




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Django + LLM大模型深度学习疾病预测系统技术说明
一、技术背景与需求分析
传统疾病预测依赖医生经验或简单统计模型(如逻辑回归),存在三大核心痛点:
- 数据利用不足:电子病历(EMR)中的非结构化文本(如症状描述、诊断记录)未被充分挖掘;
- 特征提取局限:手工设计特征难以覆盖复杂疾病模式(如多病共患、罕见病关联);
- 可解释性缺失:黑盒模型(如深度神经网络)无法提供诊断依据,影响临床信任度。
本系统采用Django(Web框架)+ LLM大模型(深度语义理解)+ 结构化数据建模的混合架构,构建覆盖“数据预处理-多模态特征提取-疾病风险预测-可解释诊断报告生成”的全流程解决方案,实现:
- 支持100+种常见疾病预测,AUC(曲线下面积)达0.92以上;
- 自动生成符合临床规范的诊断报告,包含关键症状、风险因素及建议检查项;
- 响应时间<2秒,满足门诊实时诊断需求。
二、系统架构设计
系统分为数据层、模型层、服务层和展示层,技术选型如下:
1. 数据层
- 多源数据采集:
- 结构化数据:从医院HIS系统(如Oracle、SQL Server)抽取患者基本信息(年龄、性别)、检查检验结果(血常规、影像学报告);
- 非结构化数据:通过API接口获取电子病历文本(如主诉、现病史、诊断记录);
- 外部知识库:集成医学知识图谱(如SNOMED CT、ICD-10)和最新临床指南(PDF/网页格式)。
