




 Avalanche是一个专为持续学习设计的全栈库,提供现成的数据集、经典基准和生成器,支持用户自定义策略和评估。它允许研究人员构建和实验各种连续学习算法,以适应不断变化的数据流。
Avalanche是一个专为持续学习设计的全栈库,提供现成的数据集、经典基准和生成器,支持用户自定义策略和评估。它允许研究人员构建和实验各种连续学习算法,以适应不断变化的数据流。
Avalanche是个用来做continual learning的end-to-end的库。作用是帮助研究者编写continual learning的程序。在保证了每个模块的完整性和独立性的基础上,保留了它们的扩展性和有效性,即使用者可以利用其框架编写自己的CL算法或导入自己的数据集。
官网:https://avalanche.continualai.org/
paper:https://arxiv.org/abs/2104.00405
github:https://github.com/ContinualAI/avalanche
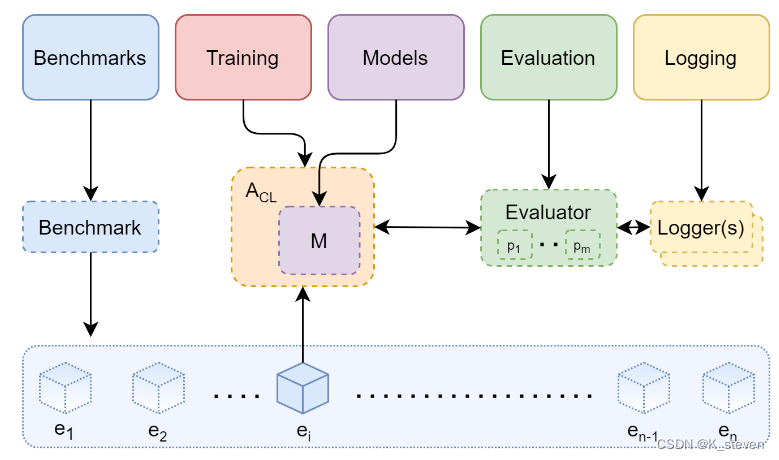
对Continual Learning框架的定义:
整个过程可以看作对Continual Learning算法A的不断更新。所谓更新是指改变它内部的模型M和数据结构D。更新手段是使用一系列的不固定的经验流(e1,…, en)进行训练。更新的目标是让其在测试的经验流(e1t,…,ent)上的evaluation指标有更好的表现。

主要框架:
1. Benchmarks
a. datasets:import现有的数据集
b. classic benchmarks:经典的benchmarks
c. generators:新建Benchmarks
2. Training
a. Strategies:使用现有的continual learning方法或baselines
包括Naive, CWRStar, Replay, GDumb, Cumulative, LwF, GEM, AGEM, EWC, AR1
b. Create Strategy:编写自己的strategy
3. Evaluation
a. Evaluation: 使用Metrics和Loggers对模型进行评估和记录
Metrics 包括Accuracy, Forgetting, Memory Usage, Running Times, etc.
代码demo,前面是每个模块的使用方法,最后一部分是测试example
################## 1. Benchmarks
# ---------------------------- 1.1 import datasets ---------------------------------------- #
from avalanche.benchmarks.datasets import MNIST, FashionMNIST, KMNIST, EMNIST, \
QMNIST, FakeData, CocoCaptions, CocoDetection, LSUN, ImageNet, CIFAR10, \
CIFAR100, STL10, SVHN, PhotoTour, SBU, Flickr8k, Flickr30k, VOCDetection, \
VOCSegmentation, Cityscapes, SBDataset, USPS, HMDB51, UCF101, CelebA, \
CORe50Dataset, TinyImagenet, CUB200, OpenLORIS, MiniImageNetDataset, \
Stream51, CLEARDataset
# ---------------------------- 1.2 classic benchmarks ---------------------------------------- #
from avalanche.benchmarks.classic import CORe50, SplitTinyImageNet, SplitCIFAR10, \
SplitCIFAR100, SplitCIFAR110, SplitMNIST, RotatedMNIST, PermutedMNIST, SplitCUB200
# creating the benchmark (scenario object)
perm_mnist = PermutedMNIST(
n_experiences=3,
seed=1234,
)
# recovering the train and test streams
train_stream = perm_mnist.train_stream
test_stream = perm_mnist.test_stream
# iterating over the train stream
for experience in train_stream:
print("Start of task ", experience.task_label)
print('Classes in this task:', experience.classes_in_this_experience)
# The current Pytorch training set can be easily recovered through the
# experience
current_training_set = experience.dataset
# ...as well as the task_label
print('Task {}'.format(experience.task_label))
print('This task contains', len(current_training_set), 'training examples')
# we can recover the corresponding 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1085
1085




 到【灌水乐园】发言
到【灌水乐园】发言







