




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
以下是一篇关于《Django+LLM大模型垃圾邮件分类与检测系统》的技术说明文档,涵盖系统架构、核心模块、技术实现及创新点等内容:
Django+LLM大模型垃圾邮件分类与检测系统技术说明
1. 系统概述
本系统基于Django框架与大型语言模型(LLM),构建一个智能化的垃圾邮件分类与检测平台。系统通过LLM深度解析邮件文本内容(如标题、正文、附件),结合传统机器学习模型(如TF-IDF、SVM)与深度学习模型(如BERT),实现高精度、低误报的垃圾邮件识别,并通过Django提供实时检测API与可视化管理界面。
核心目标:
- 支持多语言邮件的精准分类(垃圾邮件/正常邮件/钓鱼邮件);
- 利用LLM理解复杂语义(如隐晦的诈骗话术、伪装成正常链接的恶意URL);
- 提供低延迟的实时检测服务与可扩展的管理后台。
2. 系统架构设计
系统采用微服务化分层架构,分为数据层、模型层、服务层与用户层,具体如下:
mermaid
1graph TB
2 A[数据层] --> B[模型层]
3 B --> C[服务层]
4 C --> D[用户层]
5
6 subgraph 数据层
7 A1[邮件数据: 标题、正文、附件、发件人元数据]
8 A2[标签数据: 人工标注的垃圾邮件样本库]
9 A3[外部知识库: 恶意域名列表、钓鱼关键词库]
10 end
11
12 subgraph 模型层
13 B1[LLM语义理解模块]
14 B2[传统特征提取模块: TF-IDF、关键词匹配]
15 B3[深度学习分类模型: BERT/RoBERTa微调]
16 B4[规则引擎: 基于正则表达式的显式攻击检测]
17 end
18
19 subgraph 服务层
20 C1[Django后端API]
21 C2[实时检测引擎]
22 C3[模型管理平台: 训练/评估/部署]
23 end
24
25 subgraph 用户层
26 D1[Web端: 管理员审核界面]
27 D2[邮件客户端插件: Outlook/Gmail集成]
28 end3. 核心模块与技术实现
3.1 数据采集与预处理模块
- 邮件数据获取:
- 通过IMAP/SMTP协议实时拉取企业邮箱或个人邮箱的邮件;
- 解析邮件头(Header)提取发件人IP、域名等元数据;
- 使用
Apache Tika提取附件中的文本内容(如PDF、Word)。
- 数据清洗:
- 去除HTML标签、特殊符号、重复空格;
- 对多语言邮件进行语言检测(
langdetect库),按语言分组处理。
技术工具:
- 邮件协议:
imaplib(Python标准库); - 附件解析:
Tika-Python; - 语言检测:
polyglot或fasttext。
3.2 垃圾邮件检测模型模块
3.2.1 LLM辅助的语义分析
- 输入特征:
- 基础特征:邮件标题、正文、发件人域名;
- LLM生成特征:
- 语义相似度:与已知钓鱼邮件模板的相似度(Sentence-BERT);
- 情感分析:检测欺诈性话术(如“紧急”“免费领取”);
- 实体识别:提取URL、电话号码、银行账号等可疑实体。
- 特征融合:
- 将LLM生成的语义向量(768维)与传统特征(如关键词出现频率)拼接,输入分类模型。
