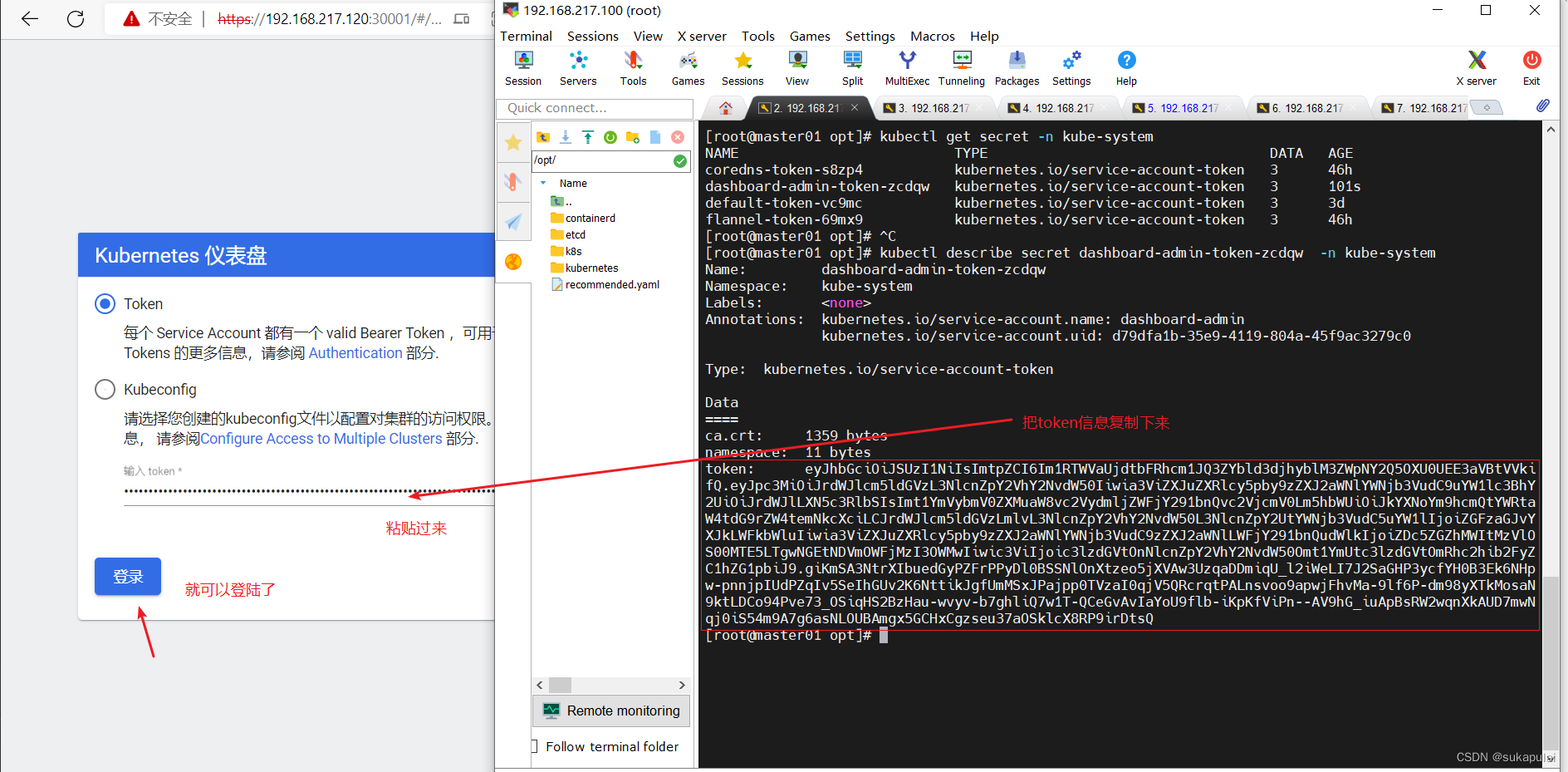
总结
etcd 安装步骤:
准备ca证书和私钥文件,使用ca签发服务端证书和私钥文件
使用ca证书、服务端证书和私钥文件加上etcd集群配置文件去启动etcd服务
复制etcd 工作目录和服务管理文件到另外几个节点上,修改etcd集群配置文件并启动etcd服务
使用v3版本的接口执行etcdctl+证书选项+(endpoint health I endpoint status I member list)查看etcd集群和节点状态flannel
配置方便,功能简单,是基于overlay叠加网络实现的,由于要进行封装和解封装的过程对性能会有一定的影响,同时不具备网络策略配置能力
3种模式 UDP VXLAN HOST-GW
默认网段是10.244.0.0/16calico
功能强大,没有封装和解封装的过程,对性能影响较小,具有网络策略配置能力,但是路由表维护起来较为复杂
默认网段192.168.0.0/16
模式:BGP IPIPetcd
准备证书
启动etcd服务,加入集群master
准备证书和tokern文件
安装apiserver,controller manger,schedulernode
准备kubeconfiq文件
启动kubelet,发送csr请求证书
启动 kube-proxy
安装CNI网络插件,实现pod 跨主机的通信
安装CoreDNS插件,可以实现service名称解析到clusterIPvxlan与vlan区别:
vxlan支持更多的二层网络
vlan使用12位bit表示vlan ID,因此最多支持212=4094个vlan vxlan使用的ID使用24位bit,最多可以支持224个
已有的网络路径利用效率更高
vlan使用spanning tree protocol避免环路,会将一半的网络路径阻塞1 vxlan的数据包封装成UDP通过网络层传输,可以使用所有的网络路径
防止物理交换机Mac表耗尽
vlan需要在交换机的Mac表中记录Mac物理地址 vxlan采用隧道机制,Mac物理地址不需记录在交换机

















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









