









 本文介绍了如何在MacM2上利用Xinference这个强大的分布式推理框架部署本地模型,包括安装步骤、硬件加速选项以及如何指定从HuggingFace获取模型。部署过程中提供了详细的操作指南和本地访问方法。
本文介绍了如何在MacM2上利用Xinference这个强大的分布式推理框架部署本地模型,包括安装步骤、硬件加速选项以及如何指定从HuggingFace获取模型。部署过程中提供了详细的操作指南和本地访问方法。
想要在Mac M2 上部署一个本地的模型。看到了Xinference 这个工具
一、Xorbits Inference 是什么
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xorbits Inference 与最前沿的 AI 模型,发掘更多可能。
本地部署参考了这两个文档
部署文档
部署文档
接入 Xinference 部署的本地模型 | 中文 | Dify
二、本地部署
安装命令
pip install xinference安装成功
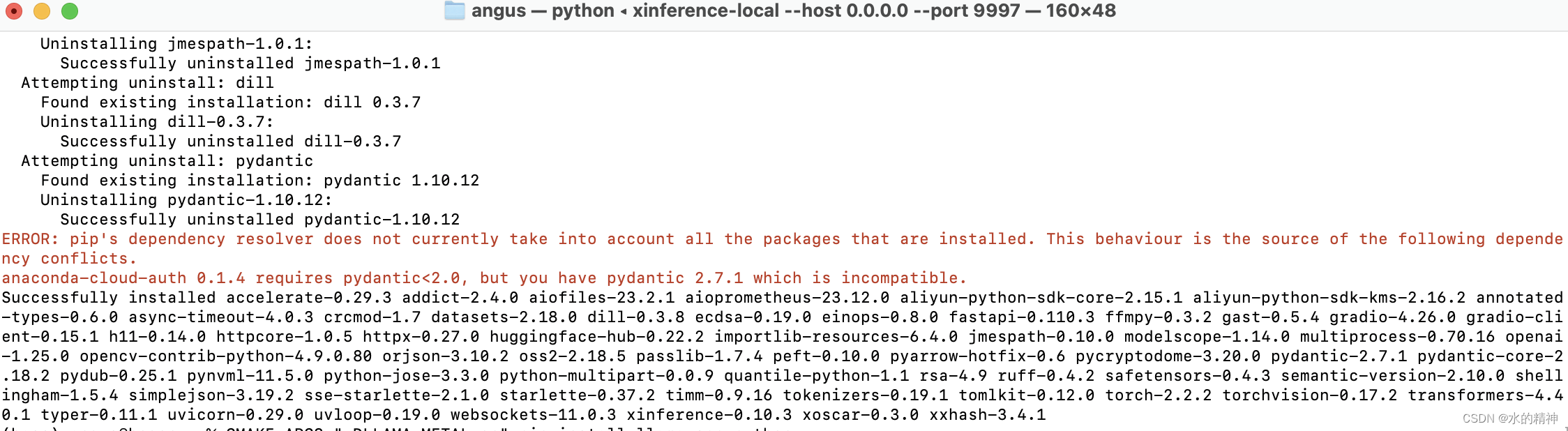
硬件加速
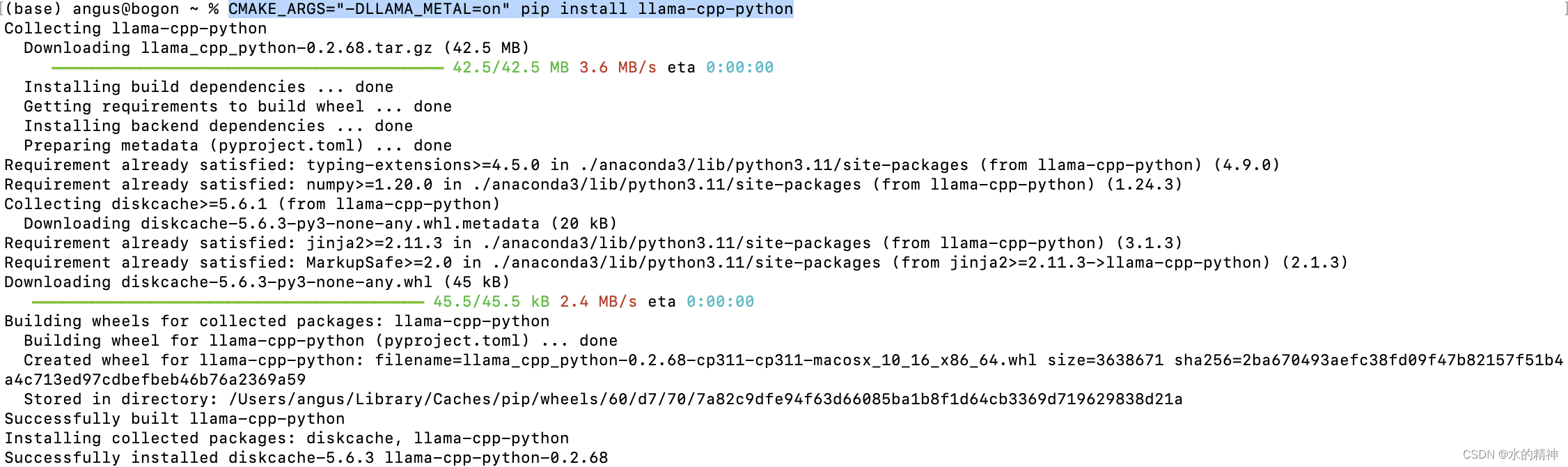
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python安装成功
启动(启动的时候,指定从魔搭上拉取模型。注意这里,国内的话用魔搭拉取会顺畅一些,国外的话可以不指定,取huggingface上去拉去模型)
XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 9997
本地访问
http://0.0.0.0:9997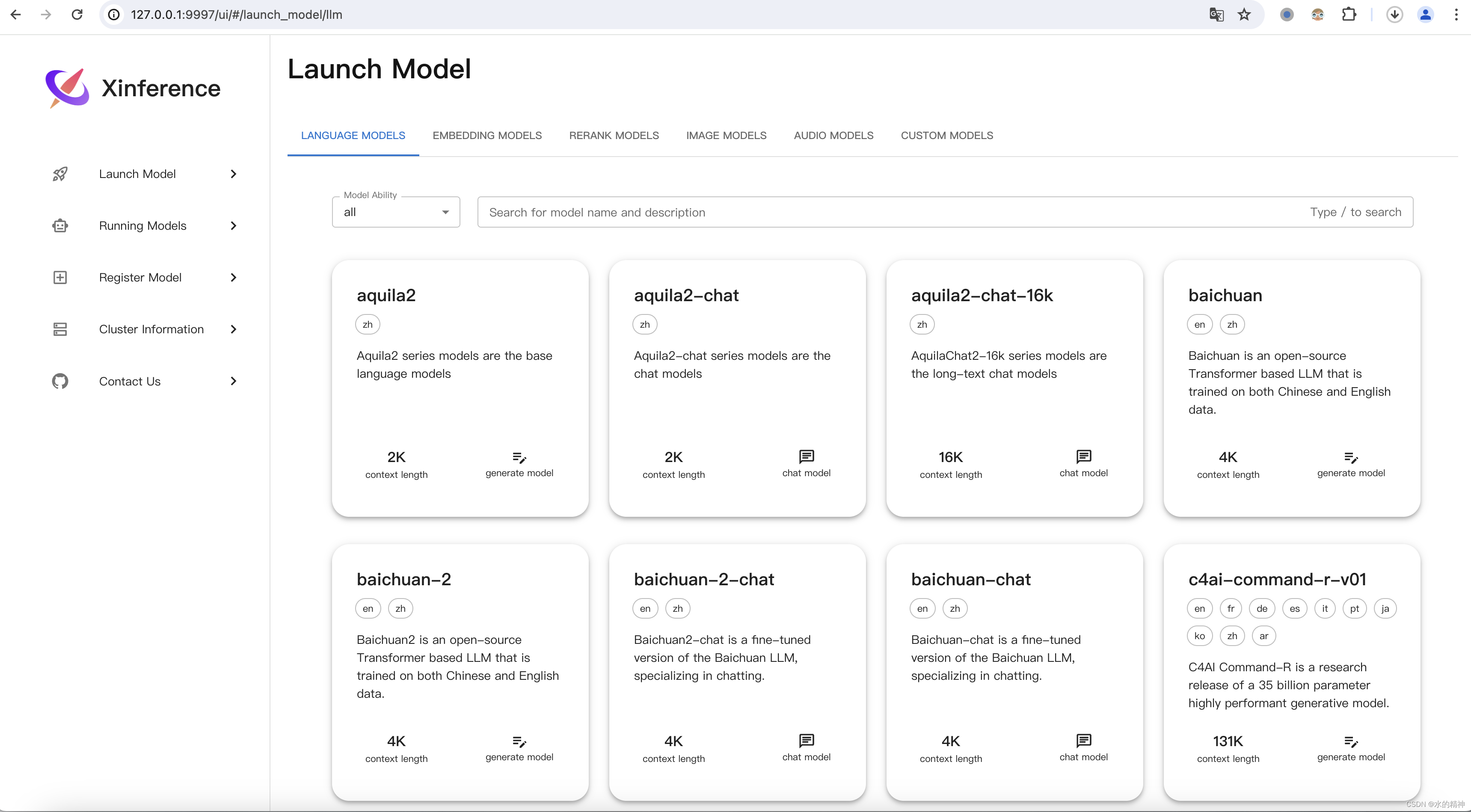

















 3887
3887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









