



我也学了有一段时间的MySQL数据库了,但是之前的内容感觉没有什么有深入交流的地方(应该是我学的还浅),所以就没有什么写博客的兴趣,这个之前学的一些东西给我的感觉就是像我们的WPS一样,全部都是使用型,这种东西在我看来,就是看一遍,自己上手操作一下,记住就好的东西,所以就没有写博客的必要,但是现在的索引和事务才有一点写的想法(主要还是没有什么内容写,不然这个我感觉也没有什么写的必要),所以废话也不多说了,正题开始。
索引
我们先聊一聊索引,索引说白了,就是一种数据结构,只不过是MySQL使用这种数据结构,而数据结构,我们都知道就是为了方便我们查找,存储数据用的,所以索引就是在MySQL为了方便我们查找数据,存储数据的一种手段,接下来我们就看看,MySQL是怎么用索引来提高我们查询,存储数据的效率吧。
二叉搜索树
首先,我们就要提到二叉树,而我们知道在二叉树中,二叉搜索树的效率是很高的,但是她还是有一些缺点的,就比如在一些特定的情况下,他的查询效率是O(N),我们知道这个效率不算高,甚至算低了,2.节点一旦过多的时候,这个树是不是会很高啊,而这个树很高的话,我们想要访问到叶子节点,是不是就要进行更多的次的操作(我们把访问子节点时的操作叫为一个IO),而我们想要提高效率就要减少IO的值,所以在此基础上,我们提出了N叉树
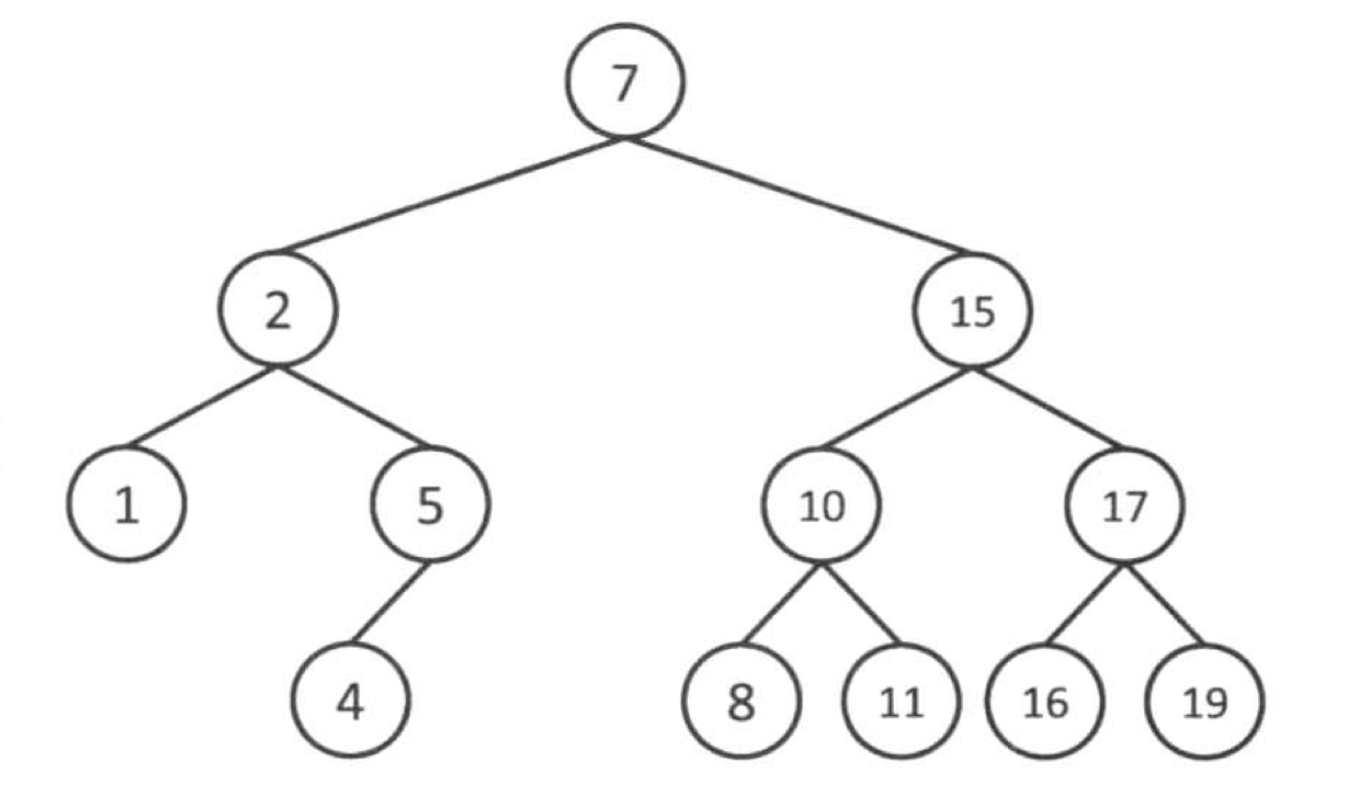
N叉树
N叉树就是为了解决树高的问题,你想想,假如我们有32个节点,在二叉树中,我们要5层才放得下,而我们设为6叉树呢,最多3层,是不是明显降低了树高,但是MySQL认为这个N叉树做的还是差了一点(后面聊),所以MySQL就使用了B+树
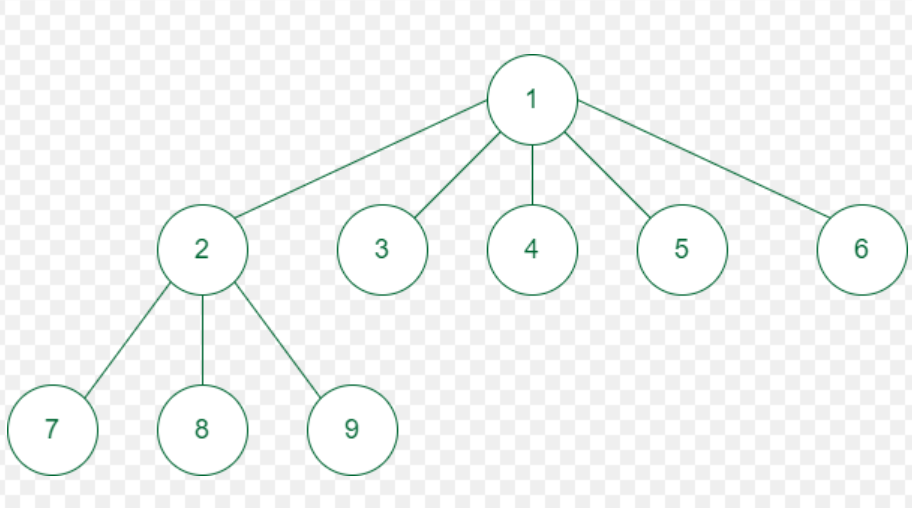
B+树
