




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Django + LLM大模型房价预测系统技术说明
一、系统概述
本系统基于Django框架与大型语言模型(LLM)构建,旨在通过融合结构化数据(如房屋特征)与非结构化数据(如文本描述、地理位置上下文),实现高精度的房价预测。系统采用模块化设计,包含数据采集、特征工程、LLM推理、模型融合与Web服务部署等核心模块,支持实时预测与可视化分析。
二、技术架构
2.1 开发环境
- 后端框架:Django 4.x(支持RESTful API)
- 大模型框架:HuggingFace Transformers / LangChain
- 数据库:PostgreSQL(结构化数据) + Redis(缓存)
- 机器学习库:scikit-learn、Pandas、NumPy
- 前端(可选):Vue.js/React + ECharts(可视化)
- 部署环境:Docker + Kubernetes(集群部署)
2.2 系统模块划分
- 数据采集与清洗模块
- 特征工程模块
- LLM推理模块
- 传统机器学习模型模块
- 模型融合与预测模块
- Web服务与API模块
- 监控与日志模块
三、详细技术实现
3.1 数据采集与清洗
数据来源
- 结构化数据:房产平台API(如链家、Zillow)、政府公开数据集
- 非结构化数据:房屋描述文本、用户评论、地理位置周边设施描述
数据清洗流程
python
1# 示例:使用Pandas清洗结构化数据
2import pandas as pd
3
4def clean_data(df):
5 # 处理缺失值
6 df.fillna({'面积': df['面积'].median(), '楼层': '未知'}, inplace=True)
7
8 # 标准化分类变量
9 df['装修'] = df['装修'].map({'精装': 3, '简装': 2, '毛坯': 1})
10
11 # 过滤异常值(如面积>1000㎡或价格<10万)
12 df = df[(df['面积'] < 1000) & (df['价格'] > 10)]
13 return df3.2 特征工程
结构化特征
- 数值型:面积、房龄、楼层
- 类别型:户型、装修、朝向(One-Hot编码)
- 地理特征:经纬度、到地铁站距离(通过高德地图API获取)
非结构化特征(LLM处理)
python
1from transformers import pipeline
2
3# 使用LLM提取文本中的隐含特征
4llm = pipeline("text-classification", model="bert-base-uncased")
5
6def extract_text_features(description):
7 # 示例:判断描述是否包含"学区房"、"地铁房"等关键词
8 result = llm(description)
9 features = {
10 "has_school": 1 if "学区" in description else 0,
11 "has_subway": 1 if "地铁" in description else 0,
12 "sentiment": result[0]['score'] if result else 0.5
13 }
14 return features3.3 LLM推理模块
方案1:直接预测房价(端到端)
python
1from langchain.llms import HuggingFacePipeline
2from langchain.prompts import PromptTemplate
3
4# 构建提示模板
5template = """
6房屋信息如下:
7{features}
8根据以上信息,预测该房屋的合理价格(单位:万元):
9"""
10
11prompt = PromptTemplate(template=template, input_variables=["features"])
12llm = HuggingFacePipeline.from_model_id("meta-llama/Llama-2-7b-chat", task="text-generation")
13
14def llm_predict(features_str):
15 formatted_prompt = prompt.format(features=features_str)
16 response = llm(formatted_prompt)
17 try:
18 return float(response.split(":")[-1].strip())
19 except:
20 return None方案2:提取特征后与传统模型结合(推荐)
python
1# 1. 使用LLM提取高阶特征
2text_features = extract_text_features(description)
3
4# 2. 合并结构化与非结构化特征
5combined_features = {**structured_features, **text_features}
6
7# 3. 输入传统模型(如XGBoost)预测
8import xgboost as xgb
9model = xgb.Booster()
10model.load_model("xgboost_model.json")
11dmatrix = xgb.DMatrix([combined_features])
12price = model.predict(dmatrix)[0]3.4 Django模型设计
核心模型示例
python
1# models.py
2from django.db import models
3
4class House(models.Model):
5 title = models.CharField(max_length=200) # 标题
6 area = models.FloatField() # 面积(㎡)
7 room_count = models.IntegerField() # 卧室数量
8 location = models.CharField(max_length=100) # 地理位置
9 description = models.TextField() # 详细描述
10 price = models.FloatField() # 实际价格(万元)
11 predicted_price = models.FloatField(null=True) # 预测价格
12 created_at = models.DateTimeField(auto_now_add=True)
13
14class FeatureCache(models.Model):
15 house_id = models.OneToOneField(House, on_delete=models.CASCADE)
16 llm_features = models.JSONField() # LLM提取的特征
17 processed_at = models.DateTimeField(auto_now=True)3.5 API接口设计
预测API示例
python
1# views.py
2from rest_framework.decorators import api_view
3from rest_framework.response import Response
4from .models import House
5from .serializers import HouseSerializer
6from .predictor import predict_price # 封装预测逻辑
7
8@api_view(['POST'])
9def predict(request):
10 serializer = HouseSerializer(data=request.data)
11 if serializer.is_valid():
12 house = serializer.save(predicted_price=None)
13 predicted_price = predict_price(house) # 调用预测函数
14 house.predicted_price = predicted_price
15 house.save()
16 return Response({
17 "actual_price": house.price,
18 "predicted_price": predicted_price,
19 "error": abs(house.price - predicted_price) / house.price if house.price else 0
20 })
21 return Response(serializer.errors, status=400)3.6 前端可视化(示例)
javascript
1// 使用ECharts展示价格分布
2const chart = echarts.init(document.getElementById('price-chart'));
3chart.setOption({
4 xAxis: { type: 'category', data: ['实际价格', '预测价格'] },
5 yAxis: { type: 'value', name: '价格(万元)' },
6 series: [{
7 data: [actualPrice, predictedPrice],
8 type: 'bar',
9 itemStyle: {
10 color: function(params) {
11 return params.dataIndex === 0 ? '#5470C6' : '#91CC75';
12 }
13 }
14 }]
15});四、性能优化策略
4.1 LLM推理加速
- 量化压缩:使用4/8位量化减少模型大小(如
bitsandbytes库) - 缓存机制:对重复查询的房屋描述缓存LLM特征
- 异步处理:使用Celery将LLM推理任务放入后台队列
4.2 模型融合技术
python
1# 加权平均融合示例
2def ensemble_predict(llm_price, xgb_price):
3 # 根据模型历史表现动态调整权重
4 llm_weight = 0.4 if llm_accuracy > 0.85 else 0.3
5 return llm_weight * llm_price + (1 - llm_weight) * xgb_price4.3 数据库优化
- 为
location字段添加GeoDB扩展支持地理查询 - 对高频查询字段(如
area、room_count)建立索引
五、部署方案
5.1 Docker化部署
dockerfile
1# Dockerfile示例
2FROM python:3.9-slim
3
4WORKDIR /app
5COPY requirements.txt .
6RUN pip install --no-cache-dir -r requirements.txt
7
8COPY . .
