



2024-2025-1 20242828《Linux内核原理与分析》第八周作业
一、实验相关知识
1、编译链接的过程
编译链接是将源代码转换为可执行程序的过程,它通常包括以下几个步骤:
(1)预处理
在这一阶段,编译器首先会处理源代码中的预处理指令,如宏定义、头文件引用以及条件编译。预处理器会将所有的宏替换为其对应的代码,将头文件内容插入到源代码中,并根据条件编译指令选择性地包含代码块。
(2)编译阶段
编译器将经过预处理的源代码翻译成汇编语言代码。这一过程中,编译器会首先对源代码进行语法分析和语义分析,确保代码的结构和语义符合语言规范。编译器还可能对代码进行优化,以提高生成代码的执行效率或减少代码体积。最终,编译器会生成一个汇编语言文件,通常以 .s 为后缀。
(3)汇编阶段
在这一阶段,汇编器将编译器生成的汇编语言代码(.s 文件)转化为机器语言,也就是目标文件。目标文件包含了程序的机器码,尽管它已经是可以由计算机执行的二进制代码,但它还不能直接运行。原因是目标文件中可能存在未解决的符号引用(例如,调用的函数或访问的变量在不同的目标文件中定义),这些符号引用需要在后续的链接阶段进行解析。汇编器的输出文件通常是 .o 文件。
(4)链接阶段