其实B+树和N叉树是很像的,就是有一点不一样,就是数据全部在叶子节点上面,非叶子节点上面就算有也是假的,这个只是一个指向,指向真实的数据。所以我们看一个例子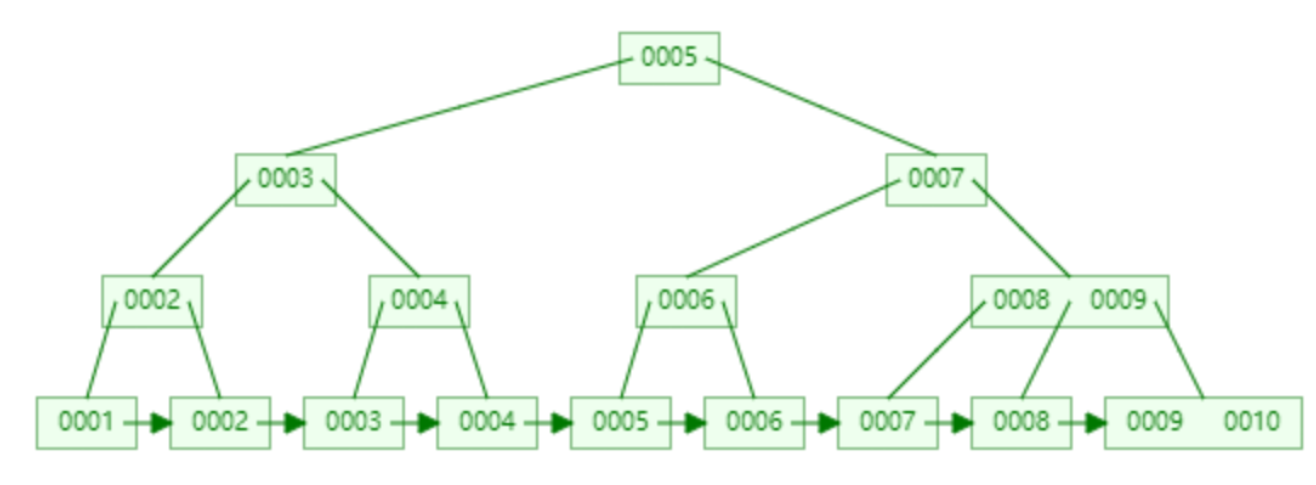
这个就是B+树。
我们来看看这个数有什么特别的地方,1.就是非叶子节点是引用(指向真实数据),2.在叶子节点中,我们可以找到全部的数据,并且成链表型(这样的特性使B+树,可以进行范围查找),3.全部数据在叶子节点上面,我们要进行的IO次数一样,所以查询的效率很稳定。这些也是B+树要好于N叉树的原因,而我们的每一个叶子节点里面就是存储MySQL的数据了,但是不是直接把数据存储进去,而是放在一个页中,而这个页是内存和磁盘交互的最小标准,默认为16KB(为什么,我也不知道,嘻嘻)
页
现在我们看看页是怎么存储数据的
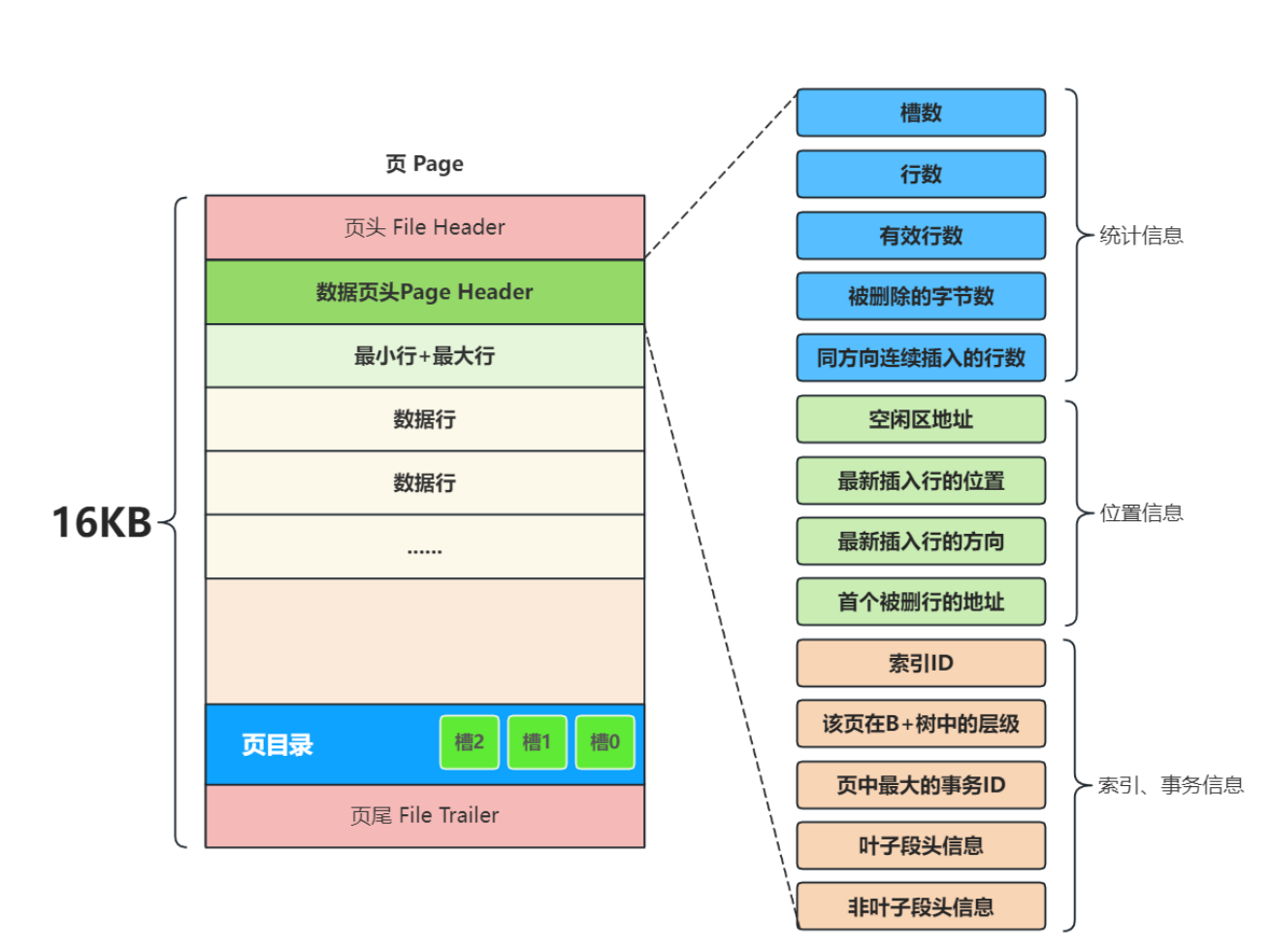
这个图画的很清晰,我们从上往下看,首先是数据页头,而数据页头里面,我们不存储数据,是为了查找数据而存在的,所以我们他存储的数据就是
其实也很好理解,我们假如不设置这些东西,是不是一个页中就全部是数据,就像一个垃圾场,什么东西都往里面丢,找起来的时候就特别难,但是我们像这样对数据进行管理,就可以显著的提升效率,其实也就是用空间换效率的操作,接下来就是最大最小行,其实就是我们数据第一个数据和最后一个数据,有点意思的就是页目录了,这个就像我们看书,我们想找一个知识点,我们就可以先看目录,根据目录来判断这个知识点在什么范围,页目录也是一样,我们是用主键id值和槽中的值进行比较,从而判断范围。