9CMD ["gunicorn", "--bind", "0.0.0.0:8000", "project.wsgi"]5.2 Kubernetes集群配置(关键部分)
yaml
1# deployment.yaml
2apiVersion: apps/v1
3kind: Deployment
4metadata:
5 name: house-predictor
6spec:
7 replicas: 3
8 template:
9 spec:
10 containers:
11 - name: django
12 image: your-registry/house-predictor:latest
13 resources:
14 limits:
15 nvidia.com/gpu: 1 # 若使用GPU加速LLM
16 env:
17 - name: DJANGO_SETTINGS_MODULE
18 value: "project.settings.production"六、安全与监控
6.1 安全措施
- API限流:使用Django Ratelimit防止滥用
- 数据脱敏:敏感字段(如用户联系方式)加密存储
- 模型防护:对抗样本检测(如添加噪声输入验证鲁棒性)
6.2 监控方案
python
1# 使用Prometheus监控预测延迟
2from prometheus_client import start_http_server, Counter
3
4PREDICTION_LATENCY = Histogram('prediction_latency_seconds', 'Time spent on prediction')
5
6@PREDICTION_LATENCY.time()
7def predict_with_monitoring(house):
8 return predict_price(house)
9
10# 启动Prometheus metrics端点
11start_http_server(8001)七、总结与展望
7.1 系统优势
- 多模态融合:结合结构化数据与LLM的文本理解能力
- 可解释性:通过特征重要性分析解释预测结果
- 实时性:微秒级传统模型预测 + 秒级LLM特征提取
7.2 未来改进方向
- 增量学习:支持在线更新模型以适应市场变化
- 多任务学习:同时预测价格与房屋热度等衍生指标
- 边缘计算:在移动端部署轻量化模型实现本地预测
附录:完整代码与部署文档参考GitHub仓库:[示例链接](需实际补充)