链接阶段将所有生成的目标文件和所需的库文件结合起来,生成最终的可执行文件。在链接过程中,链接器负责解决目标文件中的外部符号引用,将它们与合适的库文件中的符号匹配,并将它们的地址正确地绑定到目标文件中。如果程序使用了外部库(如标准库或第三方库),链接器会将这些库中的代码也合并进来。最终,链接器会生成一个包含所有机器码和符号解析结果的可执行文件。
2、ELF 可执行文件格式
在 ELF(Executable and Linkable Format)文件中,每个部分都有其独特的作用,确保了文件能够被正确加载、执行或链接。下面是 ELF 文件的几个关键部分及其作用:
(1)ELF 文件头(ELF Header)
ELF 文件头位于 ELF 文件的开头,包含了关于 ELF 文件的基本信息。其主要作用是让操作系统或加载器了解如何解析和加载 ELF 文件。
(2)程序头表(Program Header Table)
程序头表描述了 ELF 文件如何映射到内存中的各个段,特别是在运行时的内存布局。每个程序头指明一个段(Segment),该段通常包含程序执行所需的部分。程序头表的作用是告诉操作系统如何加载 ELF 文件的各个段到内存中。程序头表是运行时加载程序时非常关键的部分,操作系统根据它将 ELF 文件中的各个段加载到正确的内存位置。
(3)节头表(Section Header Table)
节头表描述了 ELF 文件中的各个节(Section),每个节对应着不同类型的数据或代码。节头表的作用是为链接器和调试器提供信息,帮助它们理解文件的结构。节头表的每一项描述一个节。节头表还包含每个节的大小、地址、偏移等信息,帮助链接器在链接过程中将不同的节正确组合。