我们在扩展一点就是一个三层的B+树可以存放多少数据,我们假设数据为1KB,我们忽略页头这些的消耗,所以一页就是16条数据,而我们叶子节点的大小也是16KB,一个主键是8ByTe(bigint),而下一个节点地址是6ByTe,所以一个主键和一个地址就是14ByTe,所以一个索引就可以保存16*1024/14 = 1170个节点,一共就是1170*1170*16 = 21902400条数据,你想想我们在这么多条数据中找到一条,我们只需要3次IO,所以这个性能真的太吊了。
事务
什么是事务,其实很简单,就是把我们要做的事打包一下,要不不做,要不全部做完,(人生也是一样,要不就一直努力,不断超越极限,杀到九天十地无人敢称尊,要不就一直躺平,就怕高不成低不就,但是事实就是,就算我们拼尽了一切,我们还是无法有所成就,而我唯有两字——坚持,我很喜欢一句话,我清楚的知道人与人的路是不可复制的,我走在自己的人生道路上,哪怕路途的风雨再大,大到我步履维艰,哪怕荆棘丛生,刺的我伤痕遍地,我也依旧痴痴笑笑,我体会此中滋味,所以朋友不必后悔,因为你怎么选择,都是你自己的人生道路啊)偏题了,我们开始聊事务,就比如说转钱,你给我100块(自愿啊),是不是你微信就少100,而我微信就多100,我们把这些包起来就是一个事务,我们来看看事务的4个特性
事务的ACID特性指的是 Atomicity (原⼦性), Consistency (⼀致性), Isolation (隔离 性)和 Durability (持久性)。
我们不看定义,我们根据那个例子来理解,1,原子性就是要不全部成功,要不全部不成功,假如不成功就返回到开始的样子,因为总不能,你转钱给我,你转出来了,而我没有收到吧。
2,一致性,转钱之前,假如你和我都是1000块,我们两个加起来就是2000,而转钱之后你900,我1100,加起来还是2000,这个就是一致性。
4.持久性,事务处理完了,我们就会把他写入存储介质,保存起来。
3.隔离性(最后写是因为,这个才是我要写的原因(有点意思))
READ UNCOMMITTED ,读未提交
READ COMMITTED ,读已提交
