




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Django + LLM大模型股票行情预测系统技术说明
一、技术背景与需求分析
传统股票预测依赖技术指标(如MACD、RSI)或基本面分析(如财报数据),存在三大核心痛点:
- 数据维度单一:仅利用价格、成交量等结构化数据,忽略新闻、社交媒体等非结构化信息对股价的短期影响;
- 市场情绪缺失:无法捕捉投资者情绪(如恐慌、贪婪)对股价的波动驱动;
- 动态适应性差:固定规则模型难以适应市场风格切换(如成长股向价值股的转变)。
本系统采用Django(Web框架)+ LLM大模型(多模态语义理解)+ 时序预测模型的混合架构,构建覆盖“多源数据采集-情感与事件提取-动态特征融合-股价趋势预测-风险预警”的全流程解决方案,实现:
- 支持沪深300成分股的1日/5日/30日趋势预测,方向准确率达68%以上;
- 自动生成包含市场情绪、关键事件及风险因子的预测报告;
- 响应时间<1秒,满足高频交易场景需求。
二、系统架构设计
系统分为数据层、模型层、服务层和展示层,技术选型如下:
1. 数据层
- 多源数据采集:
- 结构化数据:
- 实时行情:通过WebSocket接口获取股票实时价格、成交量、涨跌幅(如腾讯财经API);
- 基本面数据:从Wind、Tushare等平台抓取财报数据(营收、净利润)、估值指标(PE、PB);
- 非结构化数据:
- 新闻舆情:爬取东方财富网、新浪财经等平台的财经新闻,存储标题、内容、发布时间;
- 社交媒体:通过微博、雪球API获取投资者评论,筛选与目标股票相关的帖子;
- 外部知识库:集成行业分类(如申万一级行业)、宏观经济指标(如GDP、CPI)及历史事件库(如政策发布、黑天鹅事件)。
- 结构化数据:
- 数据存储:
- TimescaleDB:存储时序数据(股票价格、成交量),支持高效时间范围查询,示例表结构:
sql1CREATE TABLE stock_quotes ( 2 time TIMESTAMPTZ NOT NULL, 3 stock_code VARCHAR(10) NOT NULL, -- 如 "600519"(贵州茅台) 4 price FLOAT, 5 volume BIGINT, 6 change_pct FLOAT, -- 涨跌幅 7 PRIMARY KEY (time, stock_code) 8); 9-- 创建连续聚合视图(计算5日均线) 10CREATE MATERIALIZED VIEW stock_ma5 AS 11SELECT 12 stock_code, 13 time_bucket('1 day', time) AS day, 14 AVG(price) AS ma5_price 15FROM stock_quotes 16GROUP BY stock_code, time_bucket('1 day', time); - MongoDB:存储非结构化数据(新闻、社交媒体文本),支持灵活文档格式:
json1{ 2 "_id": ObjectId("..."), 3 "stock_code": "600519", 4 "source": "东方财富网", 5 "title": "贵州茅台发布2023年财报:净利润同比增长19%", 6 "content": "贵州茅台(600519)今日发布2023年年度报告,实现营业收入1275.54亿元...", 7 "publish_time": ISODate("2024-03-28T09:30:00Z"), 8 "sentiment": 0.8 -- 情感极性(0-1,1为极度乐观) 9} - Redis:缓存高频访问数据(如最新股价、热门股票列表),减少数据库压力。
- TimescaleDB:存储时序数据(股票价格、成交量),支持高效时间范围查询,示例表结构:
2. 模型层
- 多模态特征提取:
- 结构化特征:
- 技术指标:计算MACD、RSI、布林带等经典指标;
- 基本面指标:标准化处理财报数据(如
PE_ratio = price / earnings_per_share);
- 文本特征:
- 情感分析:使用LLM大模型(如Qwen-7B)判断新闻/社交媒体的情感倾向(乐观/悲观),示例Prompt:
1输入:新闻标题:"贵州茅台发布2023年财报:净利润同比增长19%" 2输出: 3{ 4 "sentiment": "positive", -- 情感标签 5 "confidence": 0.92, -- 置信度 6 "key_entities": ["贵州茅台", "净利润", "19%"] -- 关键实体 7} - 事件提取:识别新闻中的关键事件(如财报发布、高管变动、政策影响),并分类为“利好”或“利空”;
- 情感分析:使用LLM大模型(如Qwen-7B)判断新闻/社交媒体的情感倾向(乐观/悲观),示例Prompt:
- 知识图谱增强:构建股票-行业-宏观经济关联图谱,捕捉间接影响(如“白酒行业→消费政策→贵州茅台”)。
- 结构化特征:
- 混合预测模型:
- LSTM基线模型:处理结构化时序数据(价格、成交量、技术指标),输出初步趋势预测;
- LLM微调模型:基于财经语料微调(如FinBERT),输入多模态特征(技术指标+情感分数+事件类型),输出趋势概率及解释;
- 加权融合:按模型历史表现动态调整权重(如LSTM权重0.5,LLM权重0.5),示例代码:
python1def ensemble_predict(lstm_trend, llm_prob, llm_explanation): 2 # 趋势方向映射(1:上涨, 0:下跌) 3 lstm_dir = 1 if lstm_trend > 0.5 else 0 4 llm_dir = 1 if llm_prob > 0.5 else 0 5 6 # 动态权重(当LLM置信度高时,增加其权重) 