









 本文介绍了一种基于sklearn的线性回归模型进行波士顿房价预测的方法,并使用了交叉验证来评估模型性能。通过20折交叉验证,将预测结果与实际房价进行了对比。
本文介绍了一种基于sklearn的线性回归模型进行波士顿房价预测的方法,并使用了交叉验证来评估模型性能。通过20折交叉验证,将预测结果与实际房价进行了对比。
该demo基于sklearn中的boston房价数据集和线性回归模型linear_model,使用交叉验证方法进行模型训练。
from sklearn import datasets
from sklearn.model_selection import cross_val_predict
from sklearn import linear_model
import matplotlib.pyplot as plt
# 模型调用
lr = linear_model.LinearRegression()
# 数据准备
boston = datasets.load_boston()
x = boston.data
y = boston.target
# 交叉验证方法使用
# 其中lr是底层的estimator,x和y是训练数据,cv是交叉验证k折法相应的k参数,默认是3折
# 这里我们自定义20折
predicted = cross_val_predict(lr, x, y, cv=20)
fig, ax = plt.subplots()
ax.scatter(y, predicted, c="blue", edgecolors="yellow")
ax.plot([y.min(), y.max()], [y.min(), y.max()], 'k', lw=2)
ax.set_xlabel('y')
ax.set_ylabel('prediction')
plt.show()
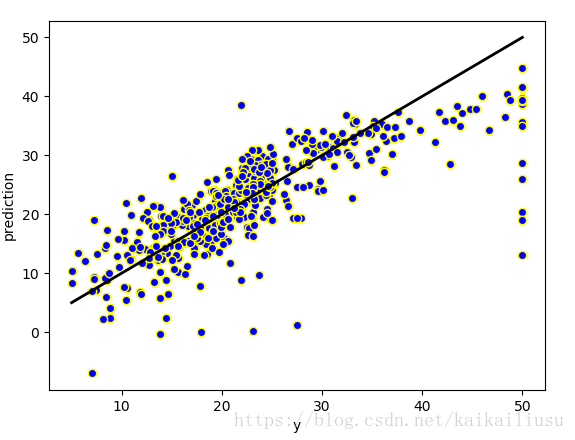
结果如下,横坐标代表原始标签y值,纵坐标代表预测标签predicted;其中,图中的黑色虚线是y值和predicted值理论上的最合理分布情况,而各个蓝色原点是y值和predicted值的真是对应情况。

















 5658
5658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