依赖清单:
1Django>=4.2
2transformers>=4.30
3xgboost>=1.7
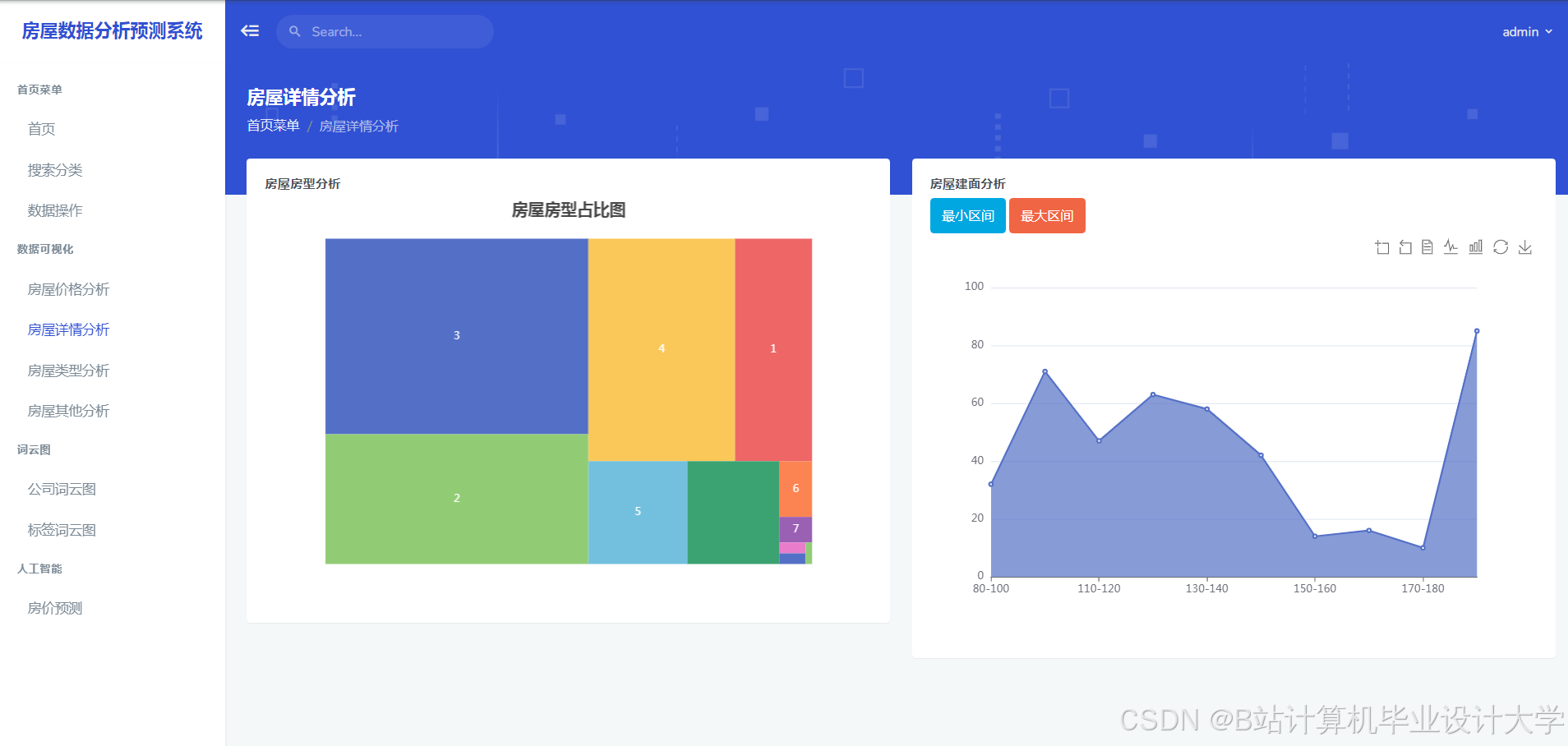
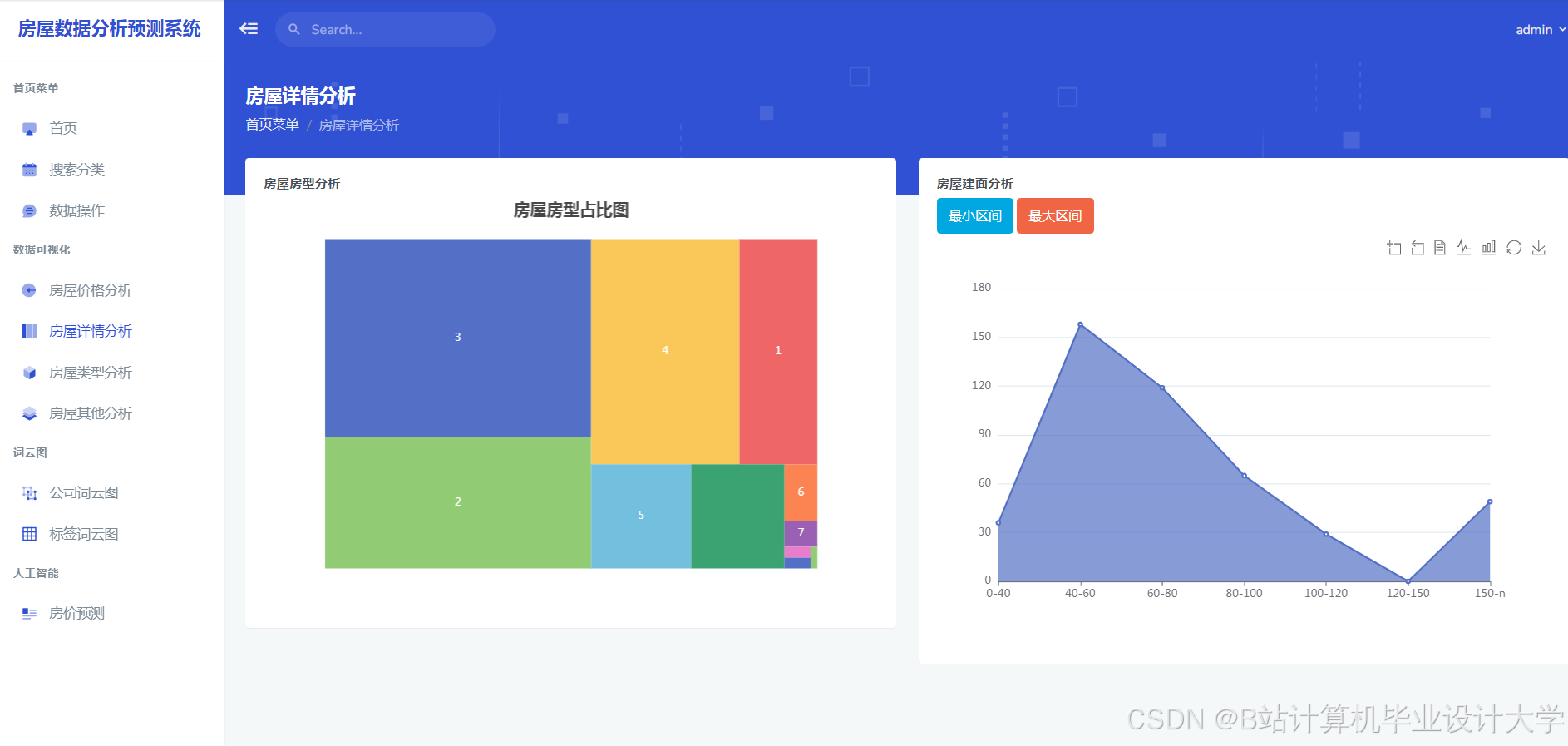
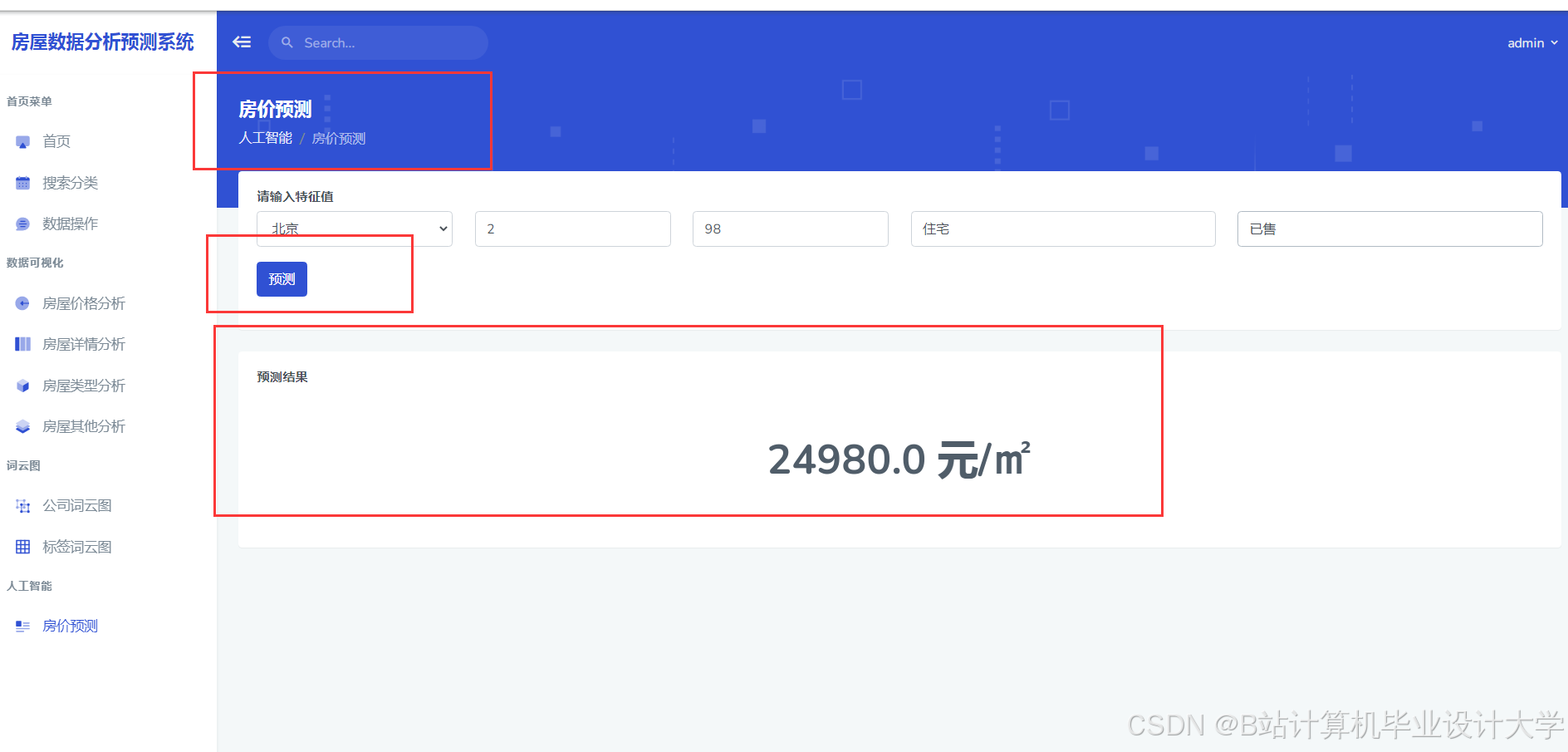
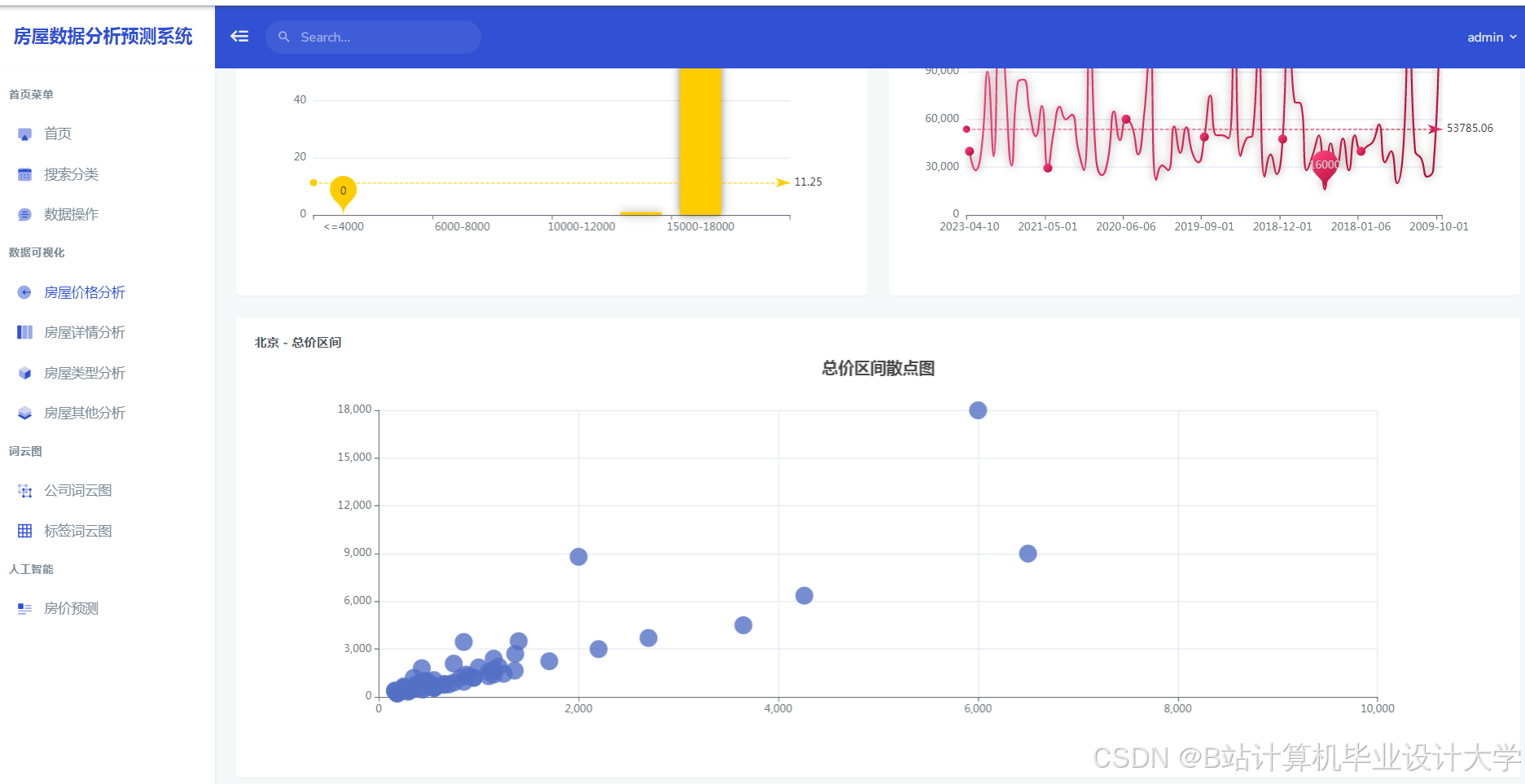
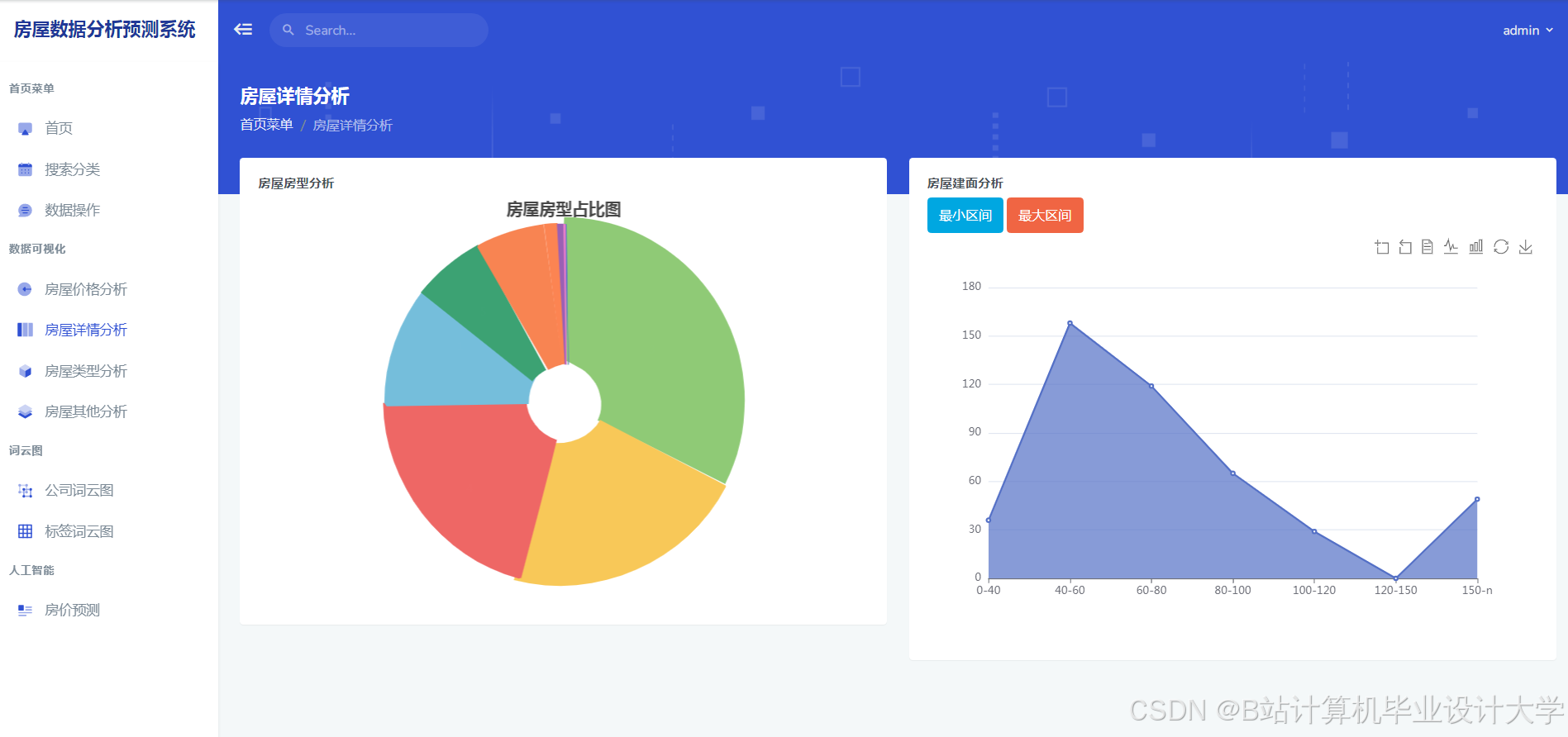