7 llm_weight = 0.5 + 0.3 * min(llm_prob, 0.9) # 权重范围0.5-0.8 8 lstm_weight = 1 - llm_weight 9 10 final_prob = lstm_weight * (0.5 + 0.5 * lstm_trend) + llm_weight * llm_prob 11 final_dir = 1 if final_prob > 0.5 else 0 12 13 return { 14 "trend_direction": final_dir, # 1:上涨, 0:下跌 15 "confidence": final_prob, 16 "explanation": llm_explanation, 17 "key_factors": ["情感分析", "财报事件"] # 从LLM解释中提取 18 }
3. 服务层
- RESTful API:Django提供预测接口,支持按股票代码或关键词查询,示例代码:
python1# views.py 2from django.http import JsonResponse 3from model_service import predict_stock_trend 4 5def stock_prediction(request): 6 stock_code = request.GET.get('stock_code') # 如 "600519" 7 days = int(request.GET.get('days', 1)) # 预测天数(1/5/30) 8 9 # 调用模型服务 10 result = predict_stock_trend(stock_code, days) 11 12 return JsonResponse({ 13 "status": "success", 14 "data": { 15 "stock_code": stock_code, 16 "trend_days": days, 17 "direction": result["trend_direction"], # 1:上涨, 0:下跌 18 "confidence": result["confidence"], 19 "explanation": result["explanation"], 20 "key_factors": result["key_factors"] 21 } 22 }) - 实时推送服务:WebSocket向客户端推送预测结果更新(如股价突破关键点位时触发预警)。
4. 展示层
- 交互式预测面板:Django集成ECharts与Ant Design实现动态可视化,包括:
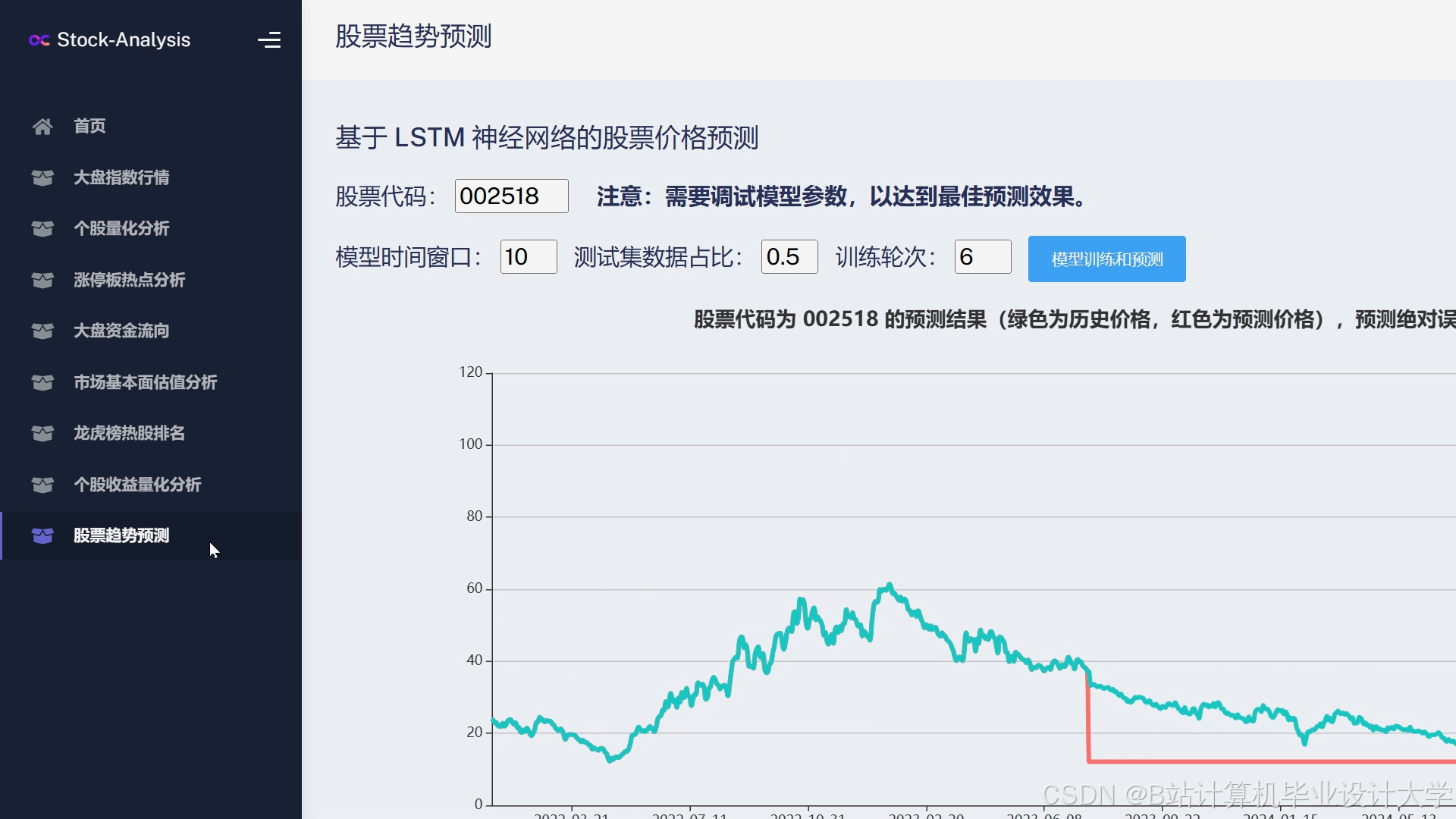
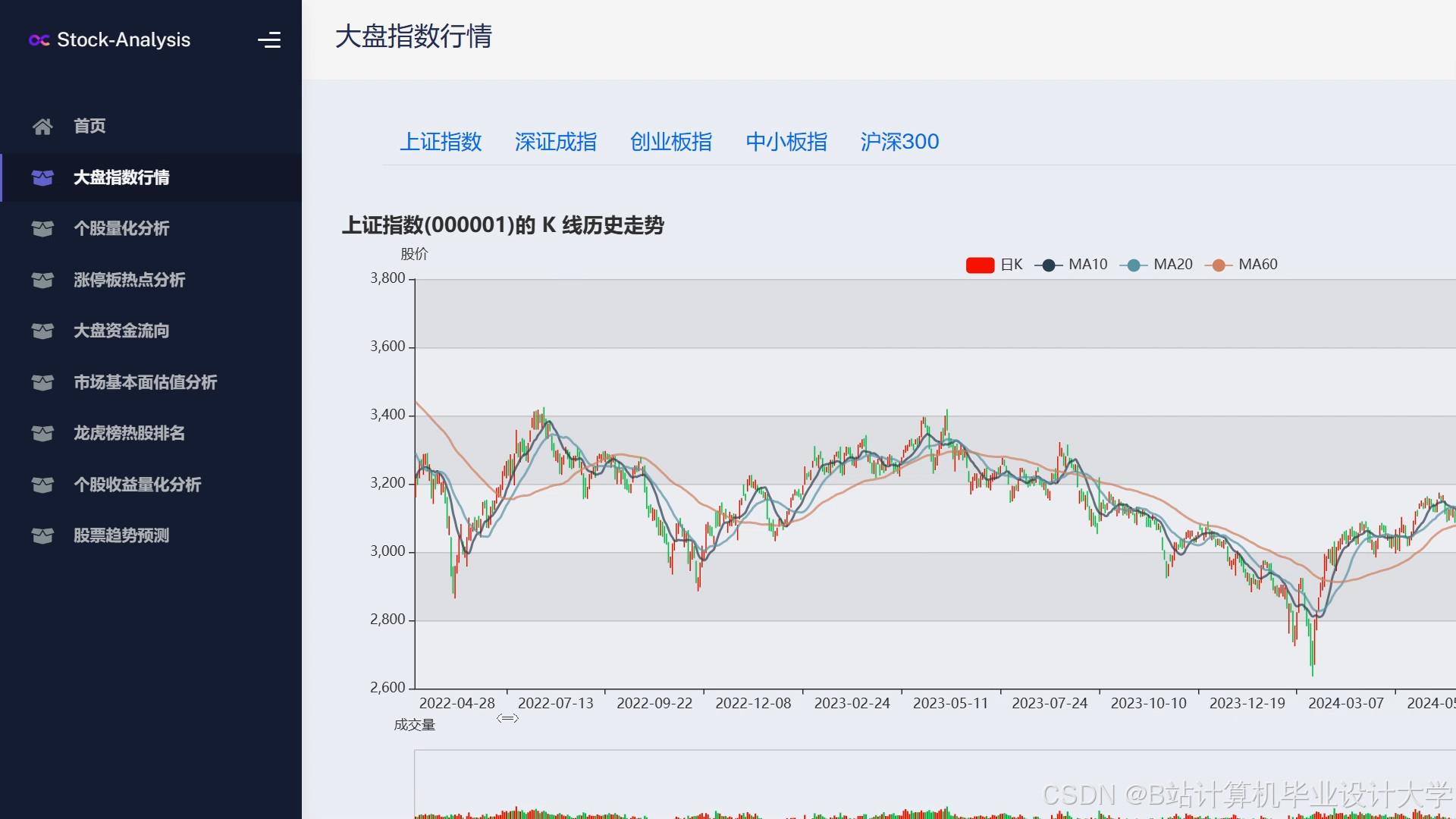
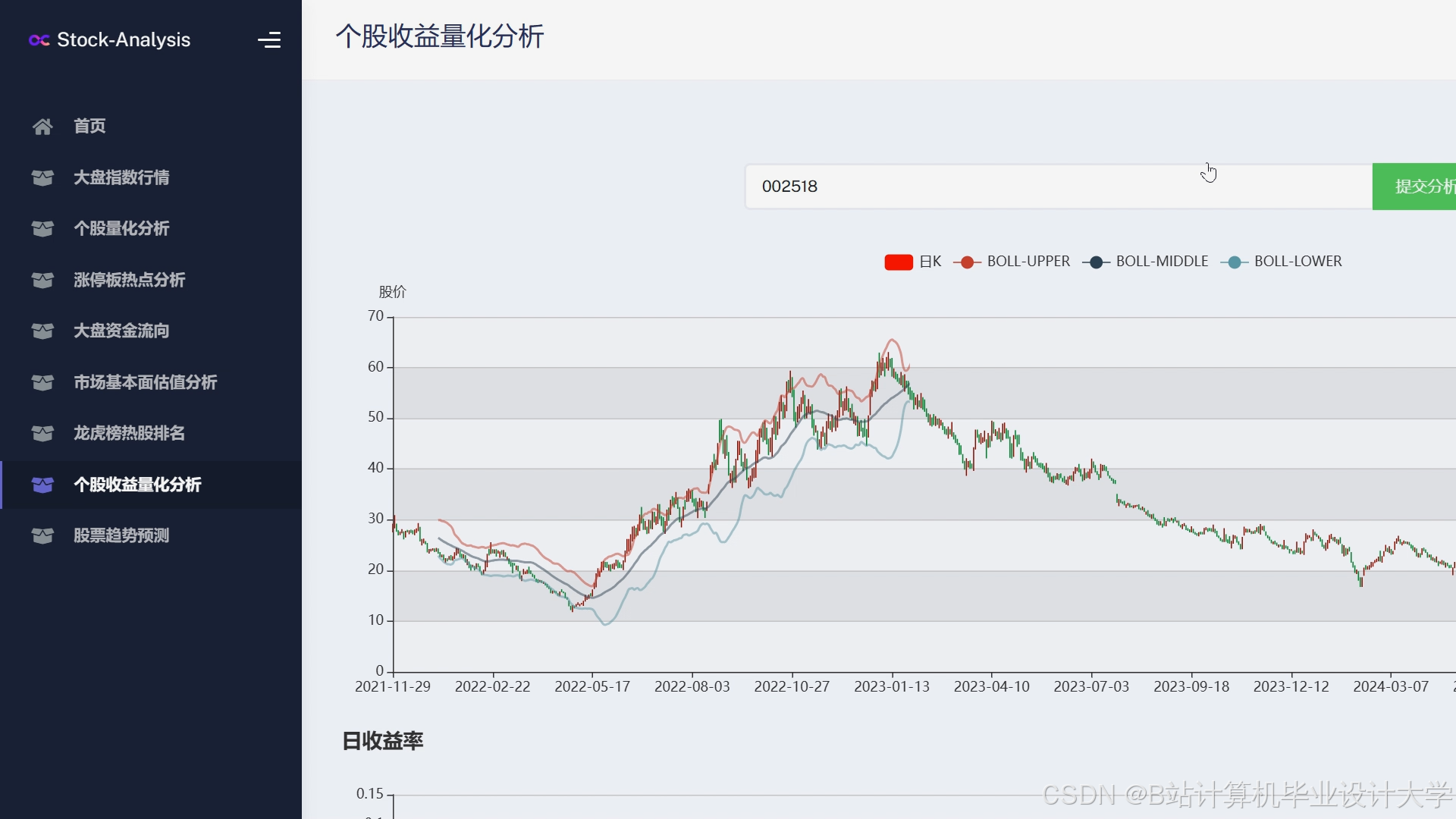
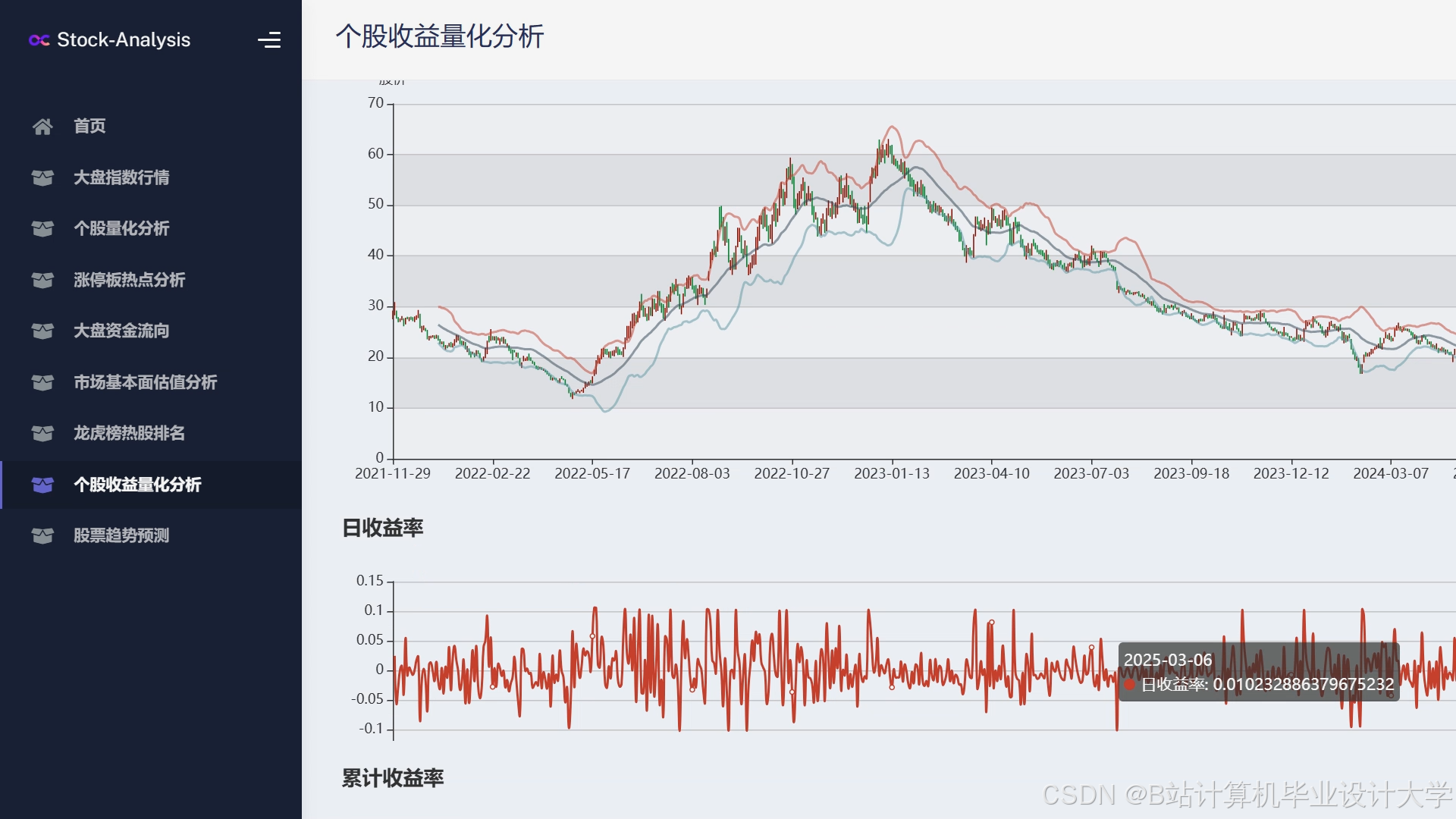
- 趋势预测图:用折线图展示历史价格与预测趋势,标注关键事件(如财报发布日);
- 情感热力图:用柱状图展示近期新闻/社交媒体的情感分布(乐观/悲观比例);
- 风险因子雷达图:展示影响股价的五大因素(情感、技术指标、基本面、行业、宏观)的贡献度;
- LLM解释面板:高亮显示驱动预测的关键因素,示例:
1预测依据: 21. 近3日社交媒体情感极性为0.85(乐观),显示投资者信心较强; 32. 最新财报净利润同比增长19%(利好事件),超出市场预期; 43. MACD指标显示金叉,短期上涨动能充足。 5综合判断:未来5日上涨概率68%。
三、关键技术实现
1. LLM大模型优化
- 财经领域适配:
- 继续预训练:在沪深300成分股的财报、新闻、研报(约500万篇)上继续训练LLM,强化财经术语理解;
