







 本文档介绍了两种网页表格结构的处理方法。第一种涉及通过XPath定位和遍历表格元素来获取数据。第二种讲解了如何针对下拉列表,通过CSS选择器找到列表项,并根据内容进行选择操作。内容涵盖了网页自动化测试和数据抓取的关键步骤。
本文档介绍了两种网页表格结构的处理方法。第一种涉及通过XPath定位和遍历表格元素来获取数据。第二种讲解了如何针对下拉列表,通过CSS选择器找到列表项,并根据内容进行选择操作。内容涵盖了网页自动化测试和数据抓取的关键步骤。
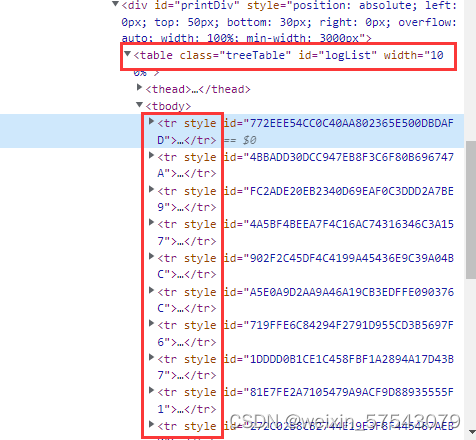
害怕记不住,存个在这里。 一、第一种网页表格结构(表格内容显示) 1、先看下图网页源码,根据源码分析网页结构: https://img-blog.csdnimg.cn/b3d8c4c4f0e9452fae1d37b3151ffc77.png 2、经过分析后: 需要先定位表格并获取 table=driver.find_element_by_xpath('/html/body/div[3]/table')#定位网页表格位置 获取表格包含的行,并将行数赋值 table_rows=table.find_elements_by_tag_name('tr')# table包含行数的集合,包含标题 vrows=len(table_rows)#将总行数赋给变量 #table_cols=table_rows[0].find_elements_by_tag_name('th')# tabler的总列数 遍历每行第2列(by_tag_name('td')[1])的值,也可以获取其他列只需要将[1]更改为需要获取的列即可。 for table_num in range(1, vrows): table_text=table_rows[table_num].find_elements_by_tag_name('td')[1].text#遍历每行第2列获取单元格的值。
二、第二种网页表格结构(下拉列表)
1、先看下图网页源码,根据源码分析网页结构:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6728
6728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}