




 本文介绍了Sklearn在数据挖掘中的应用,遵循CRISP-DM流程,涉及数据预处理、降维、模型选择和评估。重点讨论了Sklearn中的预处理模块、降维技术、模型选择策略以及模型评估方法。通过实例展示了如何在Jupyter环境中使用Sklearn,并介绍了常用数据集的加载方式、Pandas数据管理以及模型的基本操作和参数设置。
本文介绍了Sklearn在数据挖掘中的应用,遵循CRISP-DM流程,涉及数据预处理、降维、模型选择和评估。重点讨论了Sklearn中的预处理模块、降维技术、模型选择策略以及模型评估方法。通过实例展示了如何在Jupyter环境中使用Sklearn,并介绍了常用数据集的加载方式、Pandas数据管理以及模型的基本操作和参数设置。
通过下面这张图了解一下Sklearn的工作原理
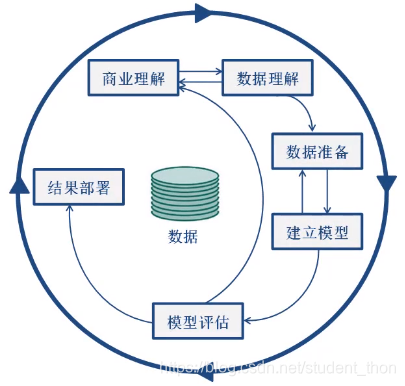
这是一张CRISP-DM,即为"跨行业数据挖掘标准流程"。它强调的是一个循环迭代的过程。想要详细的了解这张图可以在https://www.bigdatas.cn/article-2103-1.html该网站中了解。
在这张图中Sklearn是从"数据准备"阶段开始的。首先,Sklearn有预处理的模块,可以把特征进行提取和归一化 ,把相应的原始输入数据(如文本)转变为机器学习算法可用的数据。算法主要有preprocessing, feature extraction。然后是降维,当我们的数据之间存在着信息的重叠,可以考虑用降维的方法来减少要考虑率的随机变量的数量,是为了把一些没用的数据筛选掉,提高后面的分析效率。算法有PCA, feature selection, non-negative matrix factorization。再有就是模型选择,有grid search, cross validation, metrics等,其中 cross validation可以用来对数据进行拆分或者对数据进行交互验证。
数据准备完成之后,紧接着就是建立模型。用到的模型有:回归模型,包括SVR, ridge regression, Lasso… ;分类预测模型,包括SVM, nearest neighbors, random forest, 神经网络,逻辑回归…;聚类模型,包括k-Means, spectral clustering, mean-shift(均值偏移聚类)…
然后是模型评估,在对模型进行优化的过程中,可以用到grid search(网格搜索), cross validation(用来优化), metrics(用来做模型的评估,包括命中率,查全率,ROC曲线)等。上述所涉及到的算法以及模型,会在后面的博客中介绍。
最后是结果部署,这部分不属于Sklearn的内容。接下来就通过代码来学习Sklearn
以下代码都在jupyter中实现
环境的准备
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 图形在notebook中直接显示
%matplotlib inline
import seaborn as sns # 为了显示优美的图形,可加可不加
# 加载seaborn默认格式设定
sns.set()
# 解决中文显示乱码的问题
plt.rcParams["font.family"] = "STXIHET"
在平时的训练过程中,可以使用如下的几种数据集
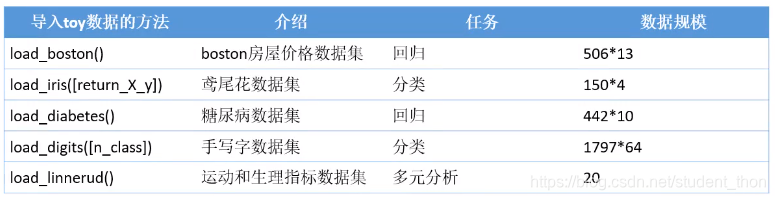
Sklearn的样本数据集使用方式
from sklearn import datasets
boston = datasets.load_boston()
对于每一个数据集都有load方法
# 将数据转化为数据框便于使用(显示前5行)
bostondf = pd.DataFrame(boston.data, columns=boston.feature_names)
bostondf.head()
运行结果:
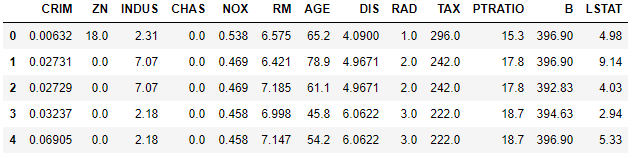
在Python中一般用Pandas来做数据管理和数据整理
Sklearn的基本入门操作
首先来了解一下基本的类参数
class sklearn.大类名称.Modelclass(类参数列表):
Modelclass中基本通用的类参数:
fit_intercept = True: 模型是否包括常数项,使用该选项就不需要在数据框中设定常数项
n_jobs = 1: 使用的例程数,为-1时使用全部CPU;例程数越高,模型拟合的越快
max_iter = 200: 模型最大迭代次数。对于海量数据有必要修改次数,太小会导致不收敛
tol = 0.0001: 模型收敛标准,一般不用修改
warm_start = False: 是否使用上一次的模型拟合作为本次的初始值
sample_weight = None: 案例权重
random_state = None: int/RandomState instance/None,随机器的设定
shuffle = True: 是否在拆分样本前做随机排列
对数据做标准正太变换
from sklearn import preprocessing
# 完整类名为sklearn.preprocessing.StandardScaler()
std = preprocessing.StandardScaler()
preprocessing.scale(boston.data)[:2]
结果如下图:
Modelclass中基本通用的类方法

from sklearn import linear_model
reg = linear_model.LinearRegression()
# 使reg类基于指定数据估计出回归模型的相应参数(拟合)
reg.fit(boston.data, boston.target)
运行结果:

# 查看模型中的回归系数
reg.coef_
运行结果:

# 对数据做预测,并显示前10个
pred = reg.predict(boston.data)
pred[:10]
运行结果:
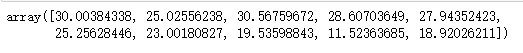
# 评估模型的效果
reg.score(boston.data, boston.target)
运行结果:
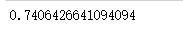

















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









