









 本文介绍了使用Selenium进行自动化测试的技巧,特别是针对表格数据抓取的方法,详细讲解了如何定位和遍历表格元素,适用于初学者。
本文介绍了使用Selenium进行自动化测试的技巧,特别是针对表格数据抓取的方法,详细讲解了如何定位和遍历表格元素,适用于初学者。
写在最前面:
一点selenium自动化测试的常用技巧介绍,小白专用。
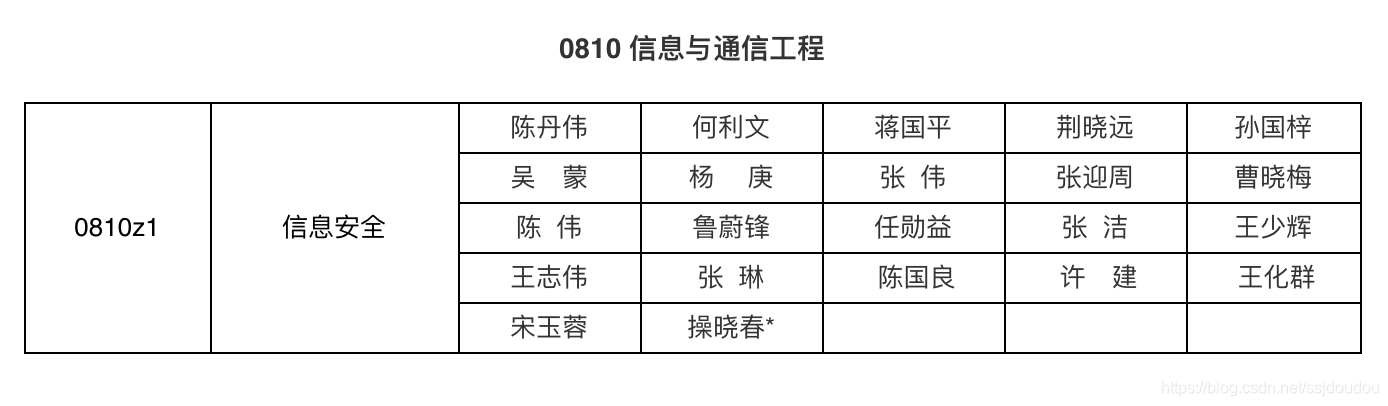
我邮的研究生网站上的一个table,想要把所有的信息扒下来,怎么处理呢?
<tr height="19">
<td style="border-bottom:#000000 1px solid;text-align:center;border-left:#000000 1px solid;font-style:normal;width:110px;height:76px;color:#000000;font-size:13px;vertical-align:middle;border-top:#000000 1px solid;font-weight:400;border-right:#000000 1px solid;text-decoration:none;mso-protection:locked visible" class="et3" rowspan="5" width="110" colspan="1">0810z1</td>
<td style="border-bottom:#000000 1px solid;text-align:center;border-left:#000000 1px solid;font-style:normal;width:162px;height:76px;color:#000000;font-size:13px;vertical-align:middle;border-top:#000000 1px solid;font-weight:400;border-right:#000000 1px solid;text-decoration:none;mso-protection:locked visible" class="et3" rowspan="5" width="162" colspan="1">信息安全</td>
<td style="border-bottom:#000000 1px solid;text-align:center;border-left:#000000 1px solid;font-style:normal;width:109px;height:19px;color:#000000;font-size:13px;vertical-align:middle;border-top:#000000 1px solid;font-weight:400;border-right:#000000 1px solid;text-decoration:none;mso-protection:locked visible" class="et3" height="19" width="109"><a href="http://yjs.njupt.edu.cn/epstar/web/outer/dsfc_ny_.jsp?dsgh=19980003">陈丹伟</a></td>
<td style="border-bottom:#000000 1px solid;text-align:center;border-left:#000000 1px solid;font-style:normal;width:72px;height:19px;color:#000000;font-size:13px;vertical-align:middle;border-top:#000000 1px solid;font-weight:400;border-right:#000000 1px solid;text-decoration:none;mso-protection:locked visible" class="et3" height="19" width="72"><a href="http://yjs.njupt.edu.cn/epstar/web/outer/dsfc_ny_.jsp?dsgh=20120102">何利文</a></td>