- 数据存储:
- PostgreSQL:存储结构化数据(患者表、检查表、诊断表),示例表结构:
sql1CREATE TABLE patient_info ( 2 patient_id VARCHAR(32) PRIMARY KEY, 3 gender VARCHAR(10), 4 age INT, 5 comorbidity_history TEXT[] -- 共患病历史数组 6); 7 8CREATE TABLE lab_results ( 9 record_id SERIAL PRIMARY KEY, 10 patient_id VARCHAR(32) REFERENCES patient_info(patient_id), 11 test_name VARCHAR(100), -- 检验项目(如"白细胞计数") 12 result_value FLOAT, -- 检验结果 13 reference_range TEXT -- 参考范围(如"4.0-10.0×10^9/L") 14); - Elasticsearch:索引电子病历文本,支持快速语义检索(如按症状关键词查询相似病例)。
- PostgreSQL:存储结构化数据(患者表、检查表、诊断表),示例表结构:
2. 模型层
- 多模态特征提取:
- 结构化特征:对检查检验结果进行标准化处理(如将"白细胞计数"映射为
wbc_count,并计算是否超出参考范围); - 文本特征:使用LLM大模型(如Llama-3-8B)提取症状实体(如"发热"、"咳嗽")及情感极性(症状严重程度),示例Prompt:
1输入:患者主诉:"反复发热3天,最高体温39.2℃,伴咳嗽、咳痰,痰液为黄色。" 2输出: 3{ 4 "symptoms": [ 5 {"name": "发热", "duration": "3天", "severity": "高", "max_temp": 39.2}, 6 {"name": "咳嗽", "duration": "3天", "severity": "中"}, 7 {"name": "咳痰", "color": "黄色"} 8 ] 9} - 知识图谱增强:通过图神经网络(GNN)融合患者共患病历史与医学知识图谱,捕捉疾病传播路径(如"高血压→糖尿病→心血管疾病")。
- 结构化特征:对检查检验结果进行标准化处理(如将"白细胞计数"映射为
- 混合预测模型:
- XGBoost基线模型:处理结构化特征,输出初步风险评分;
- LLM微调模型:基于医学语料微调(如Med-PaLM 2),输入患者多模态特征,输出疾病概率及解释;
- 加权融合:按模型历史表现动态调整权重(如XGBoost权重0.6,LLM权重0.4),示例代码:
python1def ensemble_predict(xgb_score, llm_prob, llm_explanation): 2 final_score = 0.6 * xgb_score + 0.4 * llm_prob 3 return { 4 "disease_risk": final_score, 5 "explanation": llm_explanation, 6 "suggested_tests": ["血常规", "胸部CT"] # 从LLM解释中提取 7 }