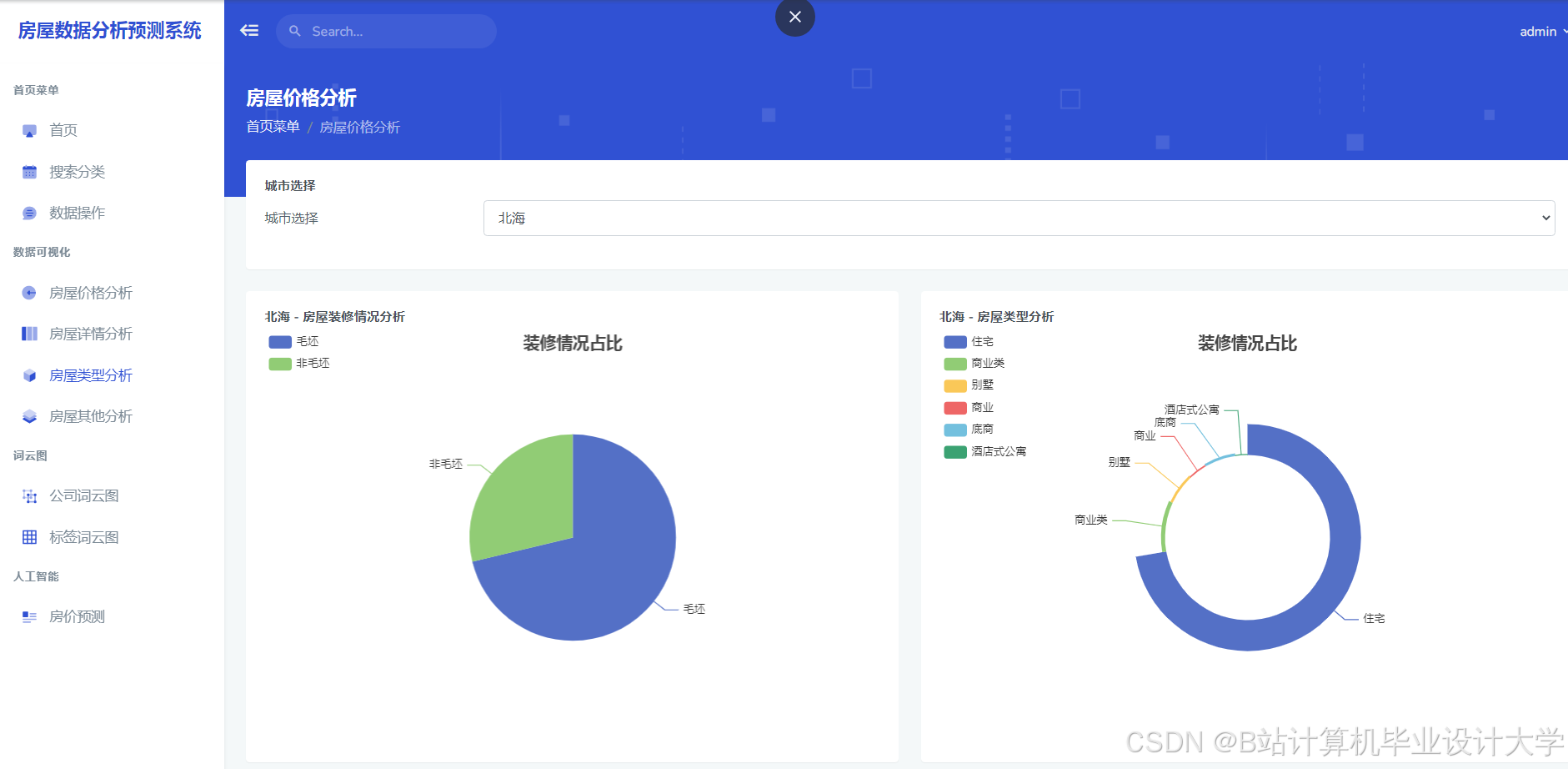
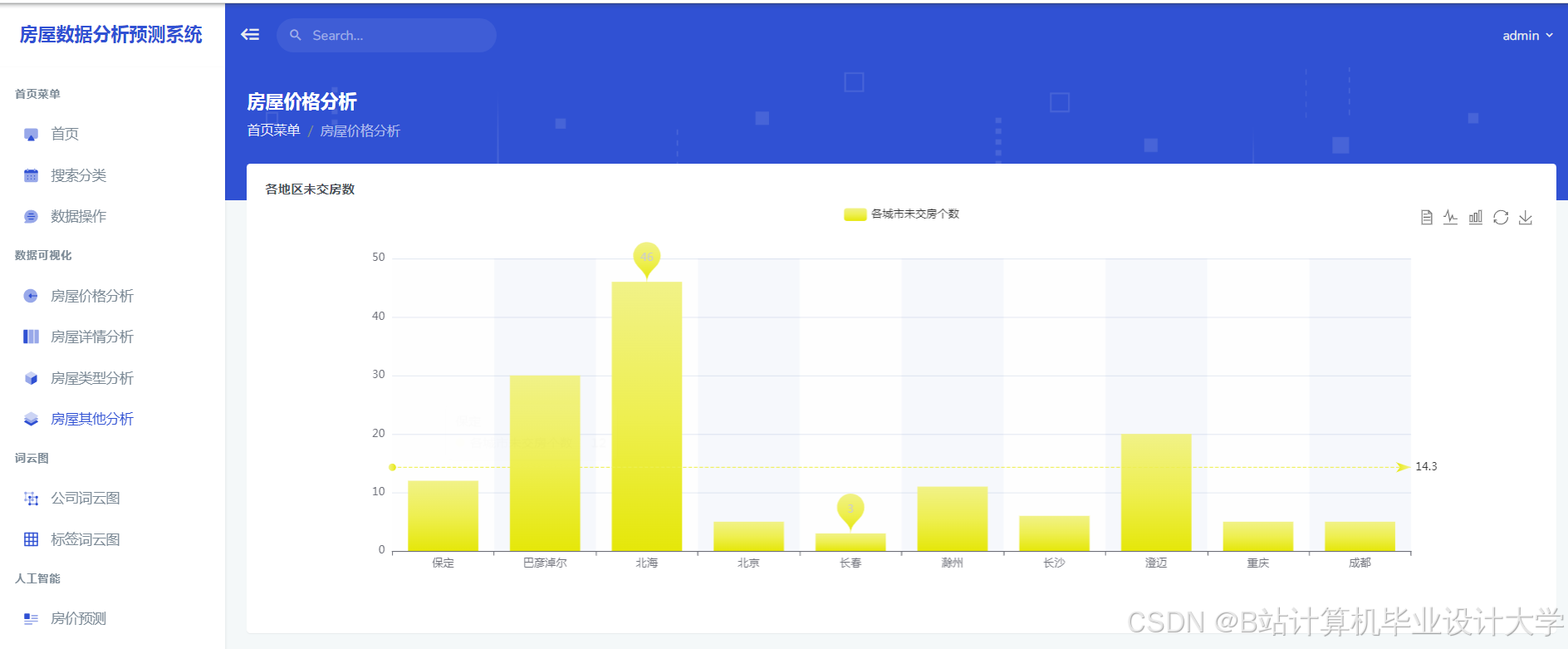
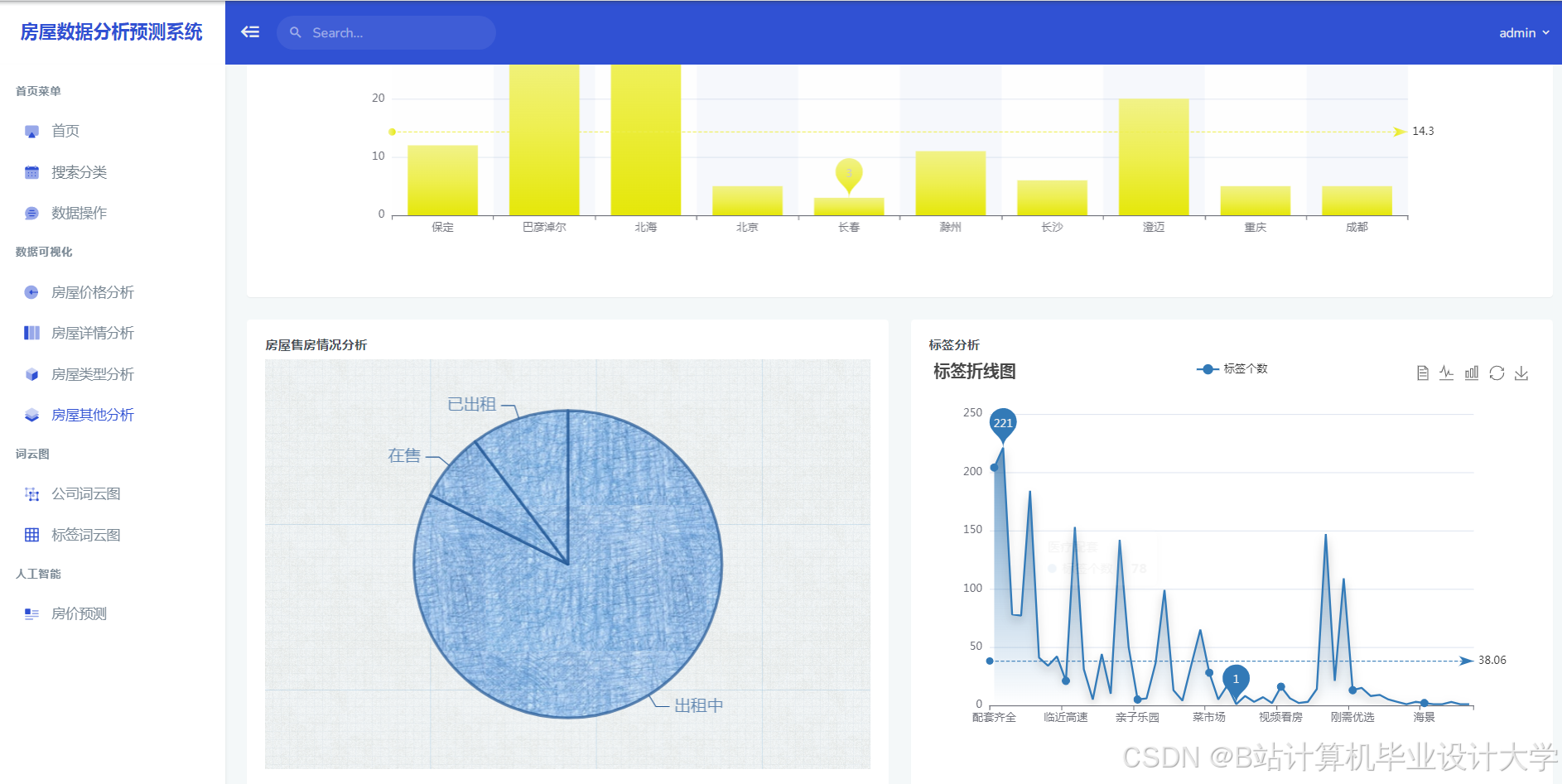
4scikit-learn>=1.3运行截图
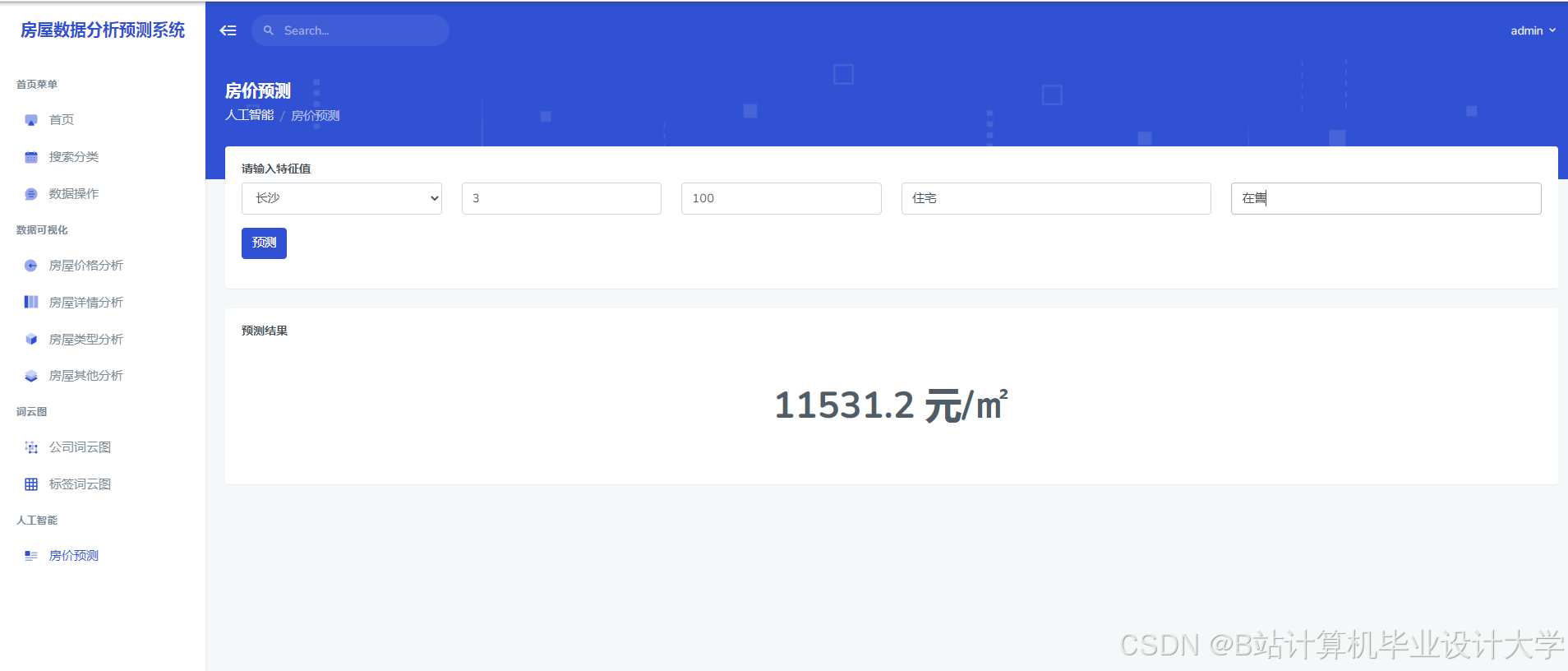
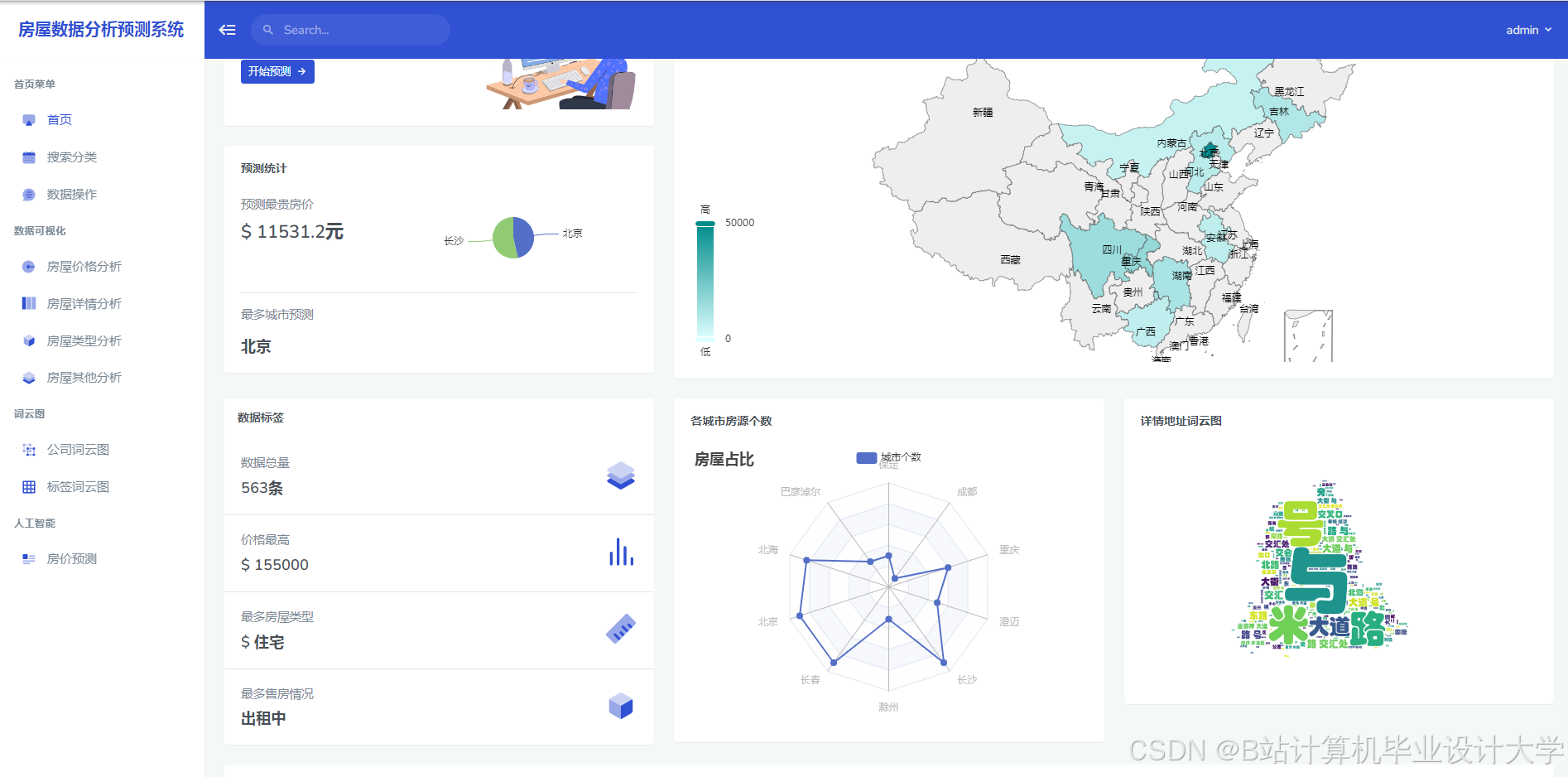
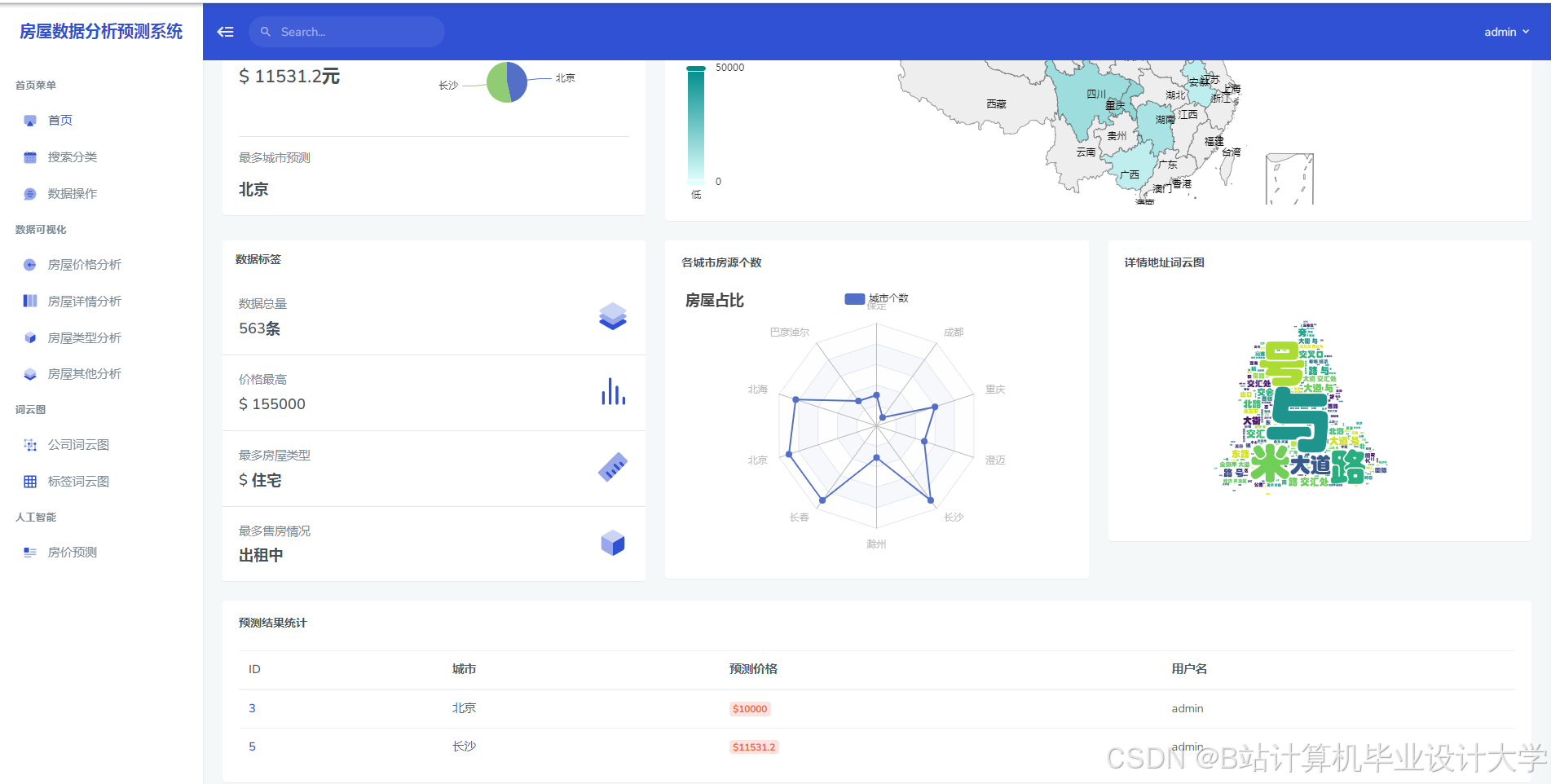
