



前面忘了写电子笔记了现在直接写后面的
为啥要发在优快云上呢?因为我的微软账号被锁了,我的onenote不能同步上传了,防止丢失我都拷贝一份到csdn上,等我弄完研究生和实习,我再传到github上吧。
补前面

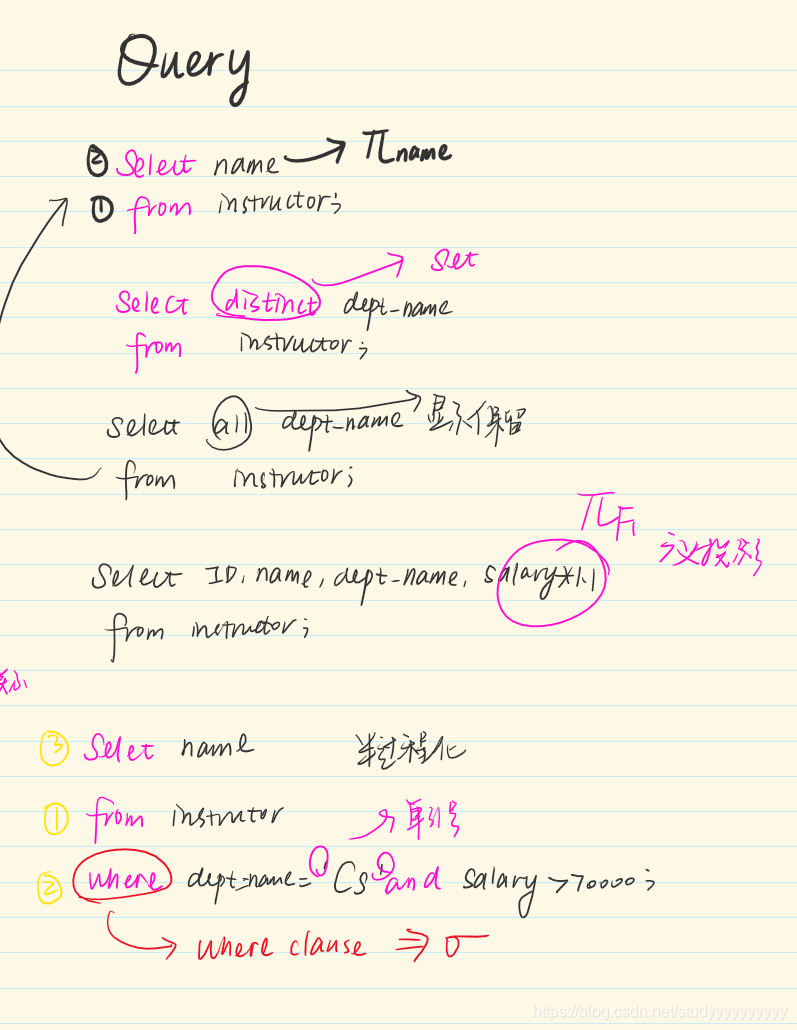


3.4.1 更名运算
```sql
select name as instructor_name
from instructor; -- 属性更名
select T.name, S.course_id
from instructor as T, teaches as S
where T.ID = S.ID; -- 关系更名
-- 工资至少比Biology的一个教师的工资要高
select distinct T.name
from instructor as T, instuctor as S
where S.dept_name = 'Biology' and T.salary > S.salary
```
3.4.2 字符串运算
SQL使用单引号标识字符串,在字符串的相等运算上,SQL大小写敏感,‘comp.sci’ = ‘Comp.Sci’ is false
SQL支持模糊查询,like关键字实现模式匹配 upper trim lower
% 是匹配任意字串 _匹配任意一个字符
like ‘ab%cd’ escape ‘’ 匹配ab%cd
```sql
select dept_name
from department
where building like '%Watson%';
```
4.3.3 *通配符
```sql
select *
from teaches; -- *代表所有属性,输出结果和from里面的表头相同
select instructor.*
from instructor, teaches
where instructor.ID = teaches.ID;
```
4.3.4 order by 根据某个属性排序
```sql
select name
from instructor
where dept_name = 'Physics'-- order by是在上面三行生成的新的临时关系中排序,order by 在最下面,默认是asc升序
order by name;
--先按工资降序排列,相同的再按name升序排列
select name, salary
from instructor
order by salary desc, name asc;
```
4.3.5 where clause
```sql
select name
from instructor
where salary not between 90000 and 100000;--前闭后闭
select name, course_id
from instructor, teaches
where instructor.ID = teaches.ID and dept_name = 'Physics';
-- 等价于下面的
select name, course_id
from instructor, teaches
where (instructor.ID, dept_name) = (teacher.ID, 'Physics');
```
3.5 集合运算
union、intersect、except(∪、∩、-)
集合运算,会自动去重,可以在后面加all显示表示不去重
```sql
select course_id
from section
where semester = 'Fall' and year = 2009;
union / intersec / except --前两个无序,最后一个有序,在A不在B
select course_id
from section
where semester = 'Spring' and year = 2010;
```
3.6 空值
unknown and true = unknown unknown and false = false…
3.7 聚集函数
min/avg/max/sum/count
```sql
select avg(salary) as avg_salary
from instructor
where dept_name = 'Physics';
select count(distinct ID) --count要注意是否去重
from section
where semester = 'Fall' and year = 2010;
select count(*) --所有元组个数,不允许ditinct
from course;
```
3.7.1 group by 分组聚集
```sql
--分组聚集
select dept_name, avg(salary) as avg_salary--必须保留分组依据,其他属性不能加,没有意义的
from instructor
group by dept_name;
--找出每个系在2010年春季讲授一门课程的教师人数
select dept_name, count(distinct ID) as instr_num
from section natural jion instructor
where semester = 'Spring' and year = 2010
group by dept_name;
```
3.7.2 having 分组后条件限定
where 是在元组上进行条件限定,having是在分组后进行条件限定
```sql
select dept_name, avg(salary) as avg_salary --4
from instructor --1
group by dept_name -- 2
having avg(salary) > 40000;--在上面2行形成的新的临时关系上进行条件限定 3
```
顺序:from where group by having select
a complex example:
2009年讲授的课程段中,至少有两名同学选课的每个课程段的总学分
```sql
select course_id, sec_id, semster, year, tol_cred
from student, takes
where year = 2009 and student.ID = takes.ID
group by course_id, sec_id, semster, year --主键才能唯一区分section
having count(distinct ID) > 2;
