




【从零构建大模型】第二章,embeddbing构建思路总结
1. 概述
本文,作为笔者,学习《从零构建LLM》书籍的笔记,总结章节核心内容,方便理解与回顾。
作者写了做个文章在下面公众号(驾驭AI美未来、大模型生产力指南),目的是提升大模型、智能体的理解,提高大家生产力,欢迎关注、点赞。
录了个视频课程,欢迎学习。
【从零构建大模型】 视频课程讲解,一步步带你理解大模型底层原理
2. 理解embeddng
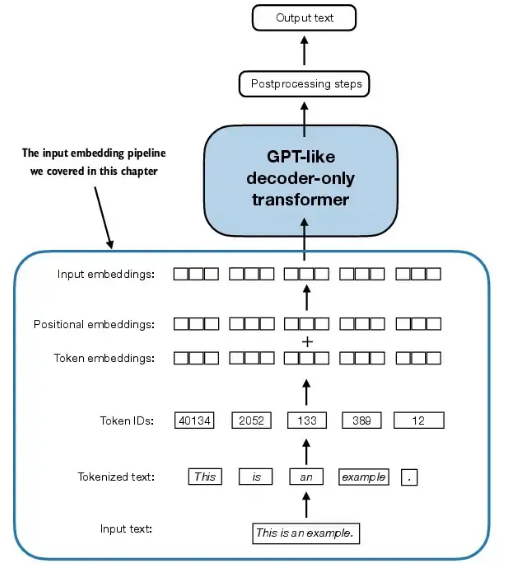
本文从零构建LLM,分为三个阶段,第一阶段,构建一个LLM, 第二阶段训练模型,第三阶段进行微调,从第一阶段embedding
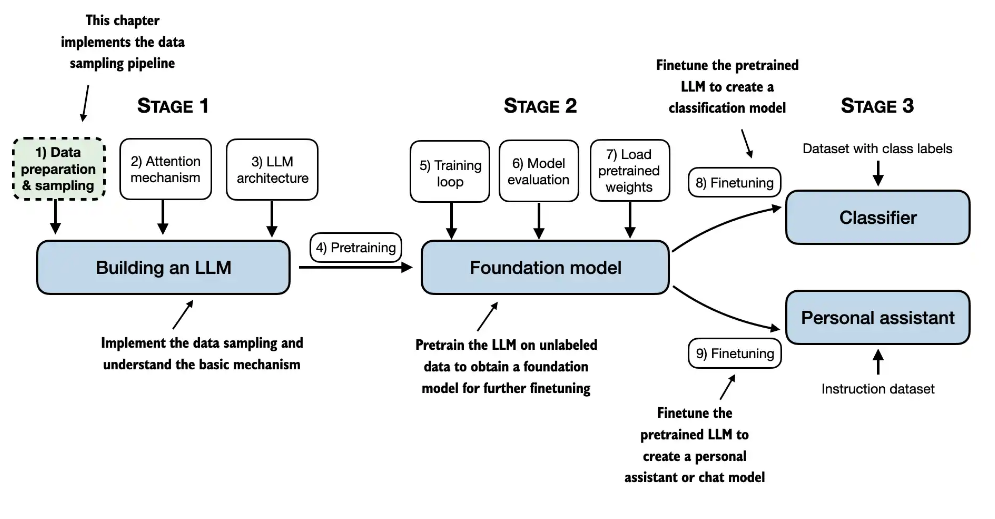
2.1 文本词元化