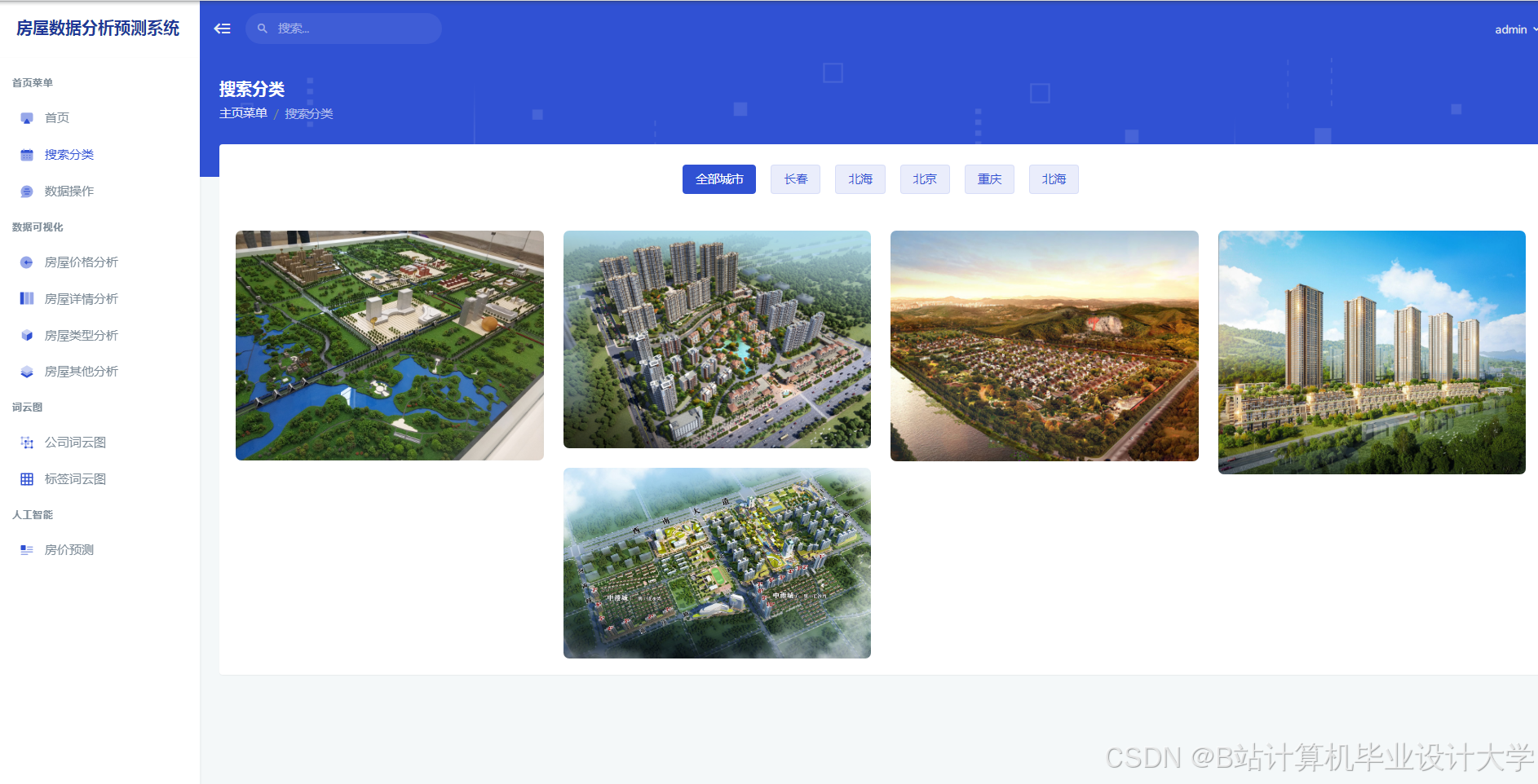
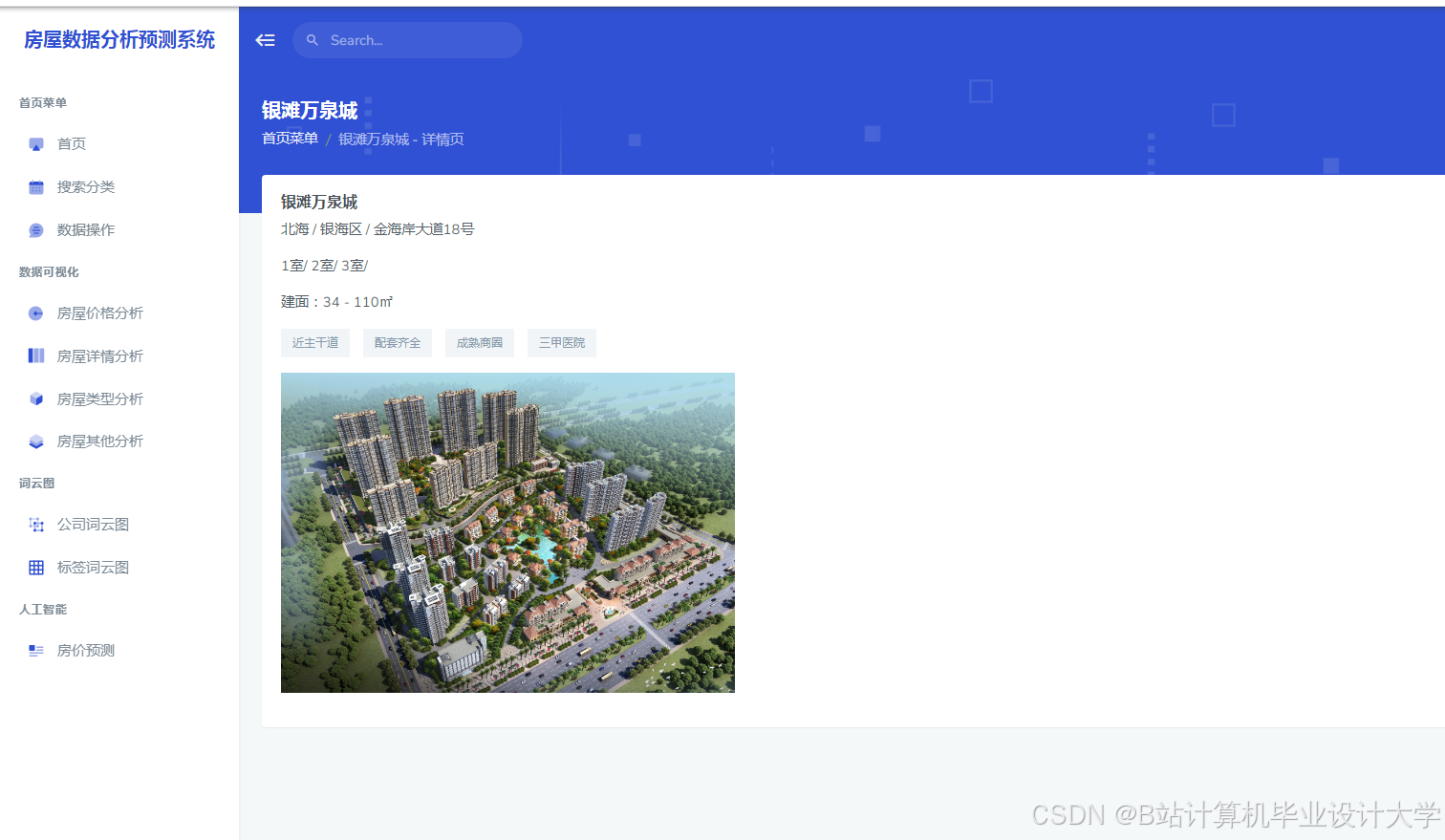
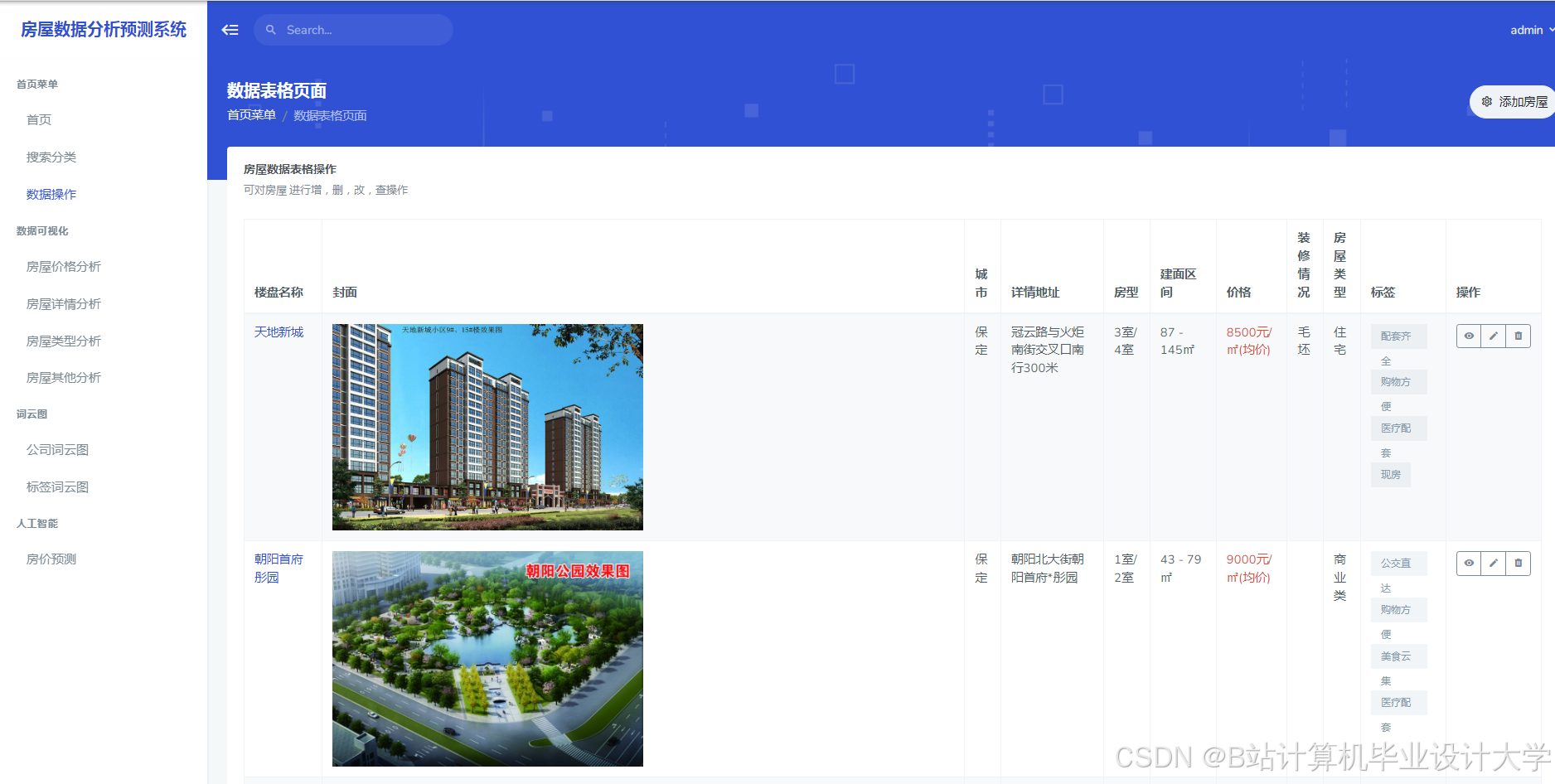
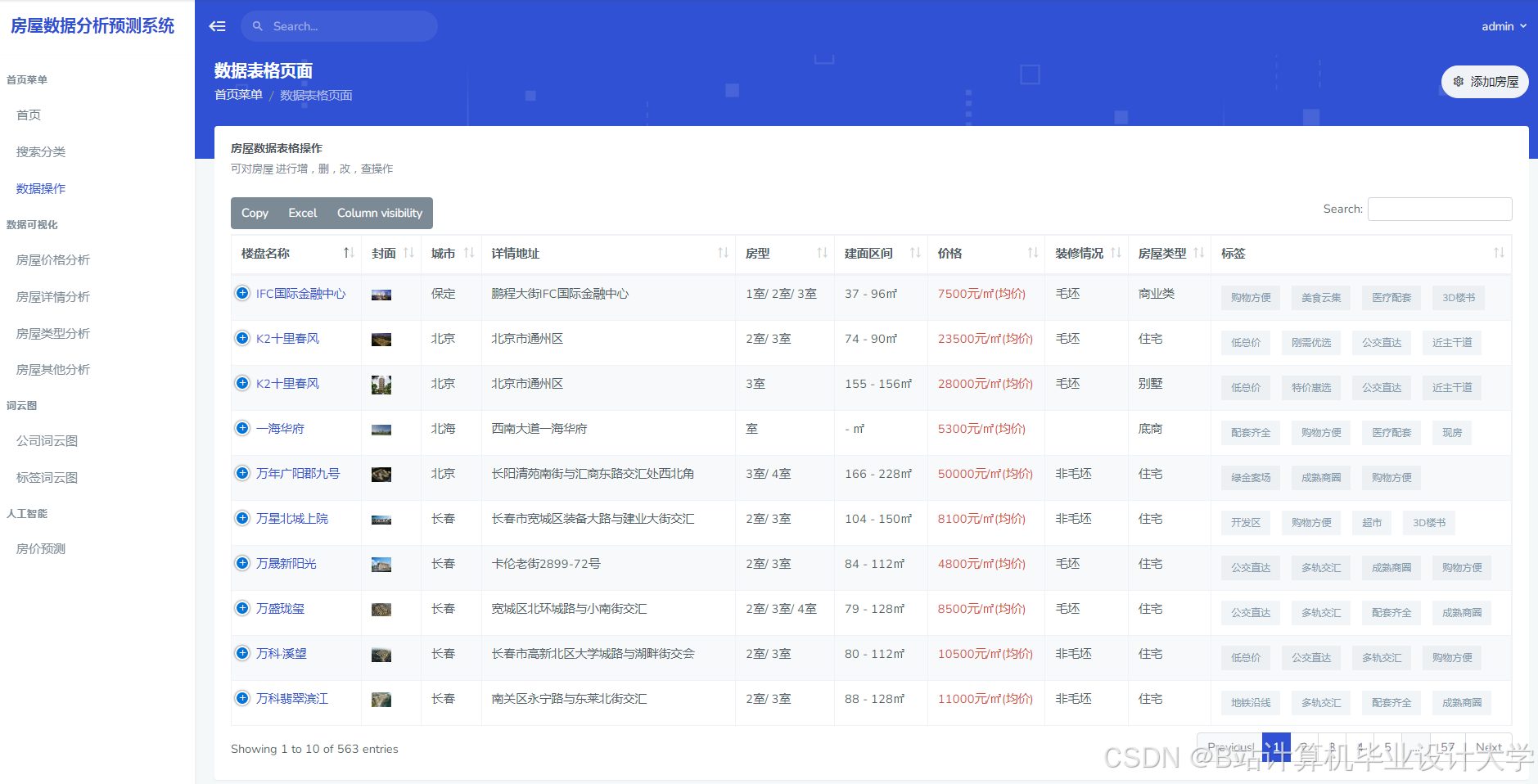
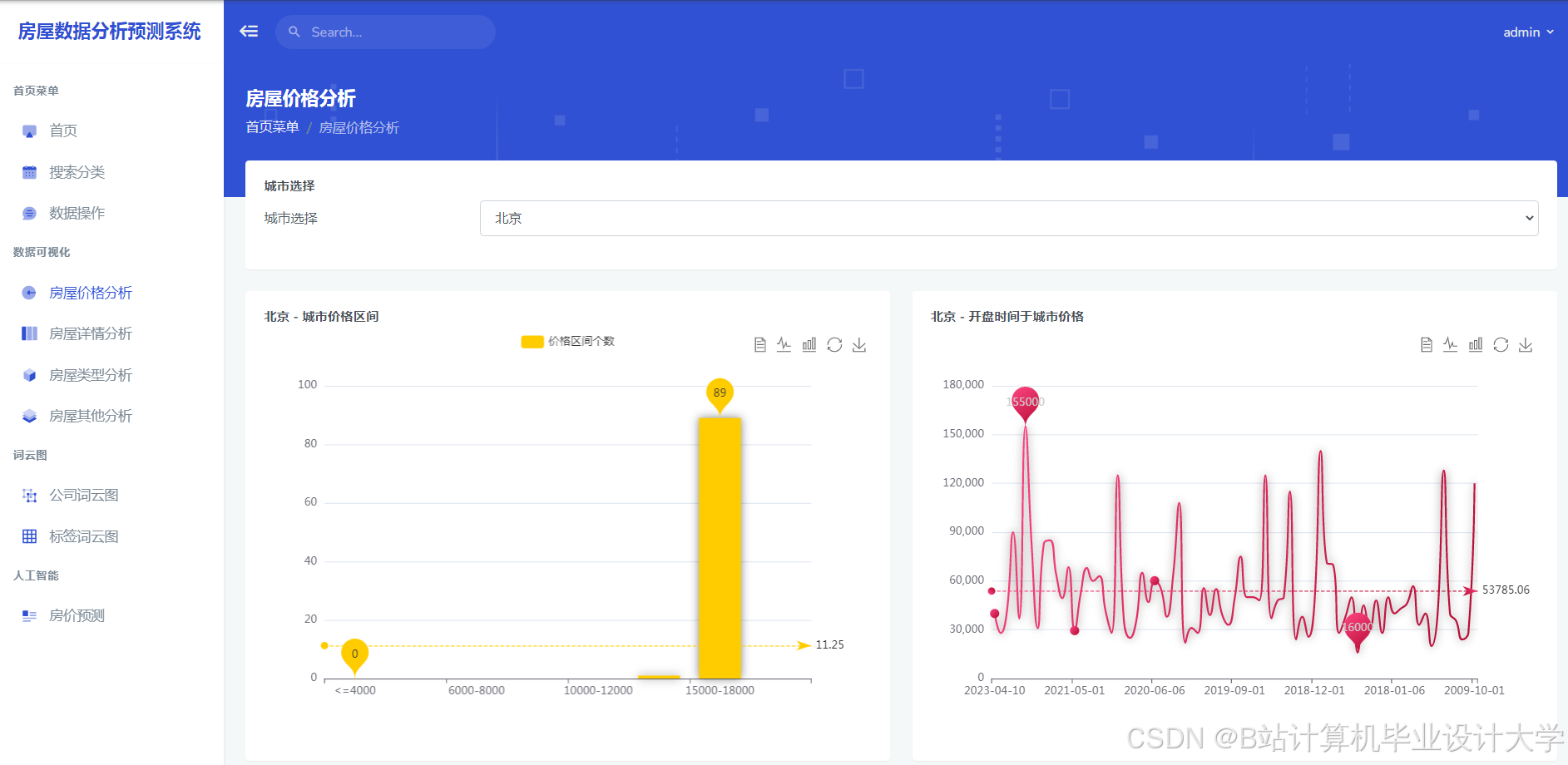


推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