```
3.7.3 对空值和boolean的聚集函数处理
除了count(* )之外其他聚集函数都会忽略 count(*)是计算元组个数
!!!
- count()是否去重
- 分组聚集是否要分组列
- 是否要重命名属性
- 笛卡尔积是否需要where clause保证正确性
继续更2021.4.7
终于又进入到一门课程的迷惑时刻了,就是我到底在学什么?学这些有什么用?咋学啊?不理解啊?这语法为啥这样?
于是又打开了知乎…
看到一篇好文章(https://zhuanlan.zhihu.com/p/60185691)、一个好网站(SQLZOO等我这周结束就开始做)
在写SQL时我就想说为啥要先写这一步,内部到底是咋执行的呢?现阶段只能这样理解了
!!!!SQL思考和执行顺序
- 我从那个关系中取数据 from
- 需要过滤取出哪些元组 where
- 我需要分组呈现吗? group by
- 那我弄完分组后又想要过滤怎么办? having
- 好了,我最终要呈现拿些数据? select
- 最后需不需要排序显示 order by
语法写的时候就把select放前面 select from where group by having order by
再就是一些语法规范
- SQL语句的最后不要忘记加分号
- 查询日期或字符串的时候,使用单引号 ‘’
- 不等于用<>,这个写法适用于所有RDBMS
- order by 默认为升序asc,降序的写法是 order by desc
- order by 是在select之后执行,所以可以使用在select中定义的别名,而其他地方不能使用别名,特别是新手容易在where中使用别名
好了,继续更新今天下午学的知识吧
3.8 嵌套子查询(有点难) Nested Subqueries
3.8.1 集合成员资格 Set Membership
这个嵌套是指在select、from、where查询子句中嵌套
in 关键字查询成员是否在集合中, not in 查询成员是否不在集合中
```sql
-- eg: both in Spring 2010 and Fall 2009
select course_id
from section
where year = 2010 and semester = 'Spring' and -- and 在where子句中嵌套
course_id in (select course_id
from section
where year = 2009 and semester = 'Fall');
-- 括号(在集合的圈中)中是要进入查找的集合,集合中是select选择的一个个元组
-- in 左右的这两个course_id course_id要对应相同,就是要查找的东西和集合中的东西要是一种东西(属性个数相同&&域相同)
-- 一般来说属性名是一样的,不排除不一样的情况
-- eg 2: not in
-- 2010 except 2009
select course_id
from section
where year = 2010 and semester = 'Spring' and course_id not in
(select course_id from section where year = 2009 and semester = 'Fall');
--后面那个集合也可以是自己给定的集合
select distinct name
from instructor
where name not in ('Mozart', 'Einstein');--不叫这个也不叫这个的老师名字
```
3.8.2 集合比较
上面我们说的是在不在,有没有,下面我们说成员和集合中成员比较
```sql
--找出至少比一个生物系老师薪水高的老师:比较的就是薪水
select name
from instructor
where salary > some (select salary from instructor where dept_name = 'Biology');
-- > some是说比其中的某一个大 <= some = some(in) <>some (不等于some不是not in)
--找到生物系中最高薪水的老师名字
-- >=所有的就是最高的,在等号处取得,>啥也没有
select name
from instructor
where salary >= all(select salary from instructor where dept_name = 'Biology');
```
3.8.3 空关系测试 exists
测试一个子查询结果中是否存在元组,exists在子查询结果元素非空时为true,not exists在查询子元素为空时为true
```sql
select T.course_id
from section as T
where year = 2010 and semester = 'Spring' and
exists (select * from section as S where year = 2009 and semester = 'Fall' and
S.course_id = T.course_id); --必须改名
-- exists (select *) *是不用考虑你选出那些属性,因为我们关心的是选出多少元组数量
-- 为什么需要id相等?要不()里面的一种,需要将前面和后面联系起来,这样元组数量不为0才返回true
```
not exists(B except A) 在B中不在A中 这样的元组没有才是true,没有在B中不在A中的,那么就是A包含B
```sql
-- 找到选修了Bio系所有课程的学生
--就需要Bio系所有课程B 和 每个学生选修的课程A 是A包含B的关系
select ID --让course_id==下面满足条件的course_id
from student
where not exists
(select course_id from course where dept_name = 'Biology'
except
select course_id from takes
--本来not exists到这就结束了,但是要把符合条件的ID选出来,所以下面这一行。。。
where student.ID = takes.ID);
```
感觉就类似于两层for循环 第一层找到Bio所有课程id 第二次匹配学生选修的课程id


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