REPEATABLE READ ,可重复读(默认)
SERIALIZABLE ,串⾏化
这个是隔离的四个标准,假如我用数据来举例子感觉有点枯燥,所以我就以玩具来举例子。
假如说你和我是好朋友,我们有很多玩具,我在玩变形金刚的时候,你也想玩,所以我和我都一起在玩变形金刚,我把变形金刚的头拔掉了,是不是你手上的变形金刚头也没有了(因为我们玩同一个)(这个样子就是读未提交,我随便改数据,你同时也可以随便改数据,),你可能就觉得我是个sb,所以你不想要我玩你手上的变形金刚,所以我要玩,你就和我打架,但是我还是想我,但是我打不过你,所以我就等你玩完了,我再玩,假如我把变形金刚的脚拔掉了,你下次玩的时候,是不是脚的没了(玩具还是同一个,但是时间不同)(这个就是读已提交,提交就是相当于你不玩了,你提交了,我再玩,但是你下次玩的时候,其实是我玩剩下的)(这个也叫不可重复读,因为第二次读的不一定是一样的)你看到,变形金刚脚又没了,你很生气把我打了一顿,说:“你不可以玩这个玩具,你玩了,我就打你”(你是霸道总裁),我打不过你,所以我就再也没有玩过这个了,但是我可以玩别的玩具啊,所以我就开始玩飞机了,(这个就是可重复读,你使用的这个小包没事,但是在同一个大包的其他小包,就可能有问题,在上面的情节就是我和你玩你家的玩具(不止一个),我不玩变形金刚了,我玩你家的飞机),最后一个串行化就是你把玩具卖了,我在买回来玩(就是你全部操作完成,我再操作)
你想想我们的隔离程度再一步一步的提高,因此付出的代价是效率一步一步的降低,所以我们要选择最合适的。
欧克,喜欢的朋友就喜欢吧(都看到这了,还不点赞,过分了啊)

















 1212
1212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