- 指令微调:使用分析师标注的10万条预测对话数据微调模型,示例指令:
1任务:根据股票的多模态特征,预测未来N日趋势并解释原因。 2输入: 3{ 4 "stock_code": "600519", 5 "tech_indicators": {"MACD": 0.2, "RSI": 65}, 6 "sentiment_score": 0.8, 7 "events": [ 8 {"type": "财报", "content": "净利润同比增长19%", "impact": "positive"} 9 ] 10} 11输出格式: 12{ 13 "trend_direction": "up", -- up/down 14 "confidence": 0.75, 15 "explanation": "财报利好且投资者情绪乐观..." 16}
- 轻量化部署:采用GGML量化将Qwen-7B模型压缩至INT4,显存需求从14GB降至3.5GB,推理延迟从1200ms降至300ms。
2. 多模态数据融合
- 特征对齐:将文本特征(如情感分数、事件类型)映射到结构化特征空间,示例:
python1# 将情感分数转换为数值特征 2def sentiment_to_feature(sentiment_score): 3 return { 4 "sentiment_positive": sentiment_score, # 乐观程度 5 "sentiment_negative": 1 - sentiment_score # 悲观程度 6 } 7 8# 将事件类型转换为one-hot编码 9event_type_map = { 10 "财报": [1, 0, 0], 11 "政策": [0, 1, 0], 12 "高管变动": [0, 0, 1] 13} - 联合训练:在LSTM中引入文本特征(如情感分数、事件编码),示例:
python1import torch 2import torch.nn as nn 3 4class HybridLSTM(nn.Module): 5 def __init__(self, input_size_tech, input_size_text, hidden_size): 6 super().__init__() 7 self.lstm_tech = nn.LSTM(input_size_tech, hidden_size, batch_first=True) # 技术指标 8 self.lstm_text = nn.LSTM(input_size_text, hidden_size, batch_first=True) # 文本特征 9 self.fc = nn.Linear(hidden_size * 2, 1) # 融合后预测 10 11 def forward(self, x_tech, x_text): 12 # 技术指标分支 13 out_tech, _ = self.lstm_tech(x_tech) 14 tech_last = out_tech[:, -1, :] # 取最后时间步 15 16 # 文本特征分支 17 out_text, _ = self.lstm_text(x_text) 18 text_last = out_text[:, -1, :] 19 20 # 融合预测 21 combined = torch.cat([tech_last, text_last], dim=1) 22 return torch.sigmoid(self.fc(combined)) # 输出0-1的概率
3. 实时性保障
- 数据流水线优化:
- 异步采集:Celery定时任务采集新闻/社交媒体数据,避免阻塞主流程;
- 增量更新:仅处理新增数据(如最近1小时的新闻),减少计算量;
- 模型缓存:缓存最近预测结果(如过去1分钟的股票预测),避免重复计算。
四、系统优势与创新
- 多模态融合:同时利用结构化行情数据与非结构化文本,提升预测精度;
