




【GPT入门】第55课 deepseek 8b的学生模型训练前后的变化内容
如果教师模型是DeepSeek R1,学生模型是基于Qwen3蒸馏得到的DeepSeek 8B,那么逻辑会调整为:
ollama介绍:
https://ollama.com/library/deepseek-r1:8b
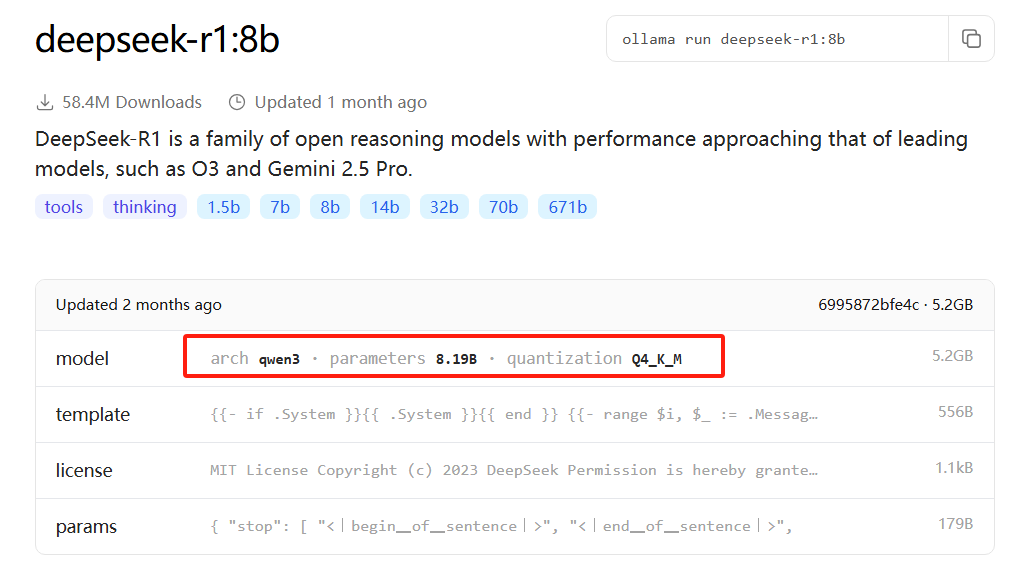
deepseek8b 是 qwen3学习得来
1. Qwen3作为学生模型的初始基础,训练前后参数是否变化?
会发生显著变化。
此时,Qwen3的角色是学生模型的“初始骨架”——蒸馏的核心是让Qwen3(作为待训练的学生)学习教师模型DeepSeek R1的知识和行为模式。因此,Qwen3的参数会在训练过程中被不断优化和调整,最终形成新的学生模型(DeepSeek 8B)。
简单说:Qwen3是“原材料”,经过蒸馏训练后,其参数被改写,成为了DeepSeek 8B的参数。
2. 训练后,变化的是什么?
-
学生模型(Qwen3→DeepSeek 8B)的参数:
Qwen3的初始参数会通过蒸馏目标(如模仿DeepSeek R1的输出分布、损失函数优化等)被持续更新,最终形成与原始Qwen3参数完全不同的DeepSeek 8B参数。这些参数保留了Qwen3的参数量级(或经过裁剪后固定为8B),但编码了教师模型DeepSeek R1的知识。 -
模型的行为与性能:
训练后,DeepSeek 8B的输出会更接近教师模型DeepSeek R1(例如推理逻辑、回答风格、任务准确率等),同时保持较小的参数量(8B),实现“小模型逼近大模型性能”的目标。 -
与教师模型的关联:
教师模型DeepSeek R1的参数通常不变(作为固定的“知识范本”),但其输出(如预测概率、中间特征等)会作为学生模型的学习目标,引导Qwen3的参数向更优方向调整。
总结
- 教师模型(DeepSeek R1):参数固定,提供学习目标和知识范本。
- 学生模型(基于Qwen3训练得到的DeepSeek 8B):Qwen3的初始参数被改写,最终形成新的参数体系,同时继承了教师模型的核心能力。
蒸馏的关键是学生参数的重塑,而非教师参数的修改,目标是让小模型通过学习教师的“经验”,在有限参数量下达到更优性能。



















 3396
3396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