(4)节区(Sections)
节区是 ELF 文件的基本组成部分,包含不同类型的数据和代码。每个节用于存储特定的信息,比如程序代码、数据、符号表等。节区的结构是静态的,主要用于在链接和调试时组织文件的内容。在程序运行时,程序头表中的段描述会告诉操作系统哪些节需要加载到内存中。
(5)符号表(Symbol Table)
符号表是 ELF 文件中一个非常重要的节,它记录了程序中使用的所有符号的信息。符号表的每一项代表一个符号,符号可以是函数、变量或其他标识符。符号表有助于链接器和调试器识别程序中的各个符号,并确保程序的链接正确。
二、实验过程—装载和启动一个可执行程
1. 使用“exec库函数”加载一个可执行文件
1、进入删除原有内核,重新克隆内核,在test.c文件中新增“exec”函数
cd LinuxKernel
rm -rf menu
git clone https://github.com/mengning/menu.git
cd menu
mv test_exec.c test.c
gedit test.c
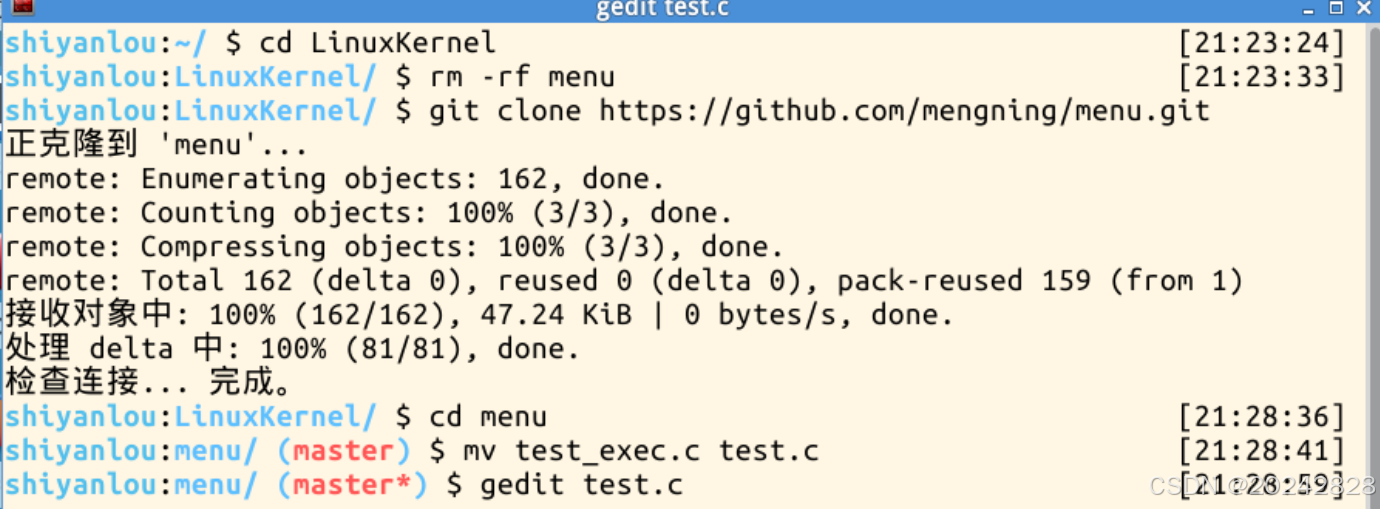
2、打开test.c文件可以看到,主函数新增了exec命令

3、编译并启动内核,查看exec函数
