







一、概述
移动平均法的预测值实质上是以前观测值的加权和,且对不同时期的数据给予相同的加权。这往往不符合实际情况。
指数平滑法则对移动平均法进行了改进和发展,其应用较为广泛。
基本思想都是:预测值是以前观测值的加权和,且对不同的数据给予不同的权,新数据给较大的权,旧数据给较小的权。
根据平滑次数不同,指数平滑法分为:一次指数平滑法、二次指数平滑法和三次指数平滑法等。
一次指数平滑法针对没有趋势和季节性的序列,
二次指数平滑法针对有趋势但没有季节性的序列,
三次指数平滑法针对有趋势也有季节性的序列。“Holt-Winters”有时特指三次指数平滑法。
一次指数平滑法:
一次指数平滑法的递推关系如下:
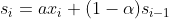 ,其中,
,其中,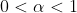
其中,是时间步长i(理解为第i个时间点)上经过平滑后的值, 是这个时间步长上的实际数据。 可以是0和1之间的任意值,它控制着新旧信息之间的平衡:当 接近1,就只保留当前数据点;当 接近0时,就只保留前面的平滑值(整个曲线都是平的)。我们展开它的递推关系式:
![s_{i}=ax_{i} + (1-\alpha )s_{i-1} =ax_{i} + (1-\alpha )\left [ ax_{i-1} + (1-\alpha)s_{i-2} \right ] = ax_{i} + (1-\alpha )\left [ ax_{i-1} + (1-\alpha)\left [ax_{i-2} + (1-\alpha )s_{i-3} \right ] \right ]=....=\alpha \sum_{j=0}^{i} \left ( 1-\alpha \right )^{j}_{i-j}](https://i-blog.csdnimg.cn/blog_migrate/7ed6c75738cc7f3c03a77ab927702b13.gif%20%3Dax_%7Bi%7D%20+%20%281-%5Calpha%20%29%5Cleft%20%5B%20ax_%7Bi-1%7D%20+%20%281-%5Calpha%29s_%7Bi-2%7D%20%5Cright%20%5D%20%3D%20ax_%7Bi%7D%20+%20%281-%5Calpha%20%29%5Cleft%20%5B%20ax_%7Bi-1%7D%20+%20%281-%5Calpha%29%5Cleft%20%5Bax_%7Bi-2%7D%20+%20%281-%5Calpha%20%29s_%7Bi-3%7D%20%5Cright%20%5D%20%5Cright%20%5D%3D....%3D%5Calpha%20%5Csum_%7Bj%3D0%7D%5E%7Bi%7D%20%5Cleft%20%28%201-%5Calpha%20%5Cright%20%29%5E%7Bj%7D_%7Bi-j%7D)
可以看出,在指数平滑法中,所有先前的观测值都对当前的平滑值产生了影响,但它们所起的作用随着参数 的幂的增大而逐渐减小。那些相对较早的观测值所起的作用相对较小。同时,称α为记忆衰减因子可能更合适——因为α的值越大,模型对历史数据“遗忘”的就越快。从某种程度来说,指数平滑法就像是拥有无限记忆(平滑窗口足够大)且权值呈指数级递减的移动平均法。一次指数平滑所得的计算结果可以在数据集及范围之外进行扩展,因此也就可以用来进行预测。预测方式为:
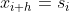
 是最后一个已经算出来的值。h等于1代表预测的下一个值。
是最后一个已经算出来的值。h等于1代表预测的下一个值。
二次指数平滑法
在介绍二次指数平滑前介绍一下趋势的概念。
趋势,或者说斜率的定义很简单:b=Δy/Δx,其中Δx为两点在x坐标轴的变化值,所以对于一个序列而言,相邻两个点的Δx=1,因此b=Δy=y(x)-y(x-1)。 除了用点的增长量表示,也可以用二者的比值表示趋势。比如可以说一个物品比另一个贵20块钱,等价地也可以说贵了5%,前者称为可加的(addtive),后者称为可乘的(multiplicative)。在实际应用中,可乘的模型预测稳定性更佳,但是为了便于理解,我们在这以可加的模型为例进行推导。
指数平滑考虑的是数据的baseline,二次指数平滑在此基础上将趋势作为一个额外考量,保留了趋势的详细信息。即我们保留并更新两个量的状态:平滑后的信号和平滑后的趋势。公式如下:

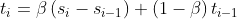
第二个等式描述了平滑后的趋势。当前趋势的未平滑“值”( )是当前平滑值( )和上一个平滑值( )的差;也就是说,当前趋势告诉我们在上一个时间步长里平滑信号改变了多少。要想使趋势平滑,我们用一次指数平滑法对趋势进行处理,并使用参数 (理解:对 的处理类似于一次平滑指数法中的 ,即对趋势也需要做一个平滑,临近的趋势权重大)。
为获得平滑信号,我们像上次那样进行一次混合,但要同时考虑到上一个平滑信号及趋势。假设单个步长时间内保持着上一个趋势,那么第一个等式的最后那项就可以对当前平滑信号进行估计。
若要利用该计算结果进行预测,就取最后那个平滑值,然后每增加一个时间步长就在该平滑值上增加一次最后那个平滑趋势:

三次指数平滑法(holt-winters)
三次指数平滑就是Holt-Winters方法,不用说,它的提出肯定是和两个叫Holt和Winters的人有关了。
Holt(1957)和Winters(1960)扩展了Holt的方法来捕捉季节性。Holt-Winters季节性方法包括预测方程和三个平滑方程 - 一个用于水平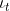 ,一个趋势
,一个趋势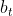 和一个季节性成分
和一个季节性成分 ,具有相应的平滑参数
,具有相应的平滑参数 ,
, 和
和 。我们用m表示季节性的频率,即一年中的季节数。
。我们用m表示季节性的频率,即一年中的季节数。
例如,对于季度数据m = 4,月度数据m = 12。
这种方法有两种变化,季节性成分的性质不同。当季节变化在整个系列中大致恒定时,加法方法是优选的,而当季节变化与系列水平成比例变化时,乘法方法是优选的。使用加法方法,季节性成分以观察到的序列的尺度以绝对值表示,并且在水平方程中,通过减去季节性成分对季节性调整系列进行季节性调整。在每年内,季节性成分将加起来大约为零。使用乘法方法,季节性成分以相对值(百分比)表示,系列通过除以季节性成分进行季节性调整。
当一个序列在每个固定的时间间隔中都出现某种重复的模式,就称之具有季节性特征,而这样的一个时间间隔称为一个季节(理解:比如说在一个周内,销量呈现出重复的模式)。一个季节的长度k为它所包含的序列点个数。
二次指数平滑考虑了序列的baseline和趋势,三次就是在此基础上增加了一个季节分量。类似于趋势分量,对季节分量也要做指数平滑。比如预测下一个季节第3个点的季节分量时,需要指数平滑地考虑当前季节第3个点的季节分量、上个季节第3个点的季节分量...等等。详细的有下述公式(累加法):

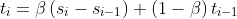
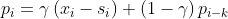
其中, 是指“周期性”部分。预测公式如下:
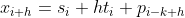
 是这个周期的长度。
是这个周期的长度。
参数选择:
 的值都位于[0,1]之间,可以多试验几次以达到最佳效果。当然,一些寻优方法,比如贝叶斯调参,网格调参可用于调整参数。
的值都位于[0,1]之间,可以多试验几次以达到最佳效果。当然,一些寻优方法,比如贝叶斯调参,网格调参可用于调整参数。
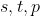 初始值的选取对于算法整体的影响不是特别大,通常的取值为
初始值的选取对于算法整体的影响不是特别大,通常的取值为  累加时
累加时  ,累乘时
,累乘时  。
。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