<td style="border-bottom:#000000 1px solid;text-align:center;border-left:#000000 1px solid;font-style:normal;width:72px;height:19px;color:#000000;font-size:13px;vertical-align:middle;border-top:#000000 1px solid;font-weight:400;border-right:#000000 1px solid;text-decoration:none;mso-protection:locked visible" class="et3" height="19" width="72"><a href="http://yjs.njupt.edu.cn/epstar/web/outer/dsfc_ny_.jsp?dsgh=20120081">蒋国平</a></td>
<td style="border-bottom:#000000 1px solid;text-align:center;border-left:#000000 1px solid;font-style:normal;width:72px;height:19px;color:#000000;font-size:13px;vertical-align:middle;border-top:#000000 1px solid;font-weight:400;border-right:#000000 1px solid;text-decoration:none;mso-protection:locked visible" class="et3" height="19" width="72"><a href="http://yjs.njupt.edu.cn/epstar/web/outer/dsfc_ny_.jsp?dsgh=20070009">荆晓远</a></td>
<td style="border-bottom:#000000 1px solid;text-align:center;border-left:#000000 1px solid;font-style:normal;width:72px;height:19px;color:#000000;font-size:13px;vertical-align:middle;border-top:#000000 1px solid;font-weight:400;border-right:#000000 1px solid;text-decoration:none;mso-protection:locked visible" class="et3" height="19" width="72"><a href="http://yjs.njupt.edu.cn/epstar/web/outer/dsfc_ny_.jsp?dsgh=20020022">孙国梓</a></td></tr>
这是一个html页面,很显然只有一个tr-代表一行,td-代表一列,那么我们不需要遍历所有行,只需找到一行的所有列即可。
由于该table没有id之类的,我们用xpath找到table所在位置,然后找到该行所有列,遍历即可。
首先copy该table的xpath
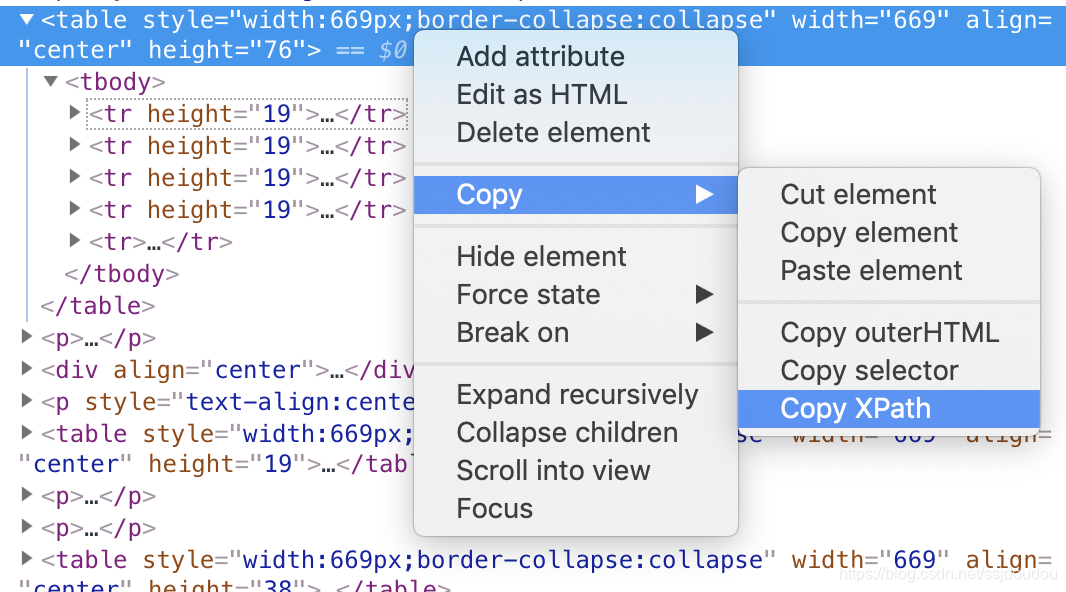
然后通过tag_name = 'td'遍历所有列
from selenium import webdriver
import time
if __name__ == "__main__":
driver = webdriver.Chrome()
driver.get('http://cs.njupt.edu.cn/2010/0510/c9392a110578/page.htm')
trs = driver.find_element_by_xpath('/html/body/div[4]/div/div[2]/div/div/div/div/table[1]')
tds = trs.find_elements_by_tag_name('td')
print(trs)
print(tds)
time.sleep(3)
info = []
for td in tds:
info.append(td.text)
print(info)
最后打印结果:
['0810z1', '信息安全', '陈丹伟', '何利文', '蒋国平', '荆晓远', '孙国梓',
'吴\u3000蒙', '杨 \u3000庚', '张 伟', '张迎周', '曹晓梅',
'陈 伟', '鲁蔚锋', '任勋益', '张 洁', '王少辉',
'王志伟', '张 琳', ' 陈国良', ' 许\u3000建', ' 王化群',
'宋玉蓉', '操晓春*', '', '', '']
如果有多行的话,再遍历一次行即可:
for tr in trs:
for td in tr.find_elements_by_tag_name('td'):
info.append(td.text)
print(info)

















 1228
1228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