核心思想: 将连续的文本序列转化为离散的基本单元(即 token)”,中文固定译为 “分词” 或 “标记化”,在处理中文时可能表现为 “将句子拆分为单个汉字或词语”,处理英文时则常拆分为单词、标点等
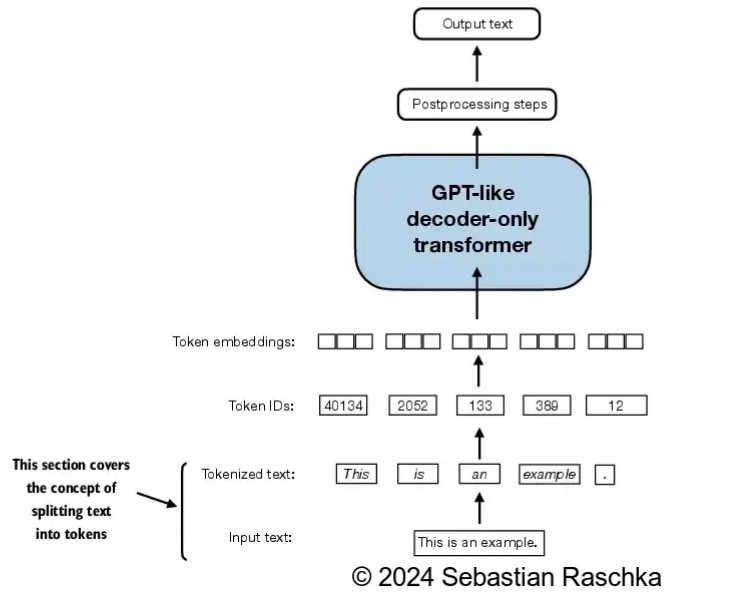
2.2 token转为tokenId
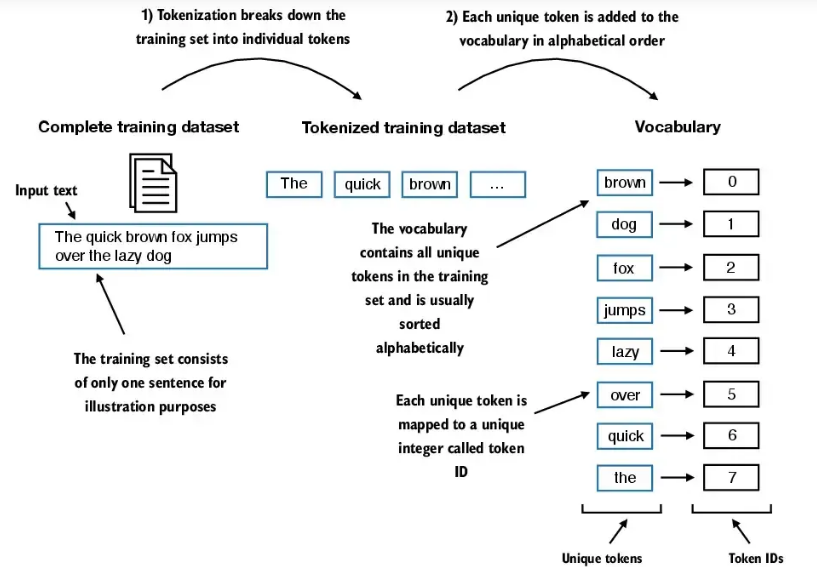
2.3 tokenId转为token
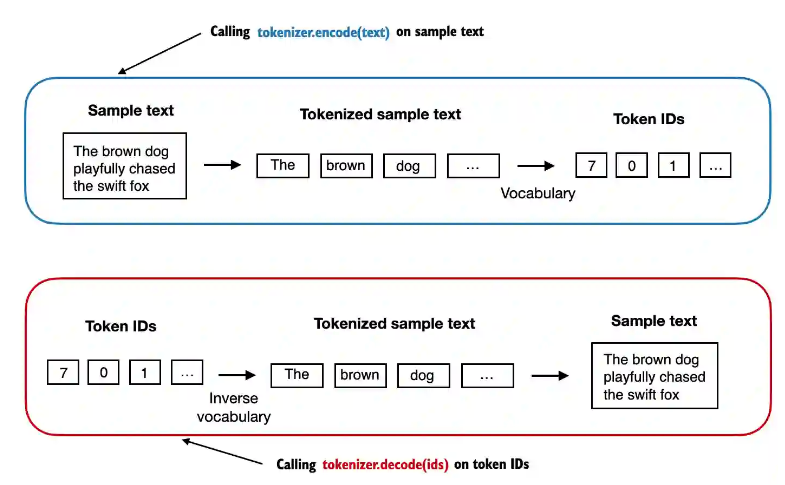
2.4 增加特殊的token代表所有未见过的词汇
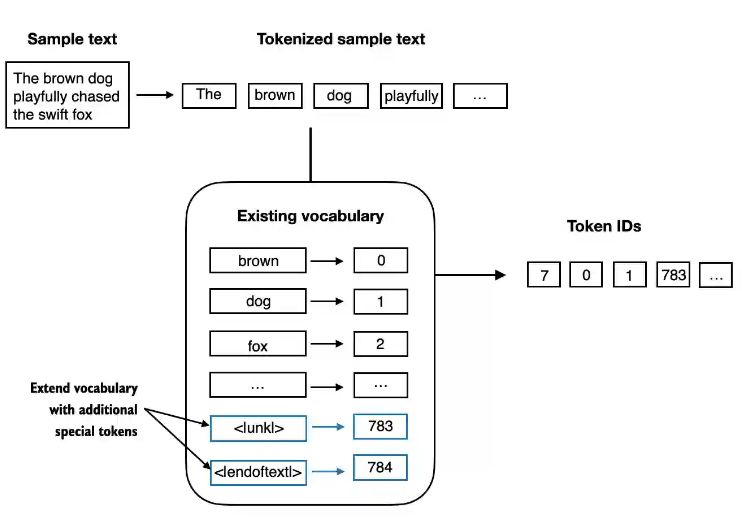
2.5 openai 采用 tiktoken作为 BPE
tiktoken 是 OpenAI 开发的一个快速 BPE(Byte Pair Encoding)分词器