make rootfs
//启动内核后,在QEMU界面输入help
help
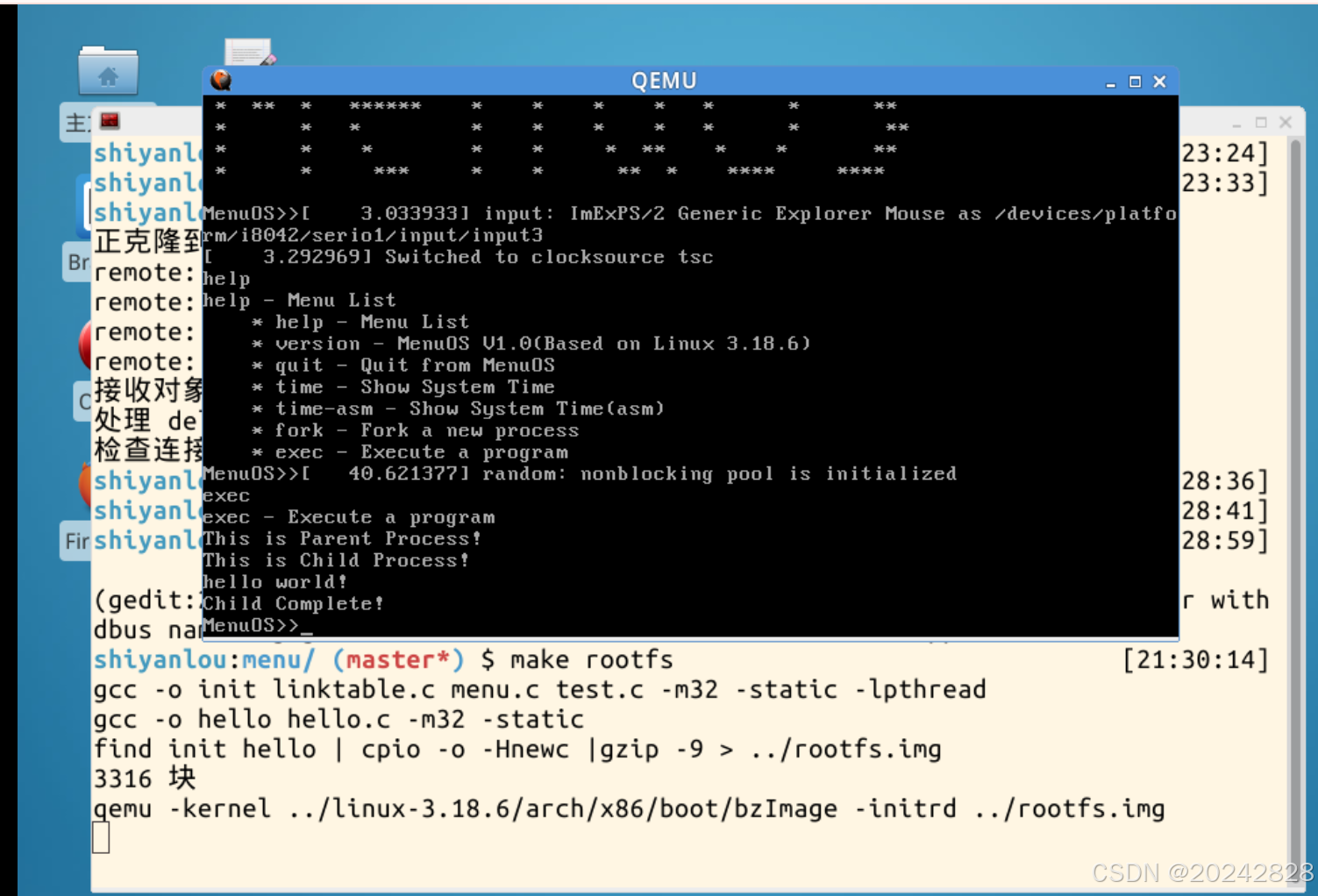
exec函数代码如下
int Exec(int argc, char *argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < 0)
{
/* error occurred */
fprintf(stderr,"Fork Failed!");
exit(-1);
}
else if (pid == 0)
{
/* child process */
printf("This is Child Process!\n");
execlp("/hello","hello",NULL);
}
else
{
/* parent process */
printf("This is Parent Process!\n");
/* parent will wait for the child to complete*/
wait(NULL);
printf("Child Complete!\n");
}
}
(1)创建子进程(fork())
代码中的第一步是调用 fork() 函数。fork() 是用于创建新进程的系统调用,它会从当前进程(父进程)创建出一个几乎完全相同的进程(子进程)。fork() 调用之后,父进程和子进程会继续执行相同的代码,但它们各自有不同的返回值:
- 如果
fork()成功,父进程会得到一个大于零的返回值(子进程的 PID),而子进程则会得到返回值0。 - 如果
fork()失败(例如由于系统资源不足),它会返回一个负值。此时程序会输出错误信息,并通过exit()终止执行。
(2)子进程的行为
如果 fork() 返回值为 0,说明当前执行的是子进程。子进程会执行以下操作:
- 它首先打印一条消息,标识当前是子进程。
- 接着,子进程调用
execlp()来执行一个外部程序。在这段代码中,子进程尝试运行/hello程序,并传递"hello"作为程序的第一个参数。execlp()函数会用指定的外部程序替换当前子进程的映像,即子进程的代码和数据将被新的程序所替代。如果执行成功,子进程的行为将完全被替换为/hello程序,后续的代码(如打印消息)将不会执行。 - 如果
execlp()调用失败(例如指定的/hello程序不存在或不可执行),子进程会继续执行剩下的代码(如果有的话),但通常会输出错误信息并退出。
(3)父进程的行为
如果 fork() 返回值大于零,说明当前执行的是父进程。父进程会执行以下操作:
- 它首先打印一条消息,表示当前是父进程。
- 然后,父进程调用
wait()函数,进入等待状态,直到子进程结束。wait()会阻塞父进程,直到其子进程终止。父进程可以通过wait()获得子进程的退出状态,但在这段代码中,父进程并不关心子进程的具体状态,因此传递了NULL作为参数。wait()确保父进程会等待子进程完成后再继续执行。 - 一旦子进程结束,父进程会打印一条消息,表示子进程已完成。
(4)父子进程的关系
在整个过程中,父进程和子进程是并行运行的。父进程通过 fork() 创建子进程后,它和子进程各自独立执行。父进程在等待子进程结束之前不会继续执行后面的代码,而子进程会根据 execlp() 的调用执行外部程序。
(5)程序结束
- 子进程:在执行
execlp()时,如果成功,子进程的映像将被/hello程序替代,此时子进程完全转变为执行/hello。如果execlp()失败,子进程可能继续执行后续代码并终止。 - 父进程:父进程会在
wait()调用之后继续执行,等待子进程完成后输出“Child Complete!”。
2.通过gdb进行跟踪分析
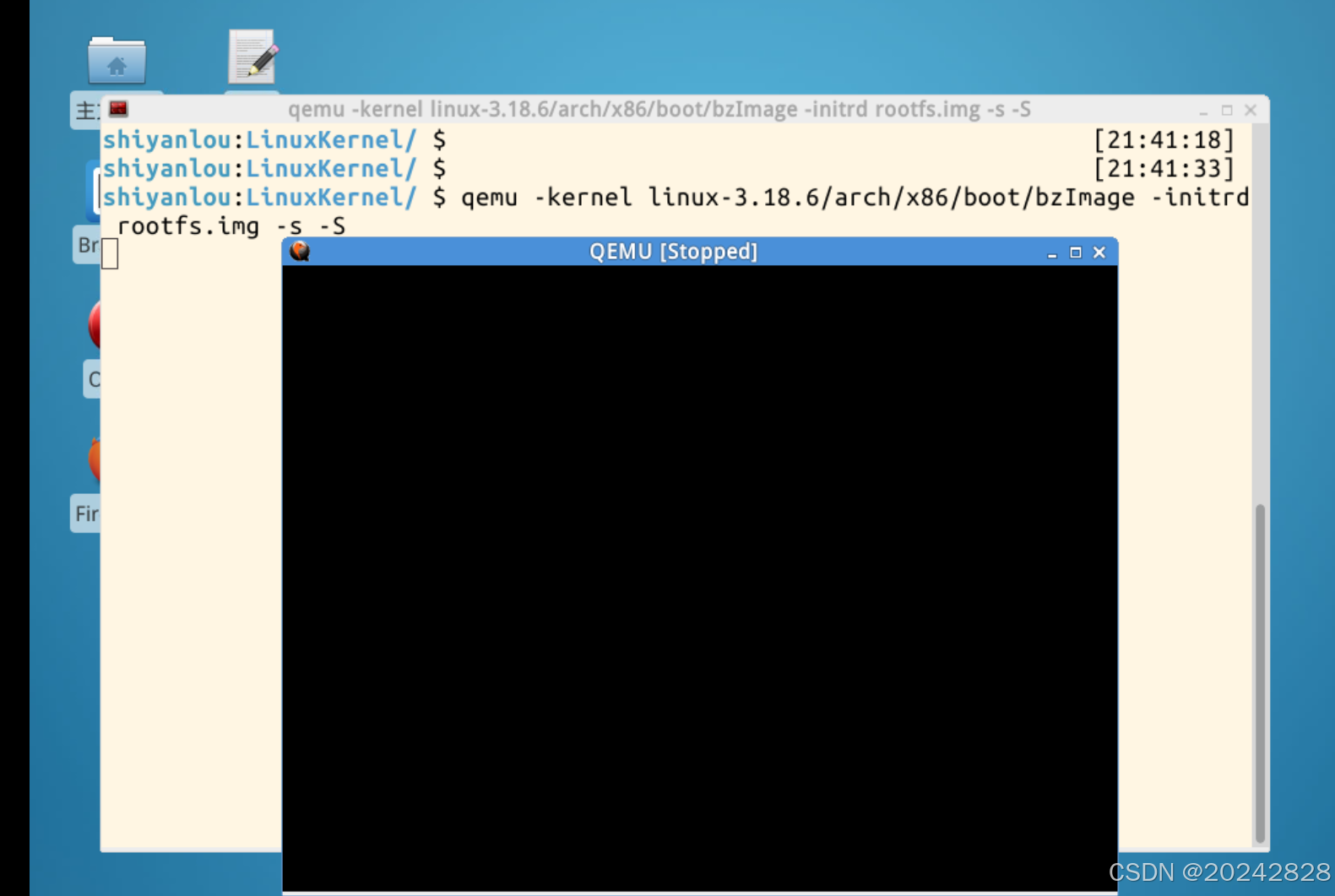
4、回退到父目录,使用下面的命令启动内核并在CPU运行代码前停下以便调试
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S
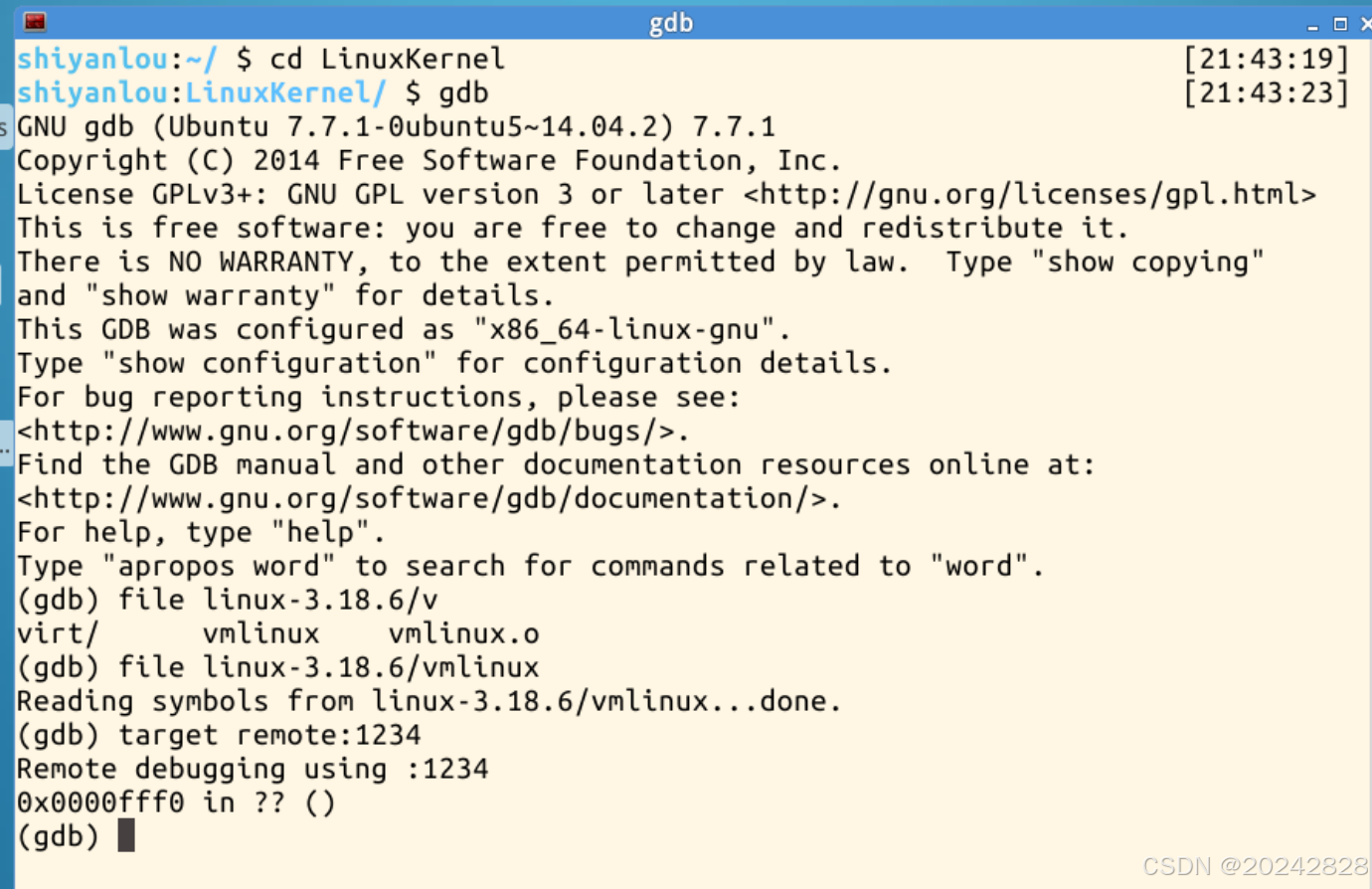
5、打开一个新的终端窗口,依次使用下面的命令启动gdb调试;