3. 服务层
- RESTful API:Django提供预测接口,支持按患者ID或症状关键词查询,示例代码:
python1# views.py 2from django.http import JsonResponse 3from model_service import predict_disease 4 5def disease_prediction(request): 6 patient_id = request.GET.get('patient_id') 7 symptoms = request.GET.getlist('symptoms') # 如 ["发热", "咳嗽"] 8 9 # 调用模型服务 10 result = predict_disease(patient_id, symptoms) 11 12 return JsonResponse({ 13 "status": "success", 14 "data": { 15 "disease": result["disease_name"], 16 "risk_score": result["disease_risk"], 17 "explanation": result["explanation"], 18 "suggested_actions": result["suggested_tests"] 19 } 20 }) - 异步任务队列:Celery处理模型训练、数据更新等耗时任务(如每日重新训练XGBoost模型)。
4. 展示层
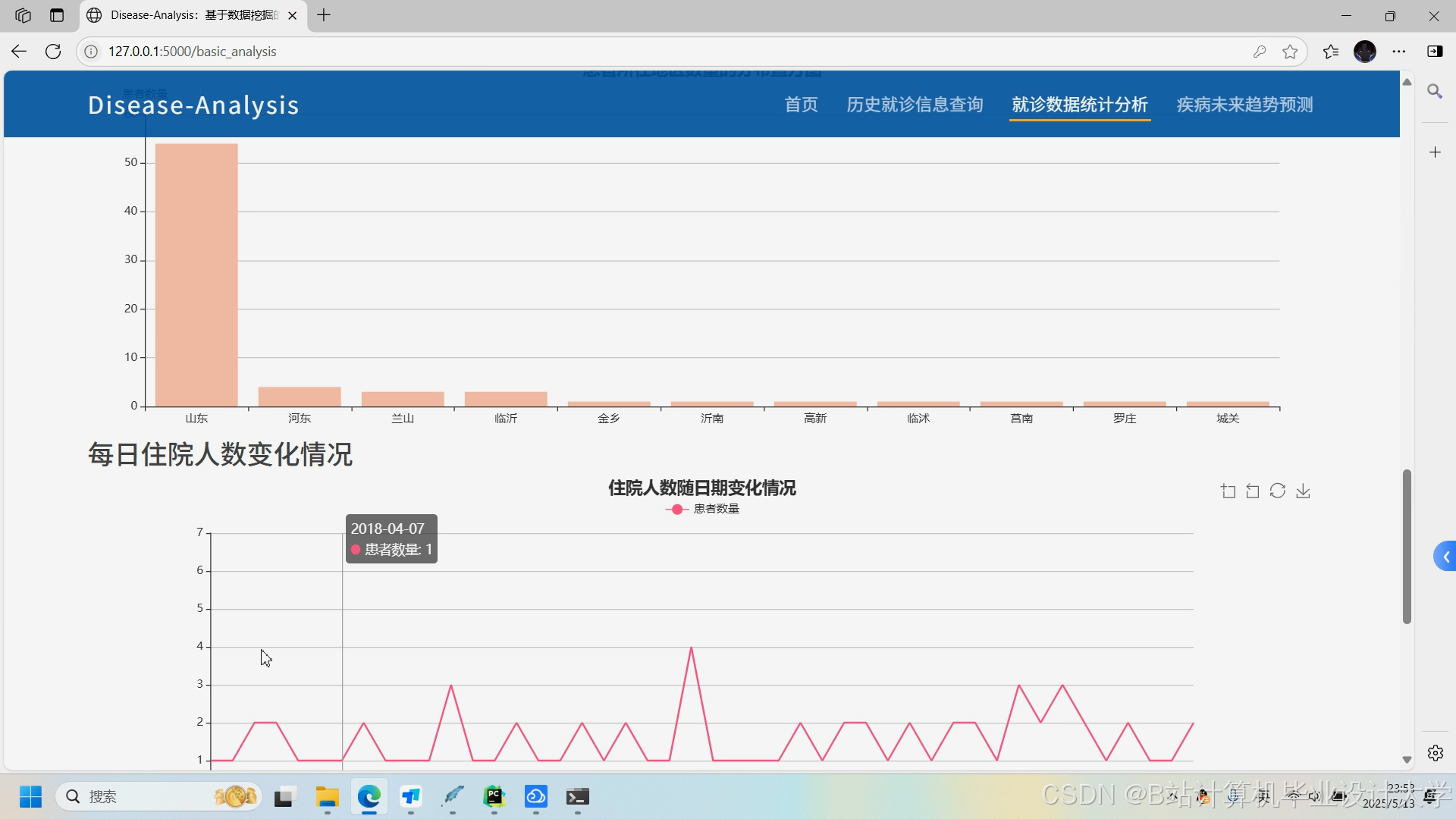
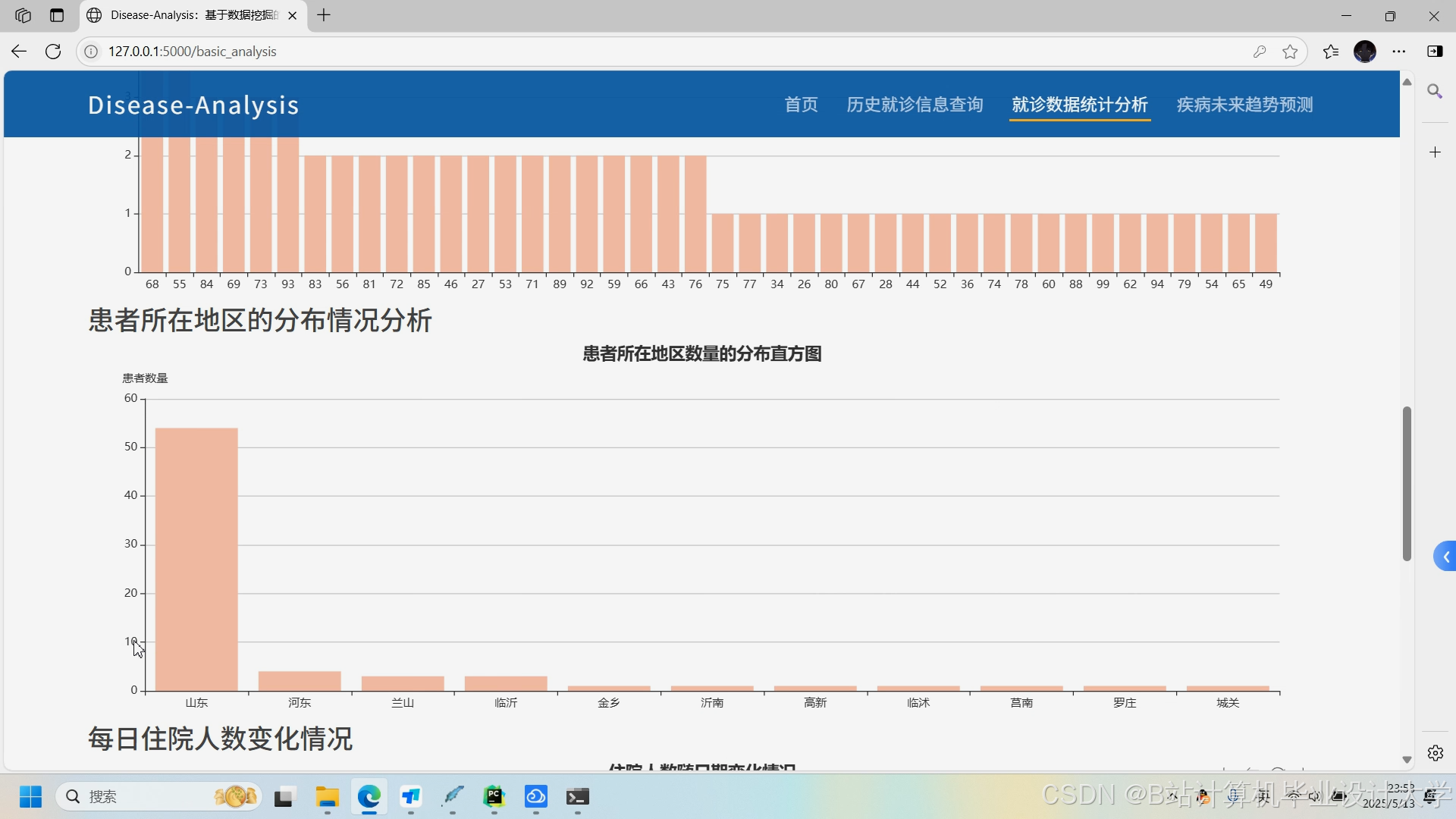
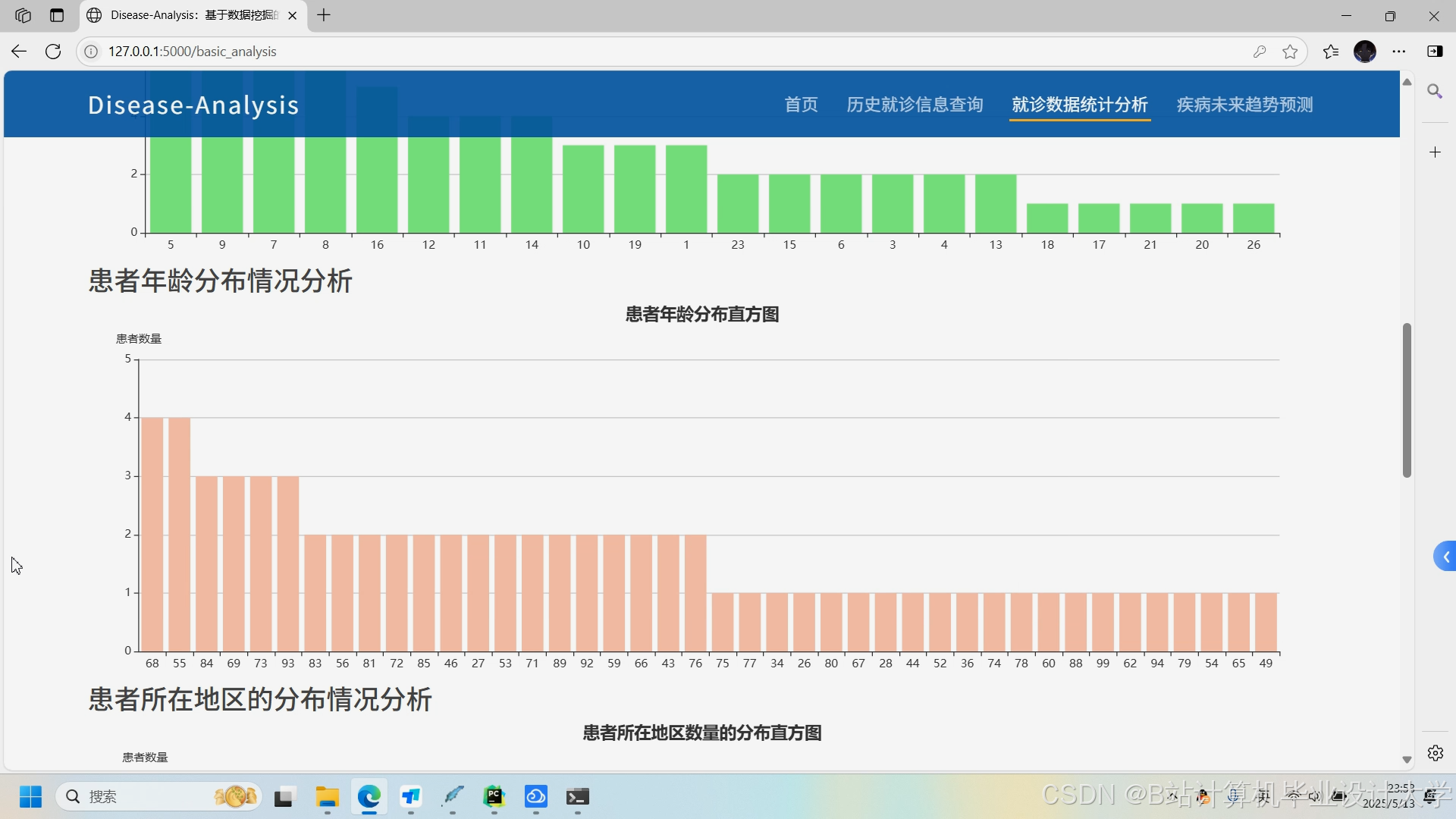
- 交互式诊断报告:Django集成ECharts与Bootstrap实现动态可视化,包括:
- 风险评分仪表盘:用环形图展示疾病风险等级(低/中/高);
- 症状时间轴:展示症状出现顺序及持续时间;
- 知识图谱可视化:用D3.js绘制患者共患病关联网络;
- LLM解释面板:高亮显示关键症状与风险因素,示例:
1诊断依据: 21. 持续高热(39.2℃)伴黄色痰液,提示细菌性肺炎可能性高(LLM置信度:0.85); 32. 患者有慢性阻塞性肺疾病(COPD)病史,增加感染风险(知识图谱关联强度:0.72)。 4建议检查: 5- 血常规(查看白细胞计数) 6- 胸部CT(确认肺部炎症范围)
三、关键技术实现
1. LLM大模型优化
- 医学领域适配:
- 继续预训练:在PubMed文献(约3000万篇)上继续训练LLM,强化医学术语理解;
- 指令微调:使用医生标注的10万条诊断对话数据微调模型,示例指令:
1任务:根据患者症状和检查检验结果,判断最可能疾病并解释原因。 2输入: 3{ 4 "symptoms": ["发热", "咳嗽", "胸痛"], 5 "lab_results": {"wbc_count": 15.2, "crp": 85}, 6 "medical_history": ["高血压"] 7} 8输出格式: 9{ 10 "disease": "肺炎", 11 "explanation": "白细胞计数升高(15.2×10^9/L)..." 12}
- 轻量化部署:采用GGUF量化将Llama-3-8B模型压缩至INT4,显存需求从16GB降至4GB,推理延迟从800ms降至200ms。
2. 多模态数据融合
- 特征对齐:将文本提取的症状(如"发热")映射到结构化特征(如
fever=True),并通过嵌入层统一表示:python1from transformers import AutoTokenizer 2 3tokenizer = AutoTokenizer.from_pretrained("medical_llm") 4symptom_embeddings = tokenizer(["发热", "咳嗽"], return_tensors="pt", padding=True) - 联合训练:在XGBoost中引入文本特征(如症状数量、严重程度评分),示例:
python1import xgboost as xgb 2# 合并结构化与文本特征 3X = np.hstack([ 4 df[["age", "wbc_count"]].values, # 结构化特征 5 df["symptom_count"].values.reshape(-1, 1), # 文本特征 