BPE原理参考: https://mp.weixin.qq.com/s/YAtyHZ6IVECq39esigkfTg
tiktoken 是 OpenAI 开发的一个快速 BPE(Byte Pair Encoding)分词器,用于将文本转换为模型可以处理的 token(标记)序列。在处理大型语言模型(如 GPT 系列)时,准确计算 token 数量非常重要,因为:
计费基于 token 数:OpenAI API 的使用费用根据输入和输出的 token 数量计算。 上下文窗口限制:模型有最大 token 限制(如 GPT-4 为 8K/32K tokens),超过会导致错误。
性能优化:合理拆分文本可以提高处理效率。 核心功能
文本转 token:将文本转换为模型使用的 token 列表。
token 计数:精确计算文本的 token 数量,避免超出模型限制。
高效性能:用 Rust 实现,速度比纯 Python 库快得多
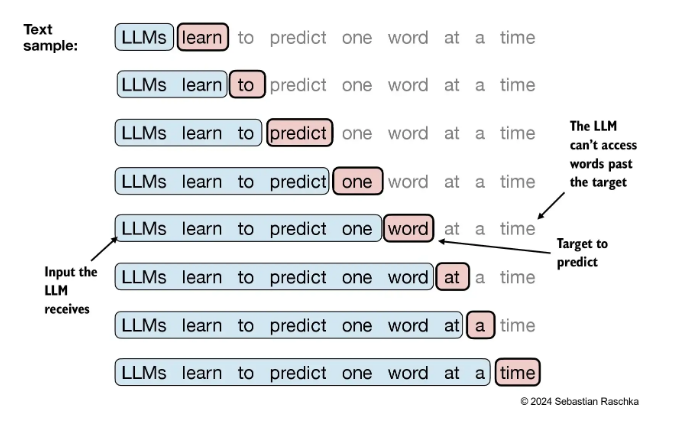
2.6 使用sliding window进行采样
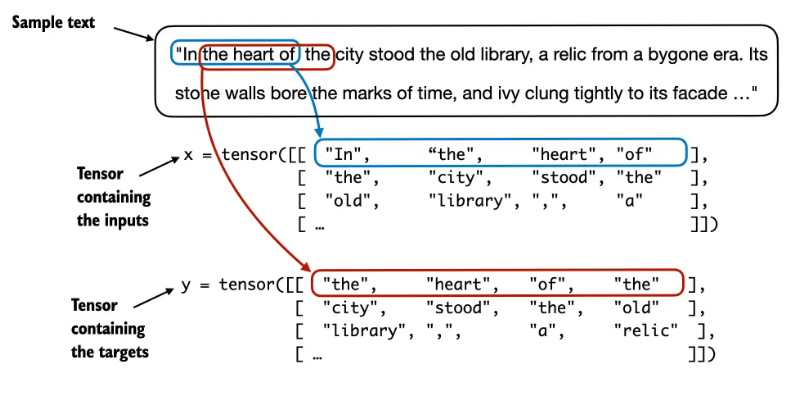
2.7 token转embedding
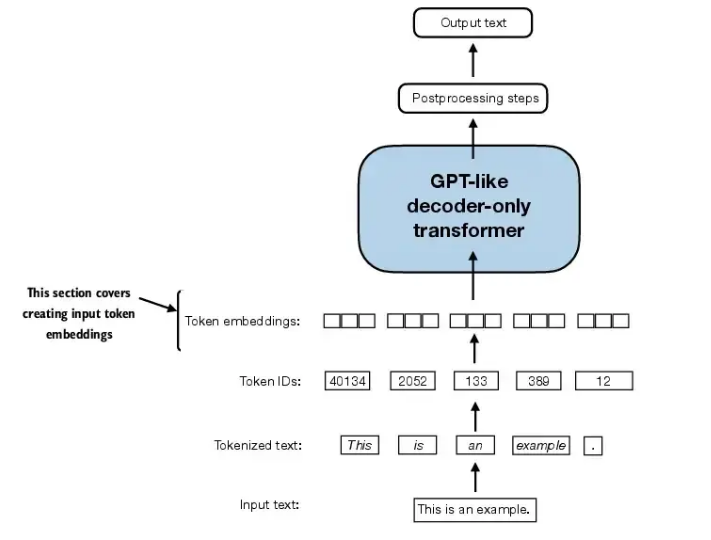
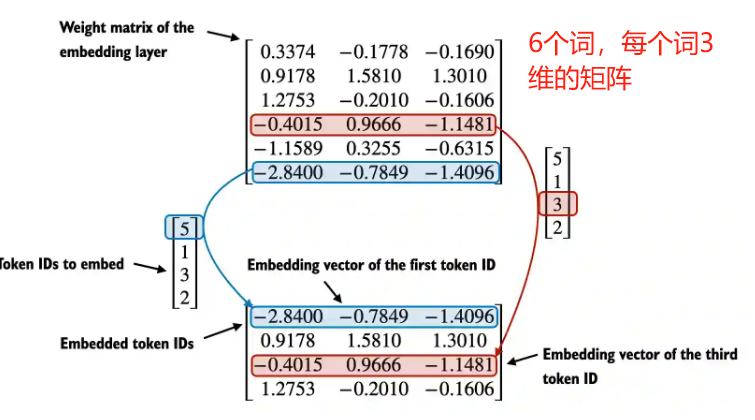
2.8 添加位置向量作为给transformer的输入
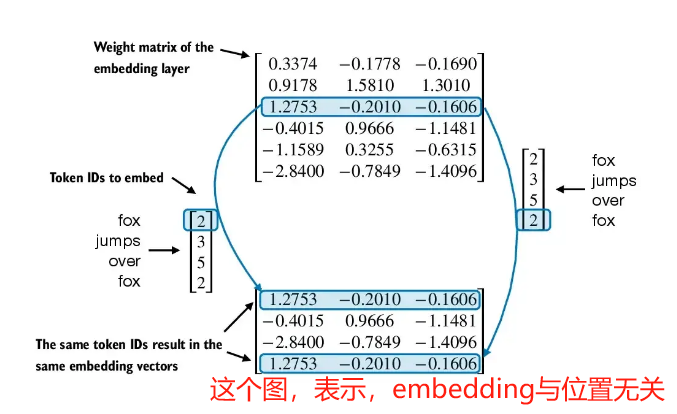
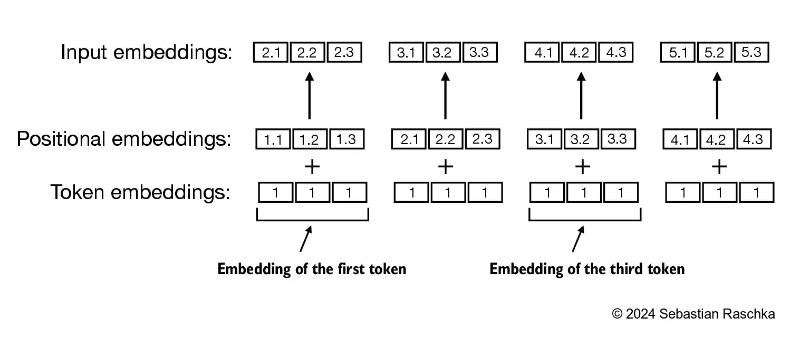
添加位置向量,目的是捕捉同一个词汇在不同位置的影响



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