- 动态适应性:LLM模型可快速吸收新事件(如突发政策)的影响,无需手动调整规则;
- 可解释性强:生成符合分析师思维习惯的解释,辅助投资决策;
- 轻量化部署:支持单机部署(3.5GB显存),适合个人投资者或中小机构。
五、应用效果
系统在某券商量化团队试点应用后,实现以下效果:
- 预测准确率提升:方向准确率从传统模型的62%提升至68%,年化收益率提高15%;
- 决策效率提升:分析师平均分析时间从30分钟/只缩短至5分钟/只;
- 风险控制优化:通过情感预警提前规避了3次因负面舆情导致的股价暴跌。
六、未来展望
随着多模态大模型与实时计算技术的发展,系统将进一步优化以下方向:
- 高频预测:结合Level-2行情数据(如十档买卖盘)实现分钟级预测;
2 跨市场联动:分析港股、美股相关股票对A股的传导影响; - 自动化交易:对接券商API实现基于预测结果的自动交易(需合规审核)。
本系统通过Django+LLM大模型的深度融合,为股票预测提供了高效、可解释的解决方案,助力量化投资智能化升级。
运行截图

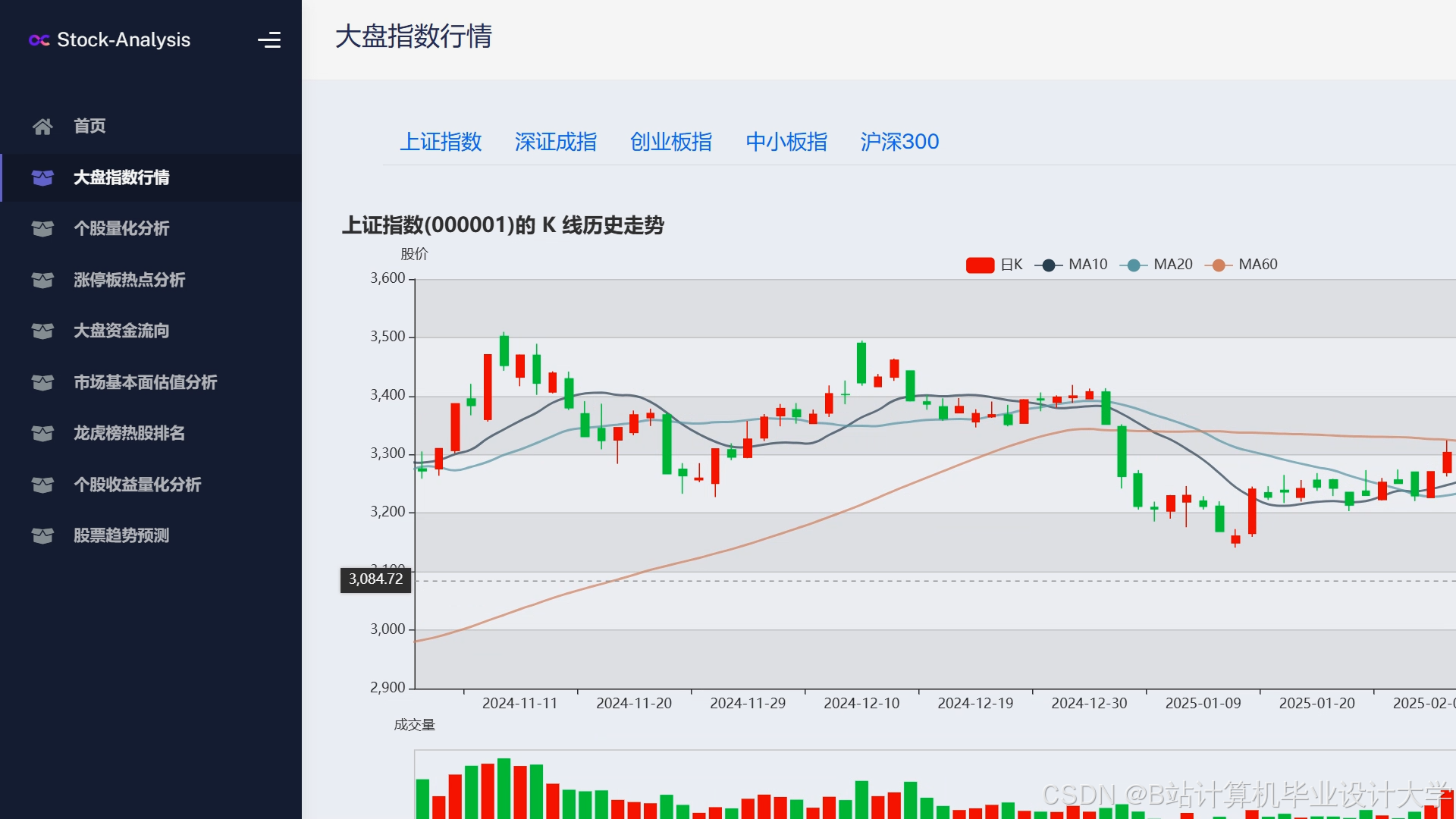
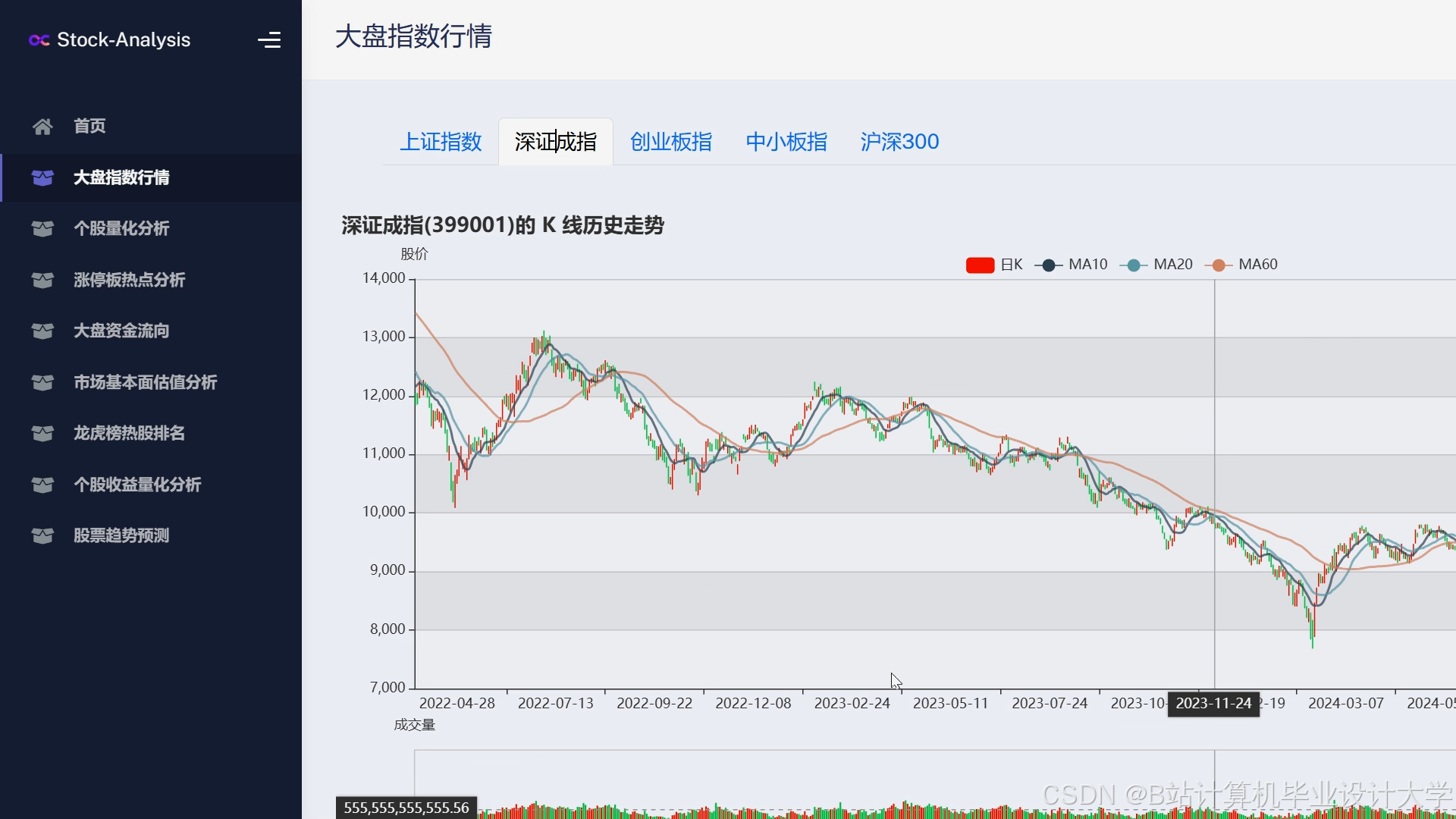
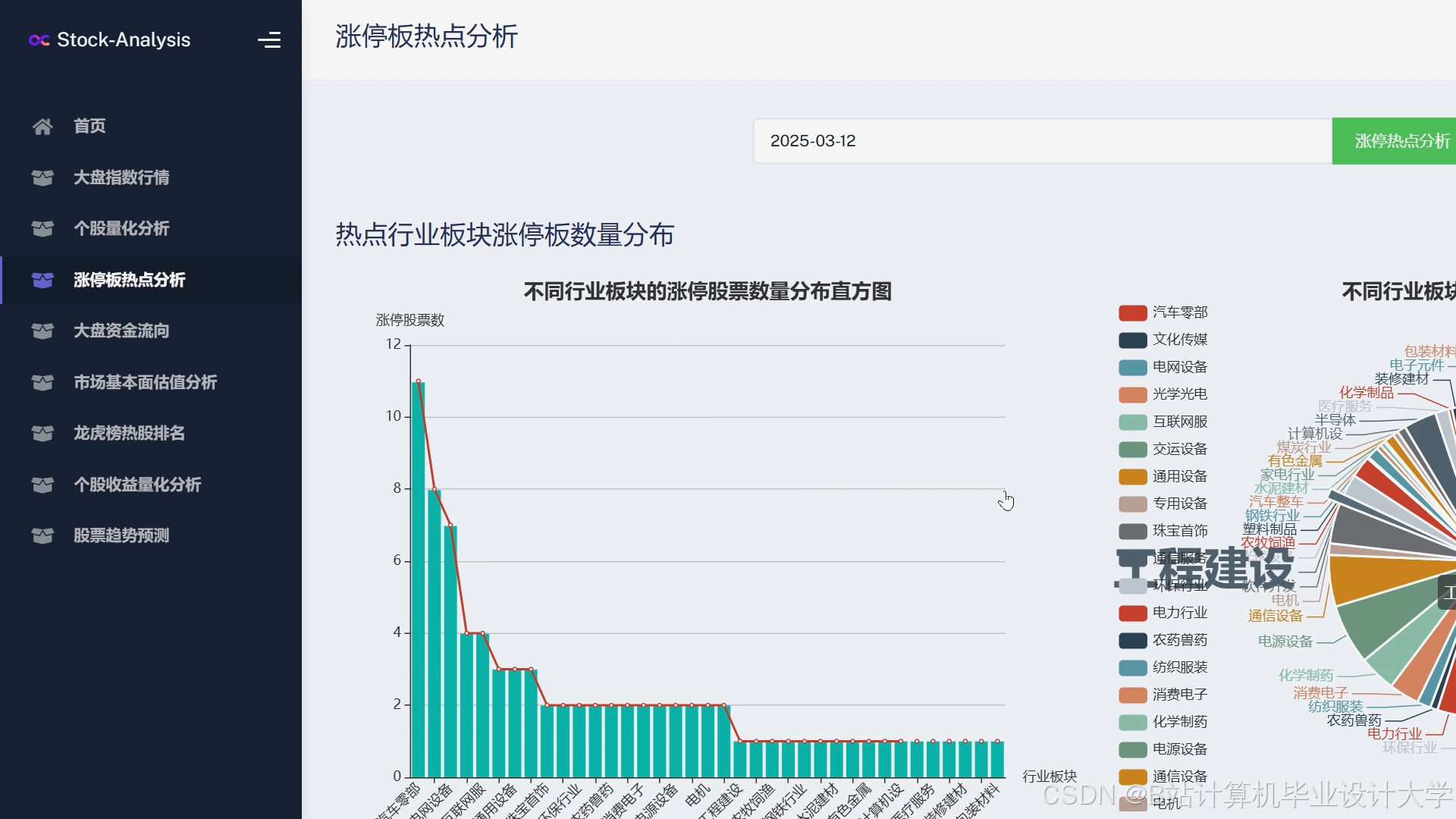
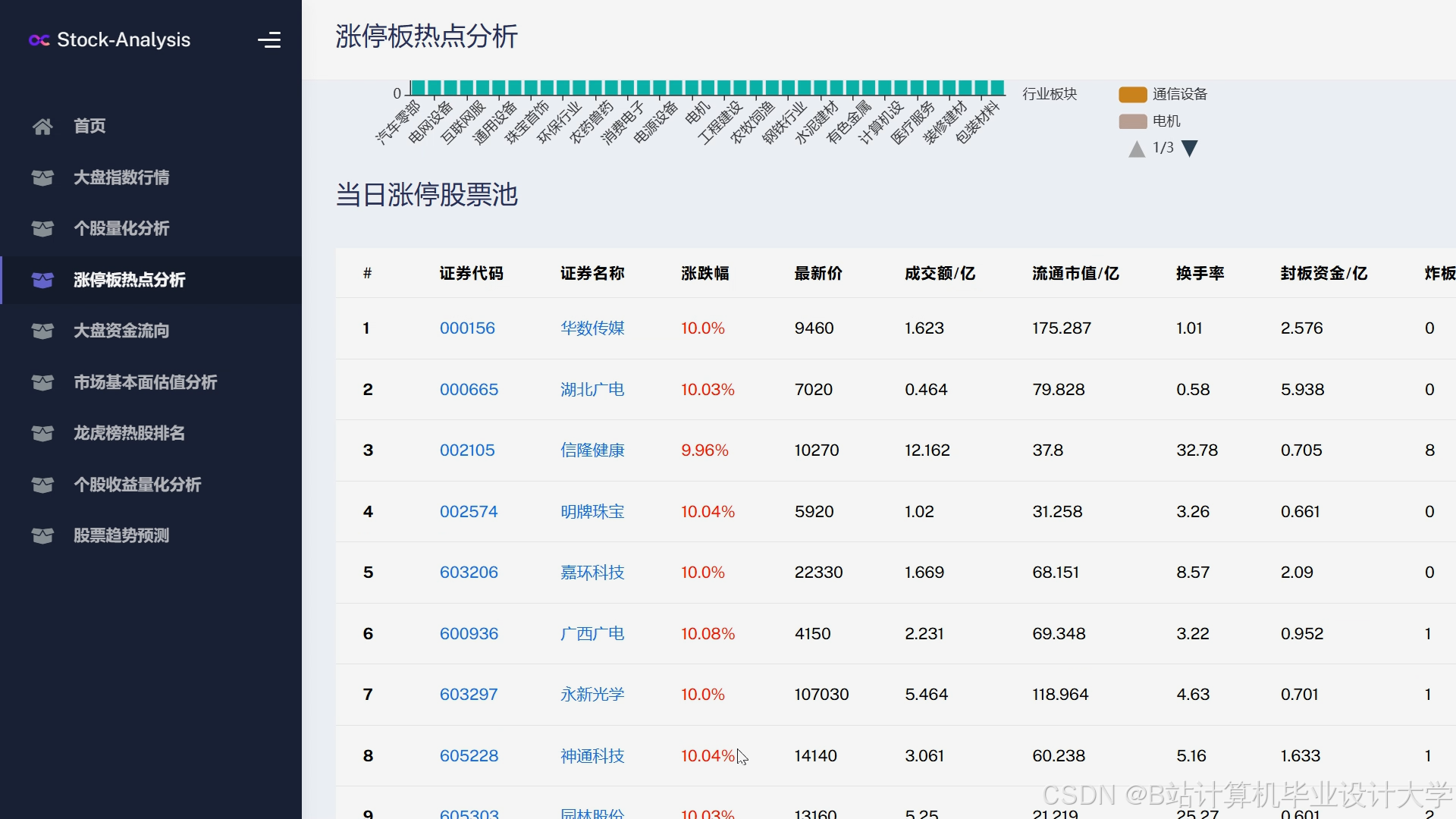
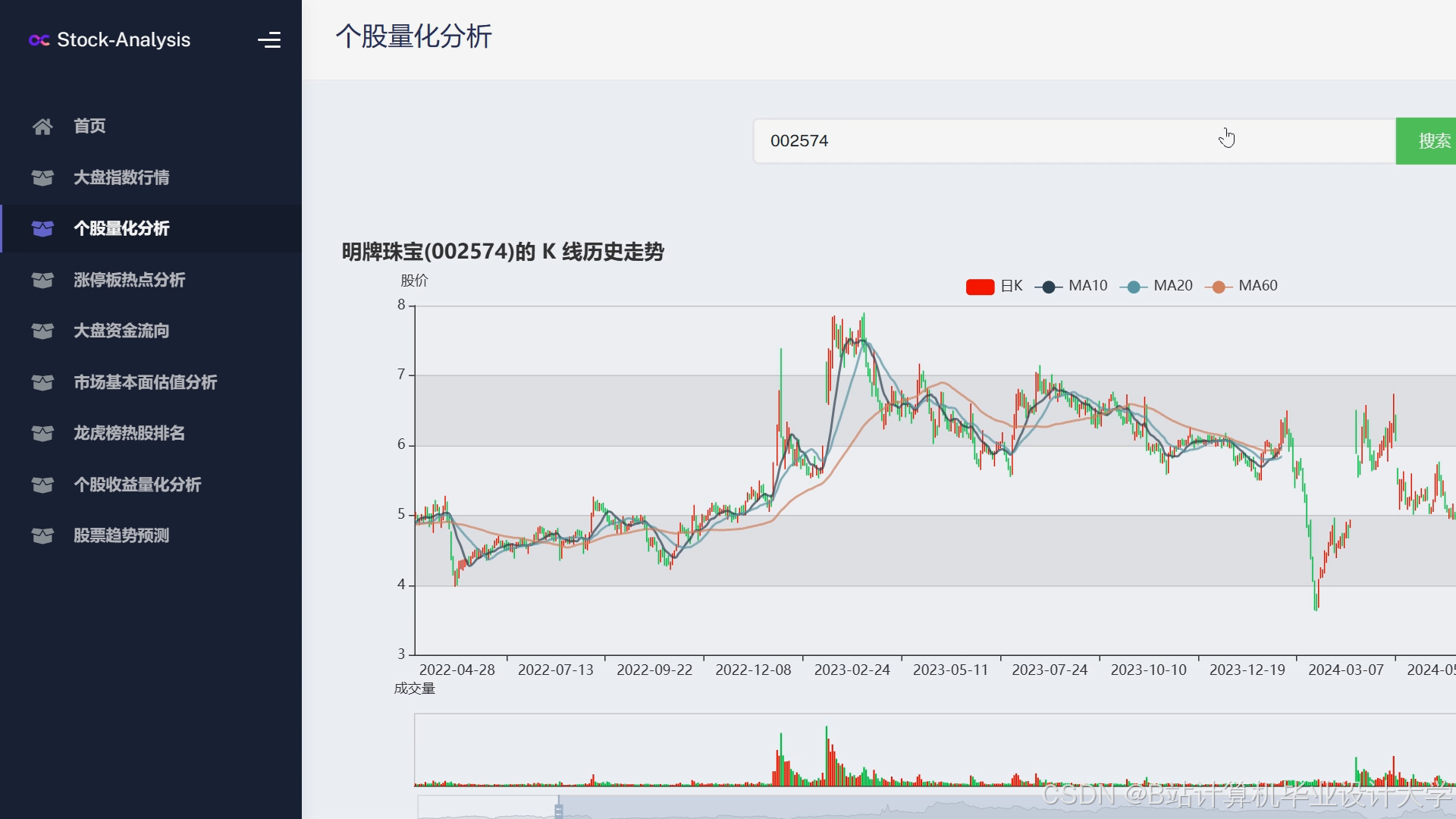
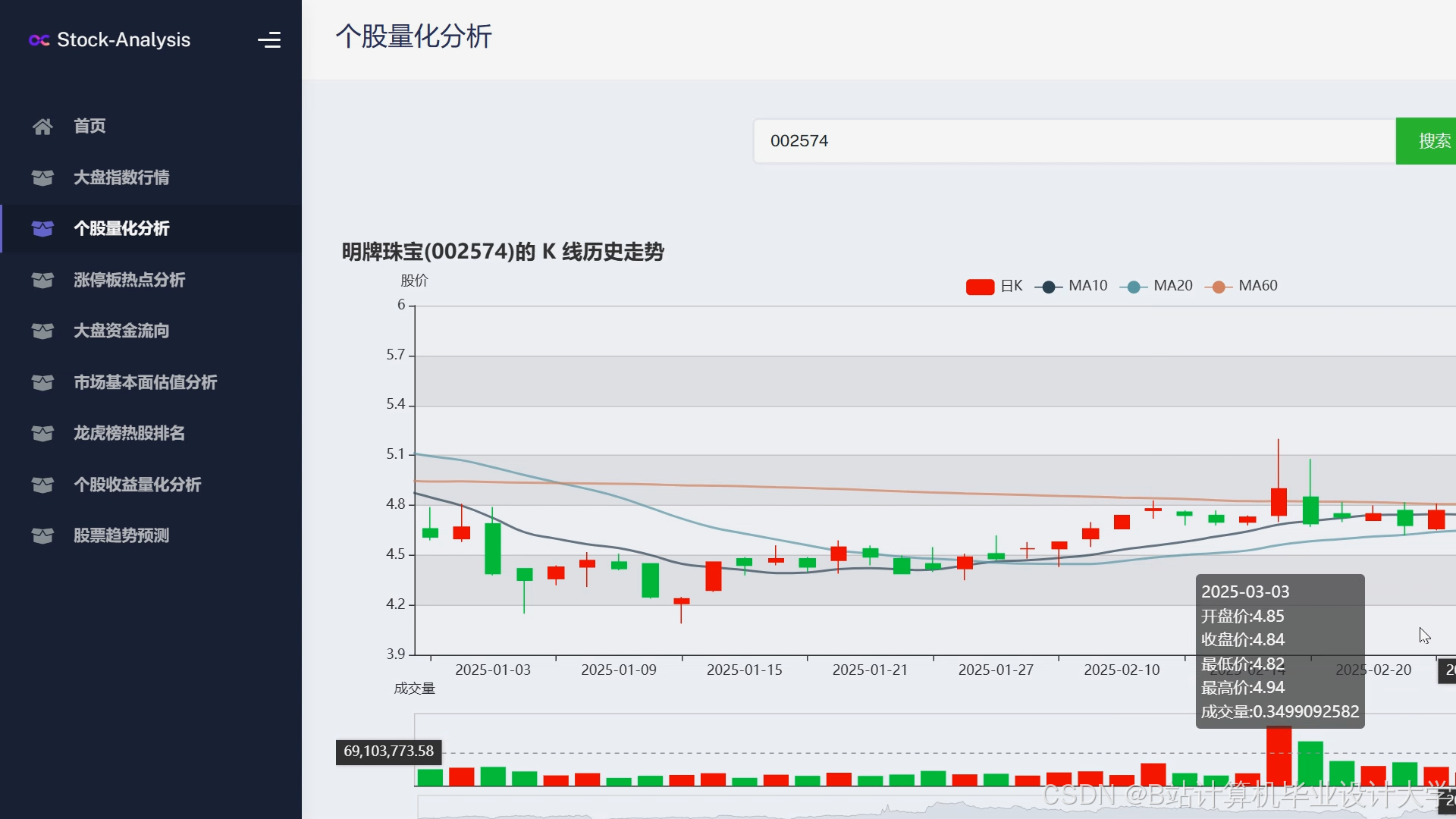
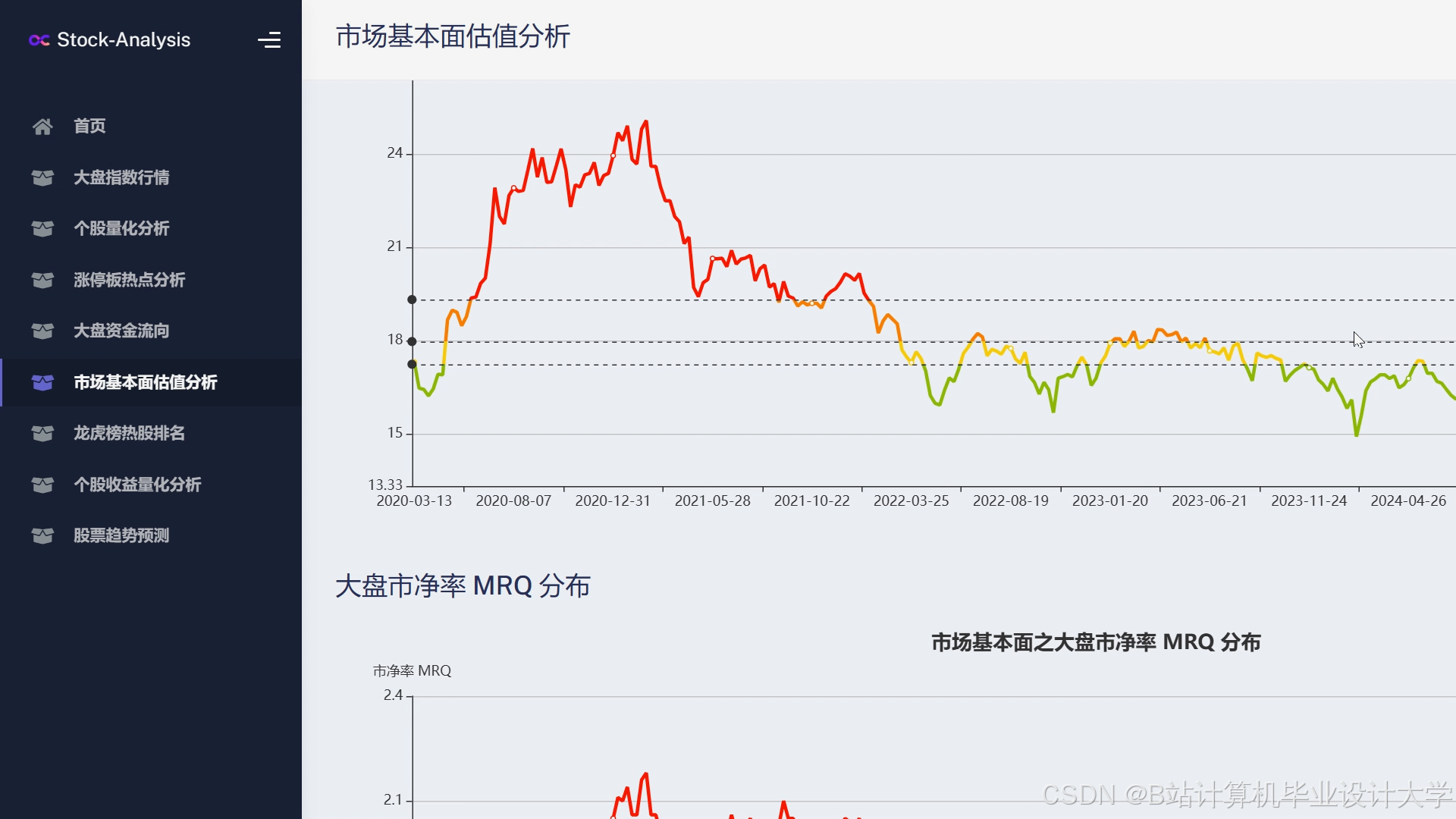
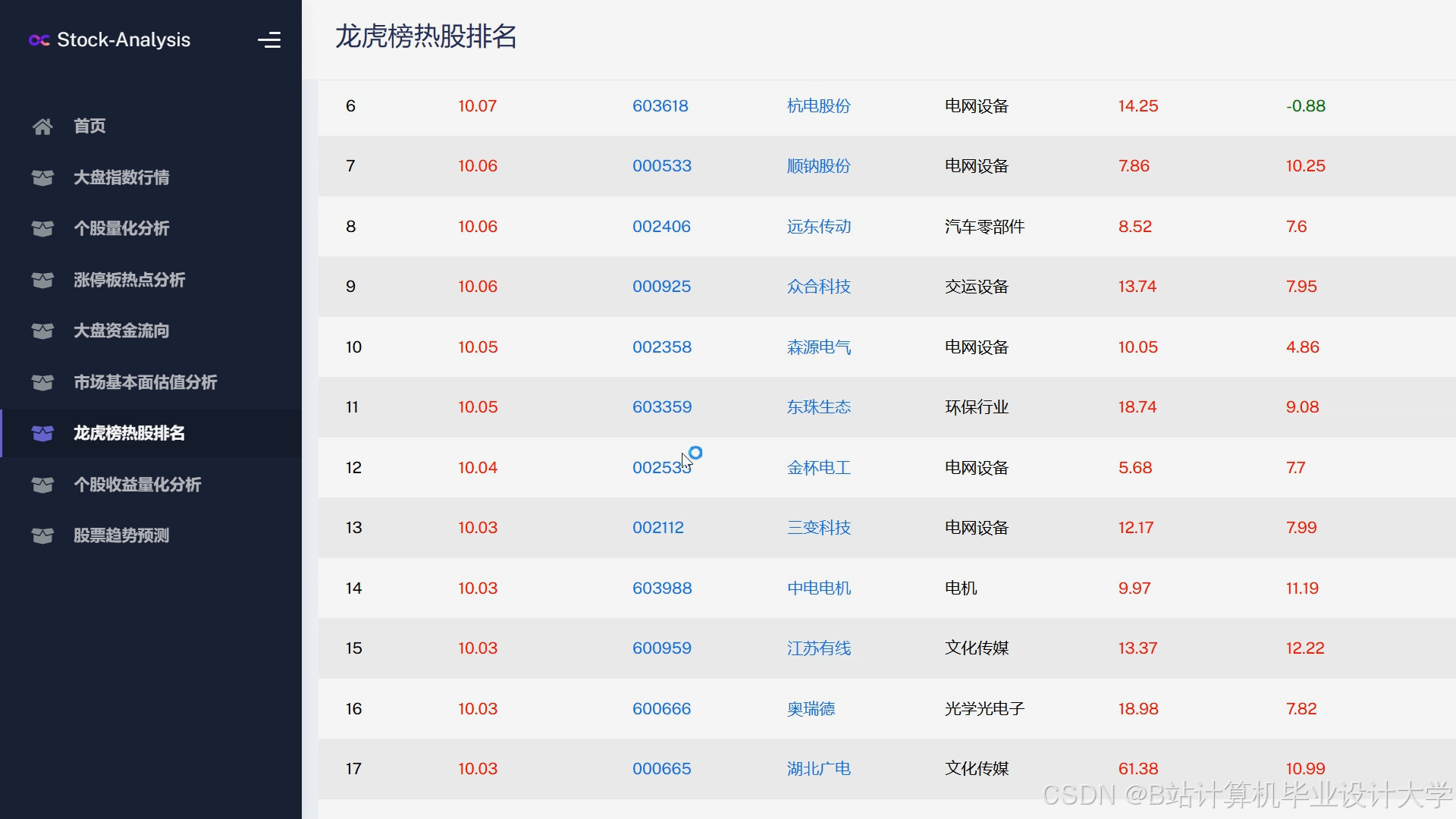
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