gdb
file linux-3.18.6/vmlinux
target remote:1234
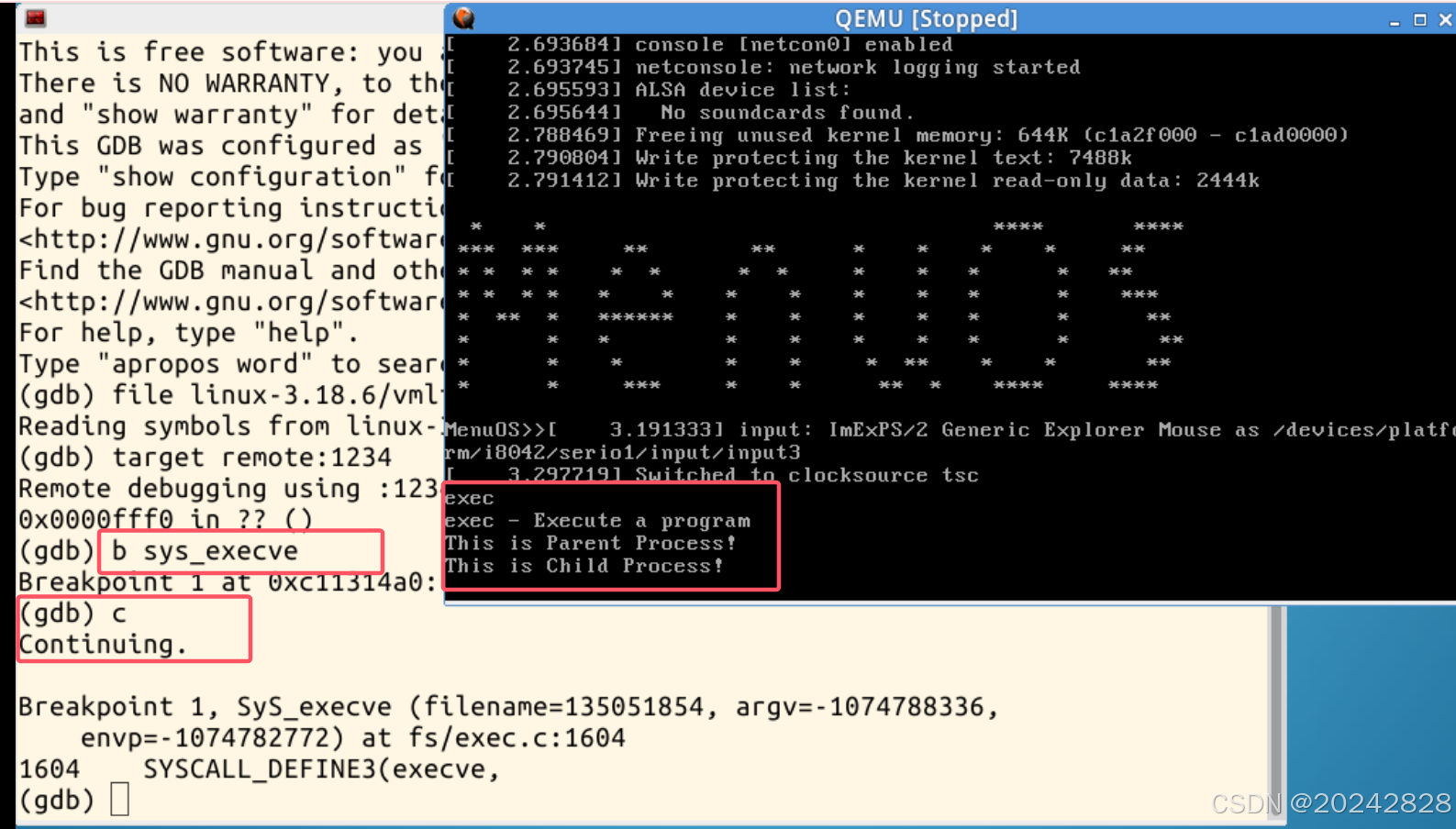
6、在系统调用sys_execve的入口处设置断点b sys_execve,继续运行程序,在QEMU窗口中输入exec,系统就会停在上面设置的断点处,如图所示
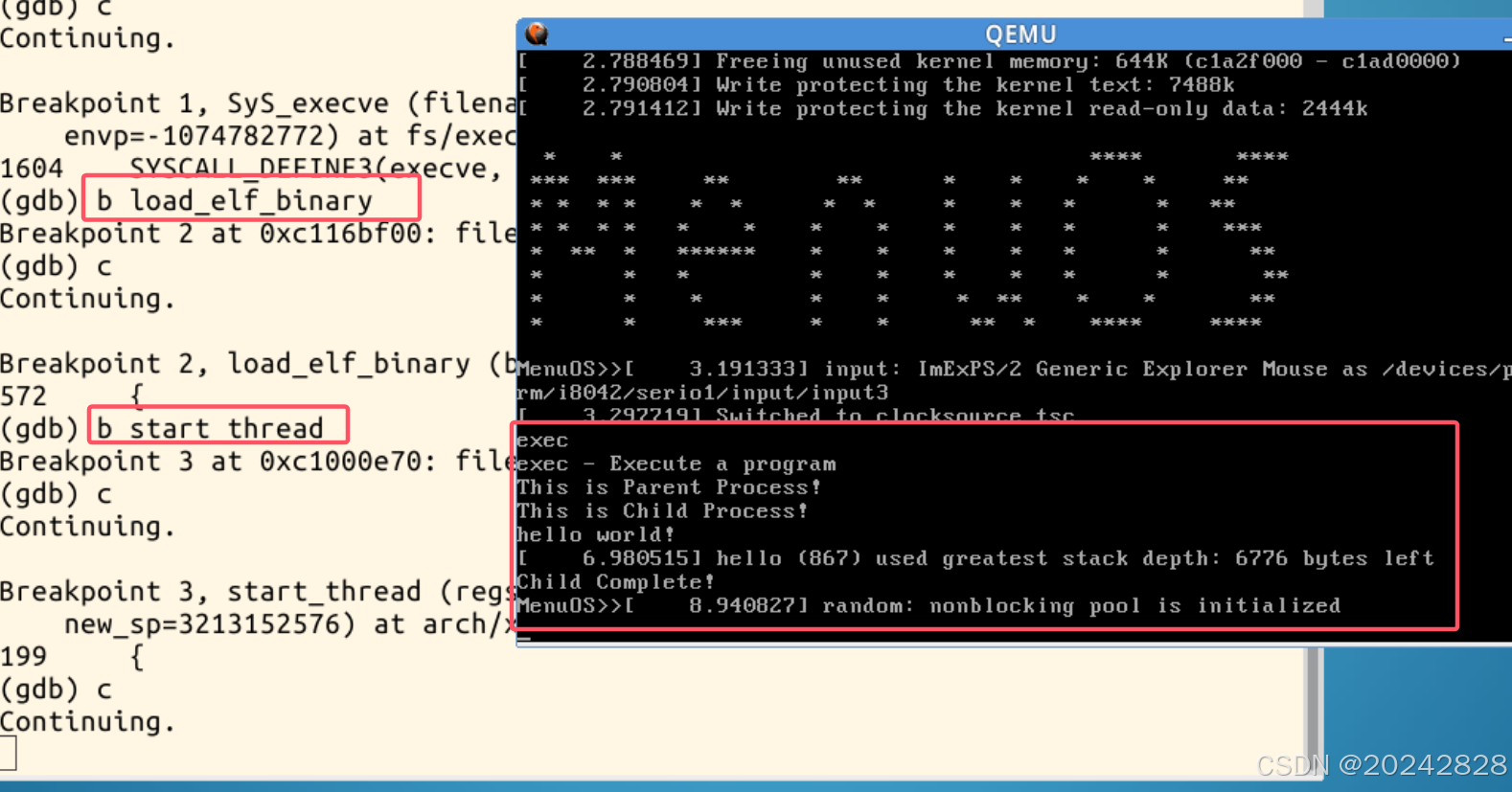
7、继续设置以下断点,可完整跟踪进程的创建和启动代码;
b load_elf_binary
b start_thread
三、总结
在Linux中,exec函数族的作用是根据指定的文件名找到可执行文件,并用它来替换调用进程的内容。这意味着当前进程的可执行文件被完全替换为新的可执行文件。可执行文件的开始执行起点是根据执行execve系统调用时压入内核堆栈的EIP寄存器的值来确定的。尽管进程的可执行文件已经被替换,但实际开始执行新的可执行文件中的指令需要等到执行新程序定义的入口地址位置,通常是0x8048xx。通过修改内核堆栈中EIP寄存器的值,将其设置为新程序的起点,使得execve系统调用返回到用户态时可以开始执行新程序。

















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