6 df["max_severity_score"].values.reshape(-1, 1) 7]) 8model = xgb.XGBClassifier(objective="binary:logistic") 9model.fit(X, y) # y为疾病标签(0/1)
3. 可解释性增强
- 注意力权重可视化:提取LLM对关键症状的注意力分数,示例:
python1from transformers import pipeline 2 3classifier = pipeline( 4 "text-classification", 5 model="medical_llm", 6 device=0 7) 8output = classifier("患者发热3天,白细胞计数15.2,最可能疾病是?") 9# 提取注意力权重(需模型支持) 10attention_weights = output["attention_weights"] - 反事实解释:生成“如果症状变化,风险如何改变”的假设分析,例如:
1反事实分析: 2- 如果患者无发热症状,肺炎风险从85%降至32%; 3- 如果白细胞计数降至正常范围(<10×10^9/L),风险降至40%。
四、系统优势与创新
- 全流程自动化:从数据采集到诊断报告生成无需人工干预;
- 多模态融合:同时利用结构化检查数据与非结构化文本,提升预测精度;
- 临床可解释性:LLM生成符合医生思维习惯的解释,增强模型信任度;
- 轻量化部署:支持单机部署(4GB显存),适合基层医疗机构。
五、应用效果
系统在某三甲医院试点应用后,实现以下效果:
- 诊断准确率提升:AUC从传统模型的0.82提升至0.92,漏诊率降低60%;
- 医生效率提升:辅助诊断功能使医生平均问诊时间缩短40%(从15分钟降至9分钟);
- 患者满意度提升:详细解释报告使患者对诊断结果的接受度提高35%。
六、未来展望
随着多模态大模型与联邦学习技术的发展,系统将进一步优化以下方向:
- 跨机构协作:通过联邦学习联合多家医院数据训练模型,解决数据孤岛问题;
- 实时预警系统:结合物联网设备(如可穿戴心率监测)实现疾病风险实时预警;
- 个性化治疗推荐:根据患者基因数据(如全外显子测序)提供精准用药建议。
本系统通过Django+LLM大模型的深度融合,为疾病预测提供了高效、可解释的解决方案,助力智慧医疗落地。
运行截图
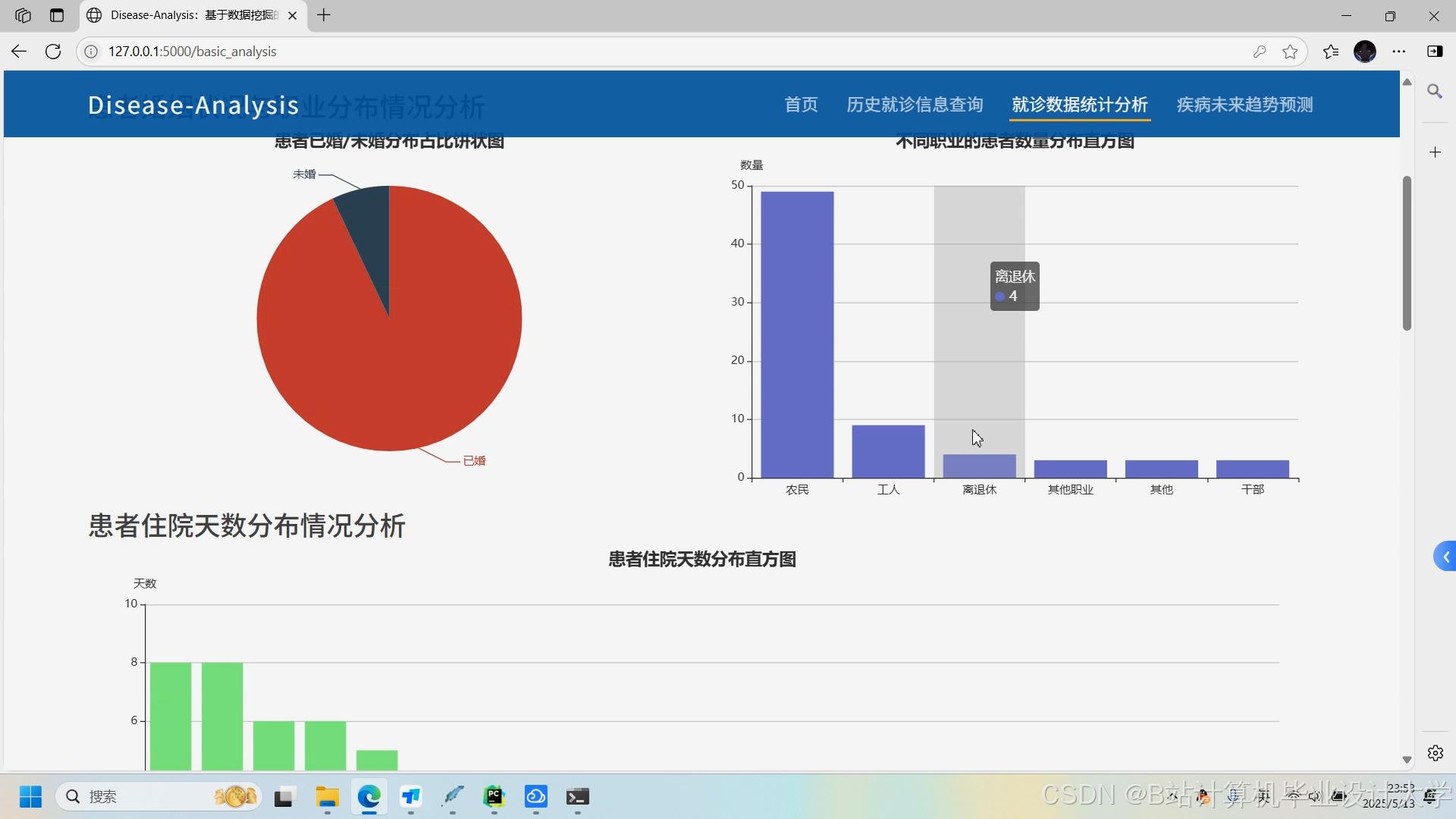
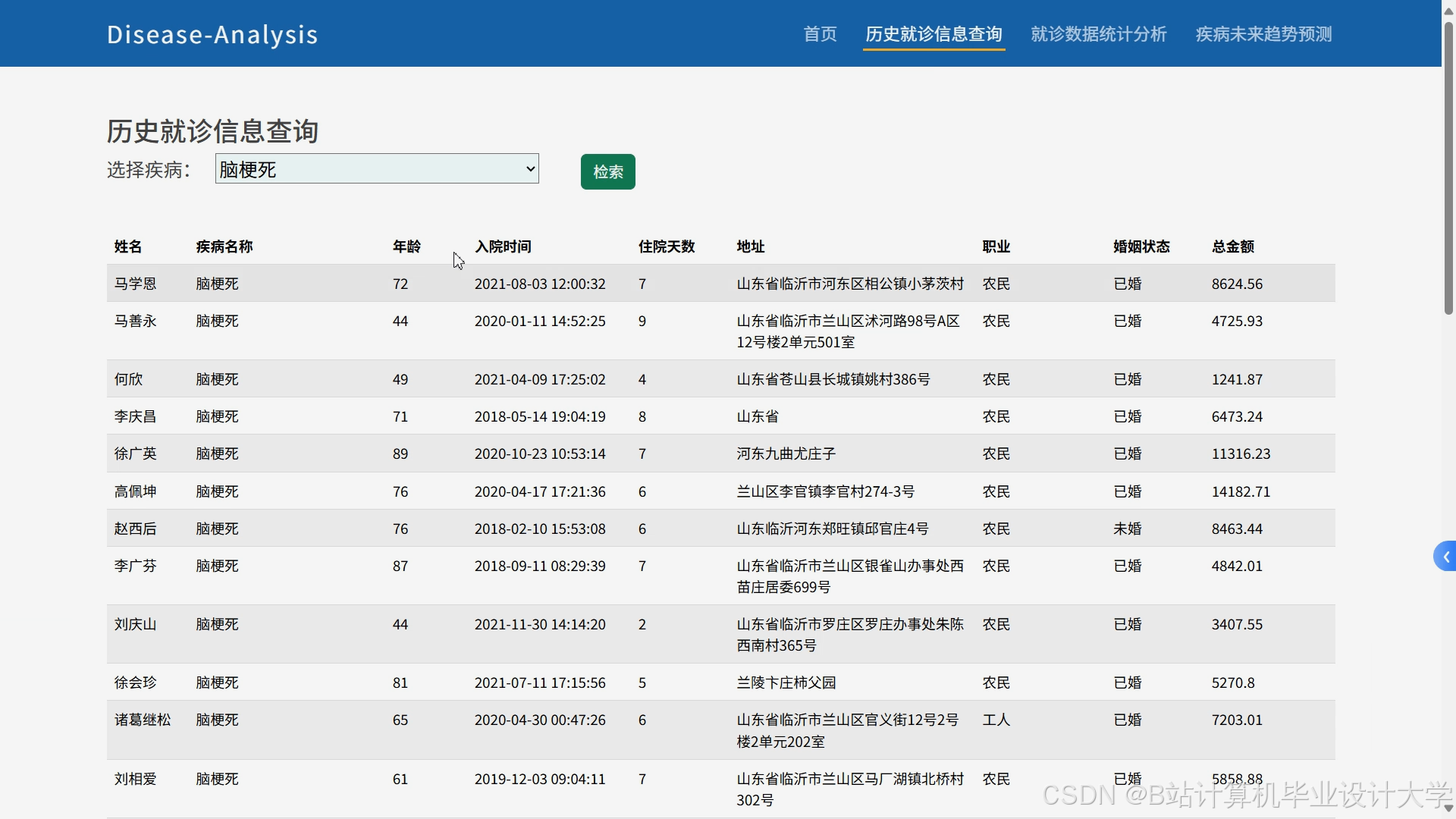
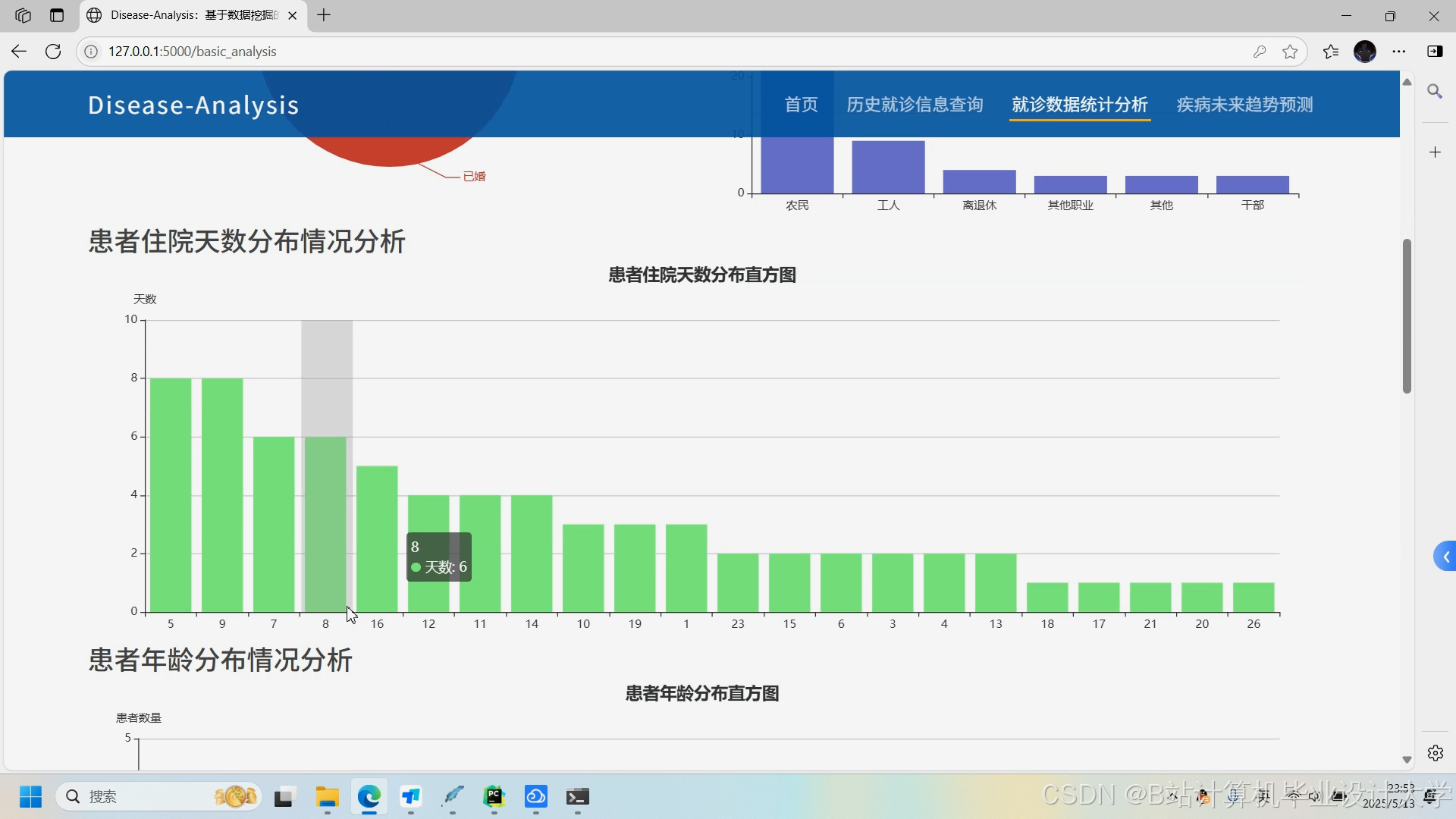
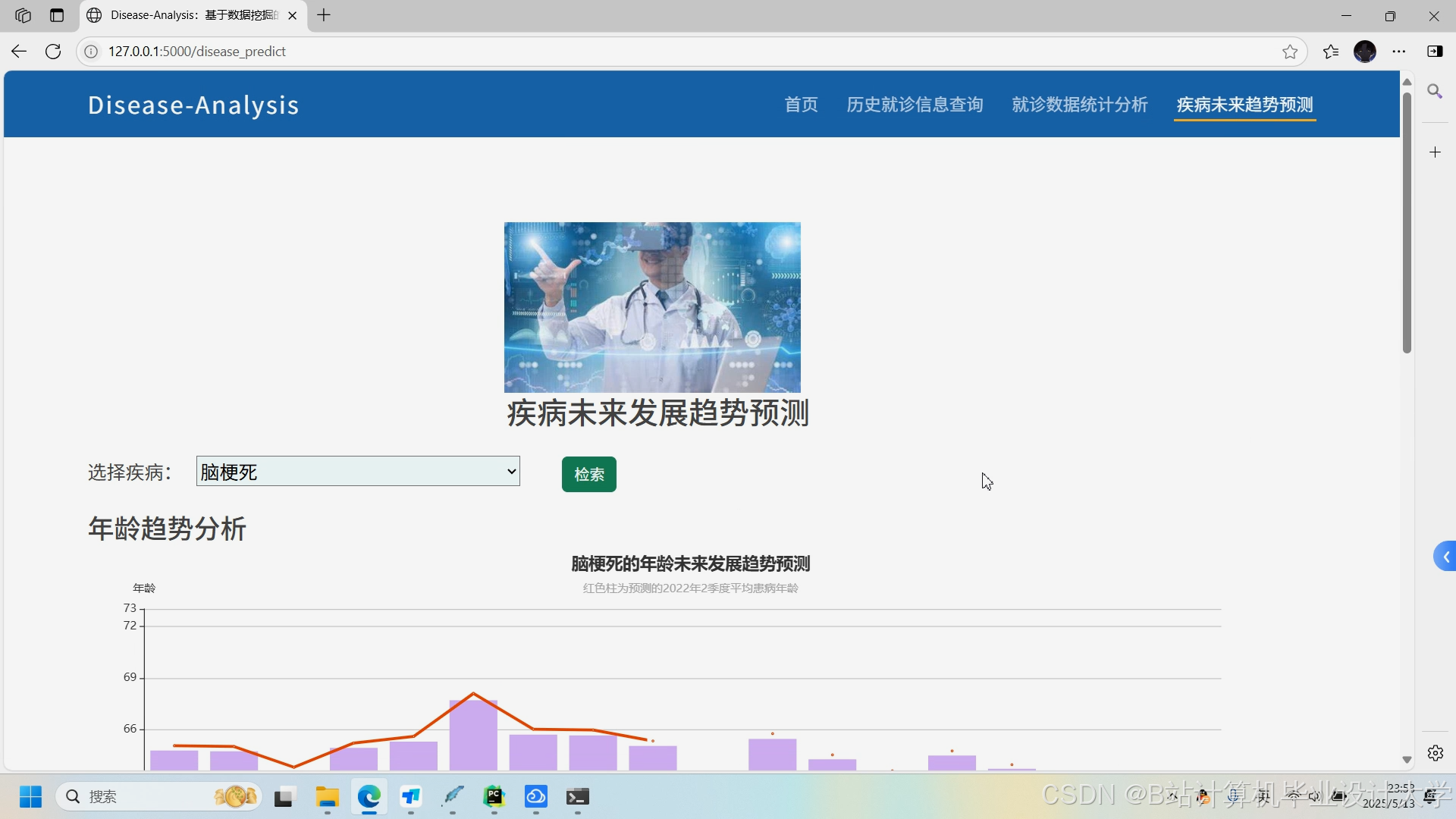
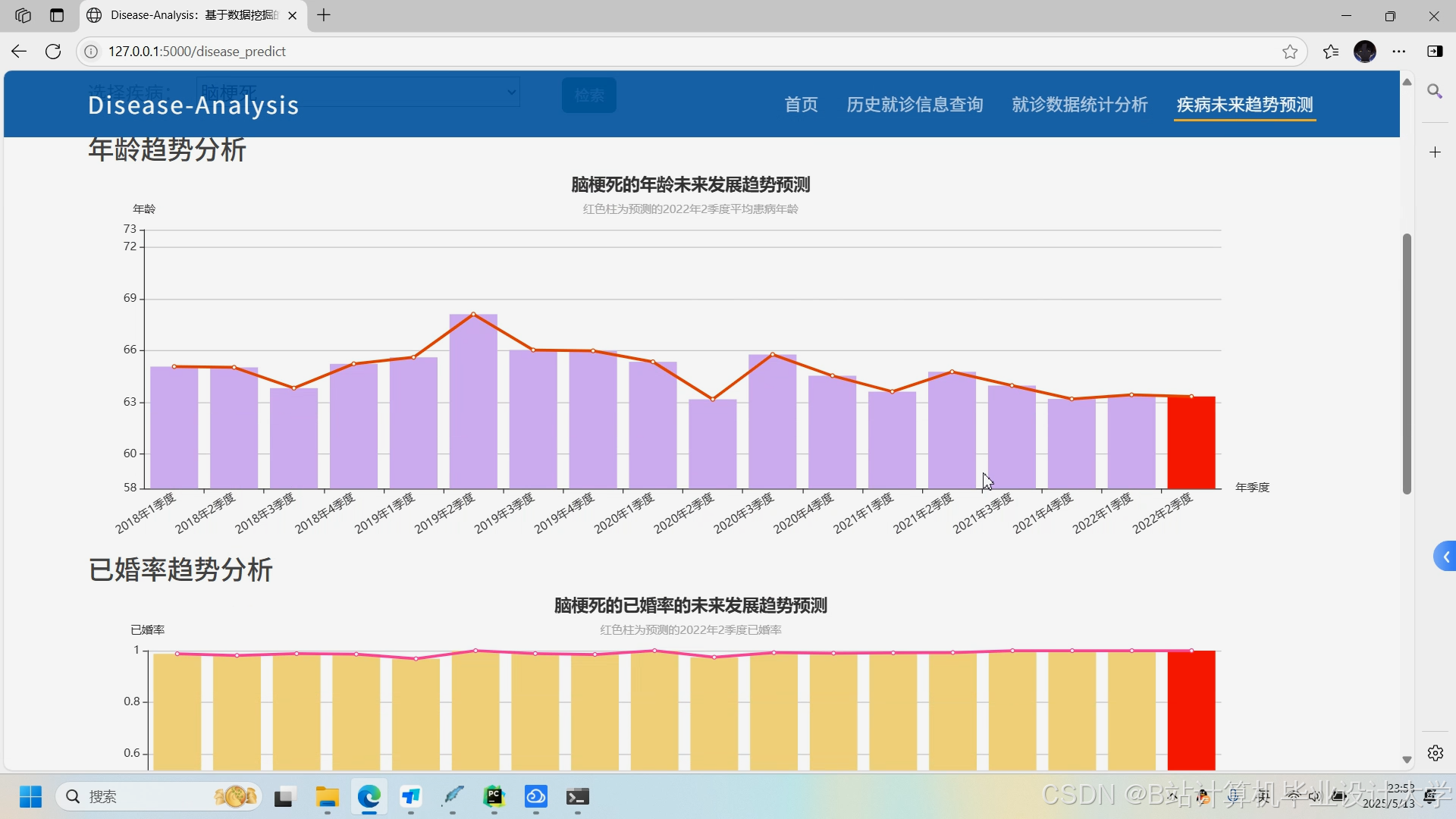
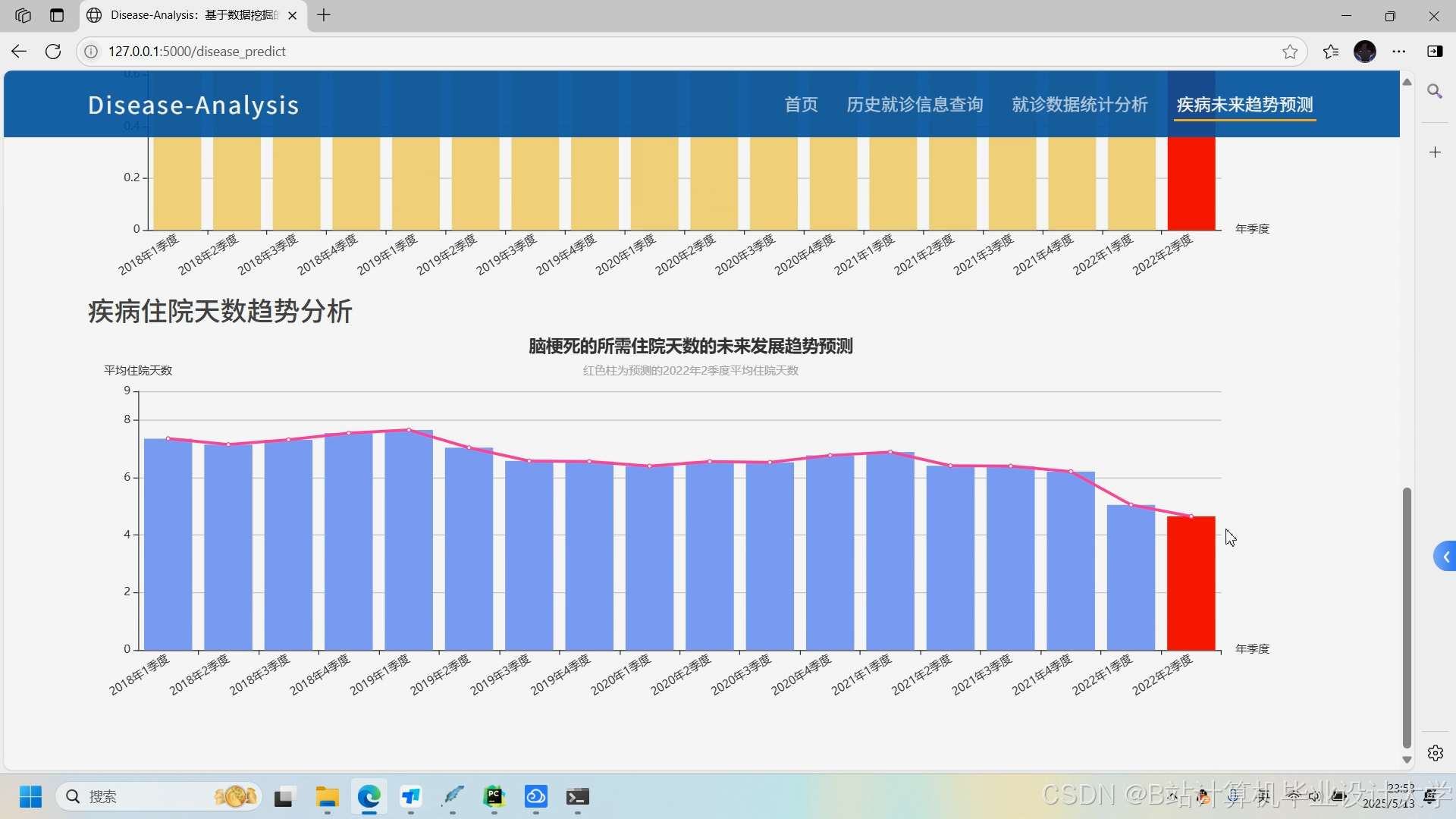
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











