



一、概论
看下时间线:OpenAI今年8月推出GPT-5后,11月即发布升级版本GPT-5.1,转眼不到一个月就再次更新。
在12月11日发布其人工智能模型GPT的最新升级版本GPT-5.2,以应对生成式人工智能领域日趋激烈的竞争。
这篇文章我从核心亮点以及数据来分析:
二、亮点
1 先来看看核心技术:
优点:
视觉和长上下文:在处理大型代码库方面和理解图像中的位置有了大幅提升
代码生成能力提升巨大:能力更谨慎、更强、更自主,并且愿意编写多得多的代码。
指令遵循和任务意愿:GPT-5.2 Thinking 在指令遵循和尝试完成困难任务的意愿上,迈出了有意义的一步
缺点:
速度是主要缺点:即使是简单直接的问题,速度也非常非常慢
2 再来看横向对比:
就拿Claude Opus 4.5和Gemini 3 Pro 来对比
在前端UI生成方面:GPT-5.2 Thinking 和 Pro 都比之前的 GPT 模型有进步,但两者都不及 Gemini 3 Pro
如果需要功能正确、能处理边缘情况的UI,Opus 或 GPT最好
如果只是追求漂亮,并愿意自己修复代码,Gemini 3 Pro 是目前最佳选择
在快速提问方面:Claude Opus 4.5 比GPT和Gemini更好更快
在研究和复杂推理方面:GPT-5.2 Pro 明显更胜一筹
3 再看提示词编写
GPT-5.2 非常擅长编写提示词,这对于充分利用 AI 模型和构建集成 LLM 的软件都很有帮助。它与 Claude Opus
4.5 不相上下,并且明显优于 Gemini 3 Pro
4 最后看看使用场景
在 Codex CLI 中进行严肃的编码工作方面:GPT-5.2 是首选,其上下文收集行为和可靠性使其成为智能体编码任
务的默认选项
在前端样式和UI美学方面:推荐Gemini 3 Pro
在深度研究、复杂推理方面:在这种场景下,要追求正确性比,而非速度,那么GPT-5.2 Pro 是最好的选择
在快速提问和日常任务方面:选择快、准,不浪费时间的Claude Opus 4.5
三、数据分析
1 Open AI 拿了GPT-5.2、GPT-5.1、Opus 4.5、Gemini 3 pro 来作对比,以下是数据

2 再来看 GDPval评测,这是一项覆盖 44 个职业、用于衡量明确知识型工作任务的评估
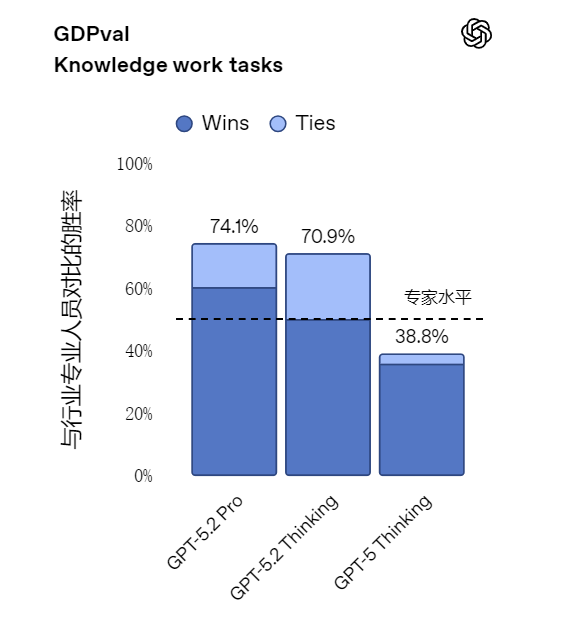
在 GDPval 测试中,模型尝试完成定义明确的知识型工作,内容涵盖美国 GDP 贡献度最高的 9 个
行业中的 44 种职业。任务要求生成真实的工作成果,例如销售演示文稿、会计表格、急诊排班
表、制造业图表或短视频。在ChatGPT 中,GPT‑5.2 Thinking 拥有 GPT‑5 Thinking 所不具备的
新工具
3 工具调用
官方用了Tau2 bench Telecom 测试
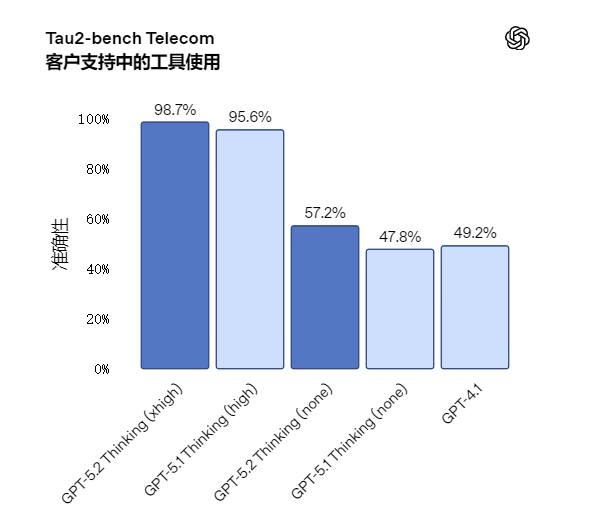
GPT‑5.2 Thinking 在 Tau2 bench Telecom 测试中取得了 98.7% 的全新优异成绩
在对延迟敏感的场景中,GPT‑5.2 Thinking 在 reasoning.effort='none' 模式下也有显著提升,性能
大幅领先GPT‑5.1 和 GPT‑4.1
4 编码能力
官方用了SWE-bench Pro来测评,这是一项严格评估真实软件工程能力的基准测试
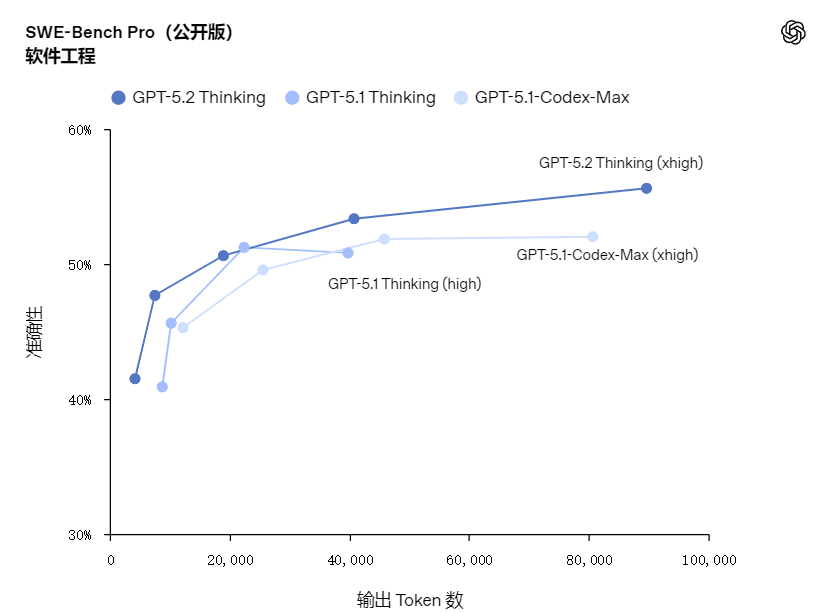
GPT‑5.2 Thinking 在 SWE-bench Pro 测试取得了 55.6% 的新成绩
四、总结
总体而言,GPT‑5.2 在通用智能、长上下文理解、智能体工具调用以及视觉方面都有显著提升,
使其在端到端执行复杂的真实任务时,比以往任何模型都更为出色

















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