3.2.2 多模型融合检测
- 模型1:规则引擎
- 基于正则表达式匹配显式攻击(如
http://*.xyz、点击链接领取奖金); - 结合外部知识库(如PhishTank的恶意域名列表)进行黑名单过滤。
- 基于正则表达式匹配显式攻击(如
- 模型2:传统机器学习
- 使用TF-IDF向量化文本,训练SVM或随机森林分类器;
- 适用于短文本(如邮件标题)的快速筛查。
- 模型3:深度学习模型
- 微调BERT/RoBERTa模型,输入为
[CLS]标题[SEP]正文[SEP],输出分类概率; - 针对长文本(如正文)捕捉上下文依赖关系。
- 微调BERT/RoBERTa模型,输入为
- 模型4:LLM增强决策
- 对低置信度样本(如模型预测概率在0.4~0.6之间),调用LLM进行二次判断;
- 示例提示词(Prompt):
text1判断以下邮件是否为垃圾邮件,并给出理由: 2标题:您的账户存在异常,请立即验证! 3正文:尊敬的客户,我们检测到您的账户在异地登录,请点击链接重置密码:http://fake-bank.xyz
示例代码(模型融合逻辑):
python
1def predict_spam(email_text, title):
2 # 规则引擎快速过滤
3 if is_blacklisted_domain(email_text) or contains_phishing_keywords(title):
4 return "SPAM"
5
6 # 传统模型预测
7 tfidf_feat = tfidf_vectorizer.transform([email_text])
8 svm_prob = svm_model.predict_proba(tfidf_feat)[0][1]
9
10 # 深度学习模型预测
11 bert_input = tokenizer(title, email_text, return_tensors="pt", padding=True)
12 with torch.no_grad():
13 bert_output = bert_model(**bert_input).logits
14 bert_prob = torch.sigmoid(bert_output).item()
15
16 # LLM增强决策(仅对低置信度样本)
17 if abs(svm_prob - 0.5) < 0.2 or abs(bert_prob - 0.5) < 0.2:
18 llm_result = call_llm_api(title, email_text) # 调用GPT-4等API
19 return "SPAM" if llm_result["is_spam"] else "HAM"
20
21 # 加权融合
22 final_prob = 0.4 * svm_prob + 0.6 * bert_prob
23 return "SPAM" if final_prob > 0.5 else "HAM"3.3 Django服务层实现
- API设计:
- 使用Django REST Framework(DRF)构建以下接口:
POST /api/detect:接收邮件内容,返回分类结果与置信度;GET /api/stats:获取垃圾邮件拦截统计(按时间、类型分组)。
- 使用Django REST Framework(DRF)构建以下接口:
- 实时检测引擎:
- 集成Celery异步任务队列,处理高并发邮件检测请求;
- 使用Redis缓存频繁访问的域名黑名单,降低数据库压力。
- 模型管理平台:
- 通过Django Admin界面上传新样本、触发模型重训练;
- 集成MLflow跟踪模型性能(如准确率、召回率)。
示例代码(Django View):
python
1from rest_framework.views import APIView
2from rest_framework.response import Response
3from .models import EmailDetectionRecord
4from .tasks import detect_spam_async # Celery异步任务
5
6class DetectSpamAPI(APIView):
7 def post(self, request):
8 email_data = request.data
9 # 异步调用检测任务
10 task_id = detect_spam_async.delay(email_data)
11 return Response({"task_id": task_id, "status": "pending"})
12
13class DetectionResultAPI(APIView):
14 def get(self, request, task_id):
15 # 从Redis或数据库查询任务结果
16 result = get_task_result(task_id)
17 return Response({
18 "is_spam": result["is_spam"],
19 "confidence": result["confidence"],
20 "reason": result["reason"] # LLM生成的解释
21 })4. 系统创新点
- LLM驱动的语义理解:
- 传统方法依赖关键词匹配,易被绕过(如“免费领奨”替换“免费领取”);
- LLM可识别变形词、隐晦话术,甚至模拟人类判断逻辑。
- 动态模型融合策略:
- 根据样本难度自动选择检测路径(简单样本→规则引擎;复杂样本→LLM);
- 降低整体计算成本,同时保证高风险样本的准确率。
- 可解释性输出:
- LLM生成分类理由(如“邮件包含伪造的银行链接”),辅助管理员审核。
5. 测试与优化
- 数据集:
- 使用公开数据集(如Enron-Spam、TREC)与真实企业邮件进行测试;
- 对比纯BERT模型与LLM融合模型的F1值(重点提升钓鱼邮件检测率)。
- 优化方向:
- 引入轻量化LLM(如Phi-3)降低延迟;
- 支持增量学习,持续吸收新样本更新模型。
6. 总结
本系统通过结合Django的快速开发能力与LLM的语义理解优势,构建了一个高精度、可扩展的垃圾邮件检测平台。未来可扩展至社交媒体消息、短信诈骗等场景,推动AI在网络安全领域的应用落地。
备注:实际部署时需考虑LLM API的调用成本(如OpenAI API费用),可通过本地化部署开源模型(如Llama 3)优化成本。
运行截图
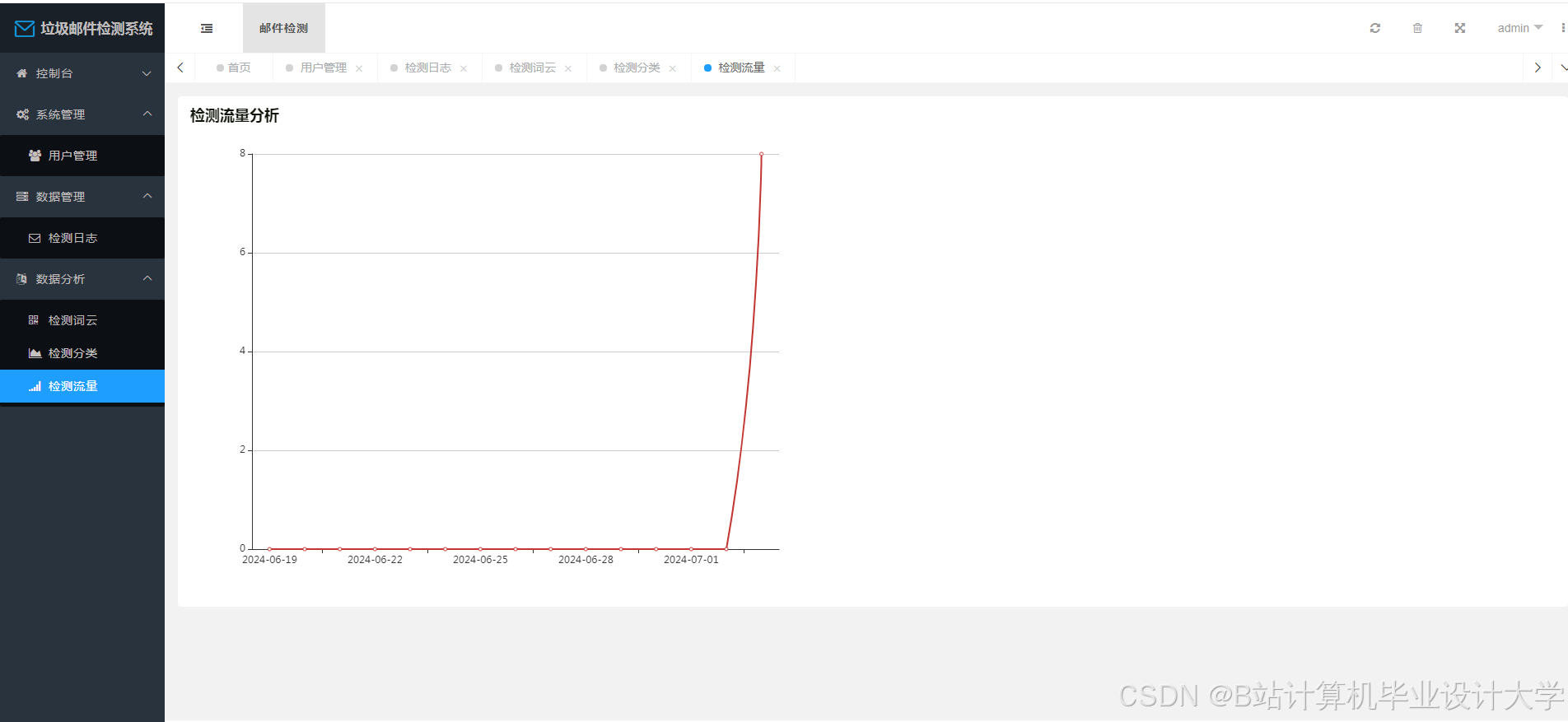

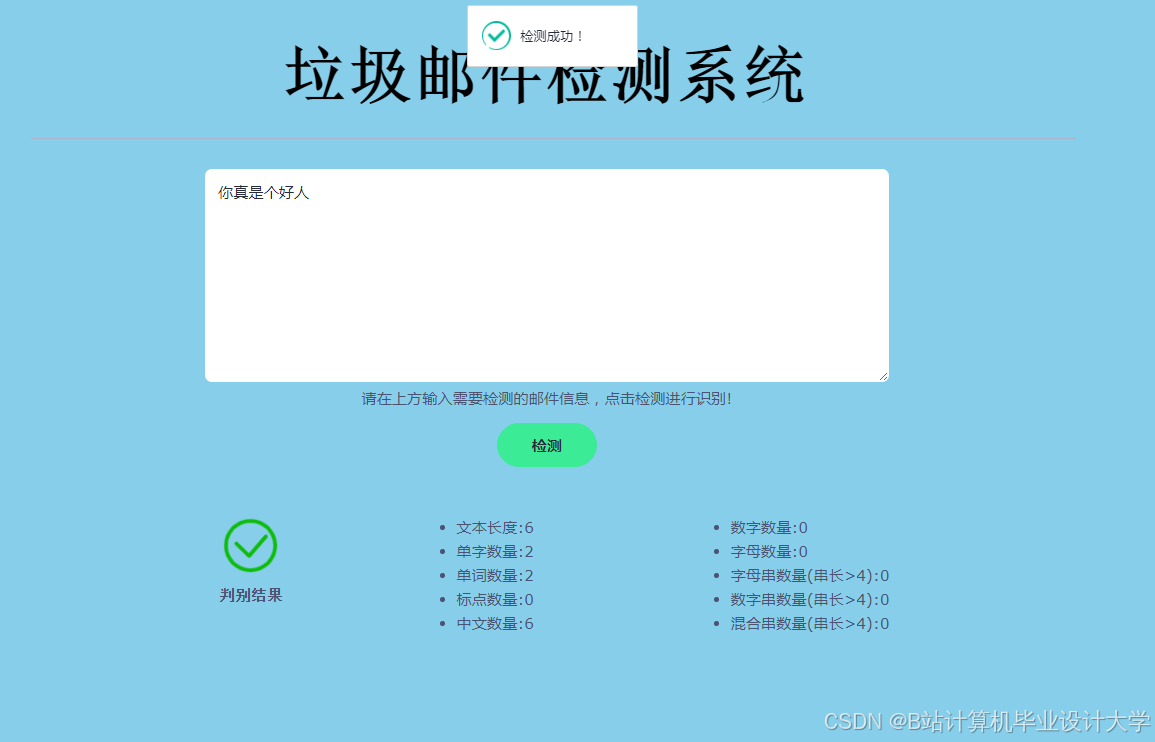

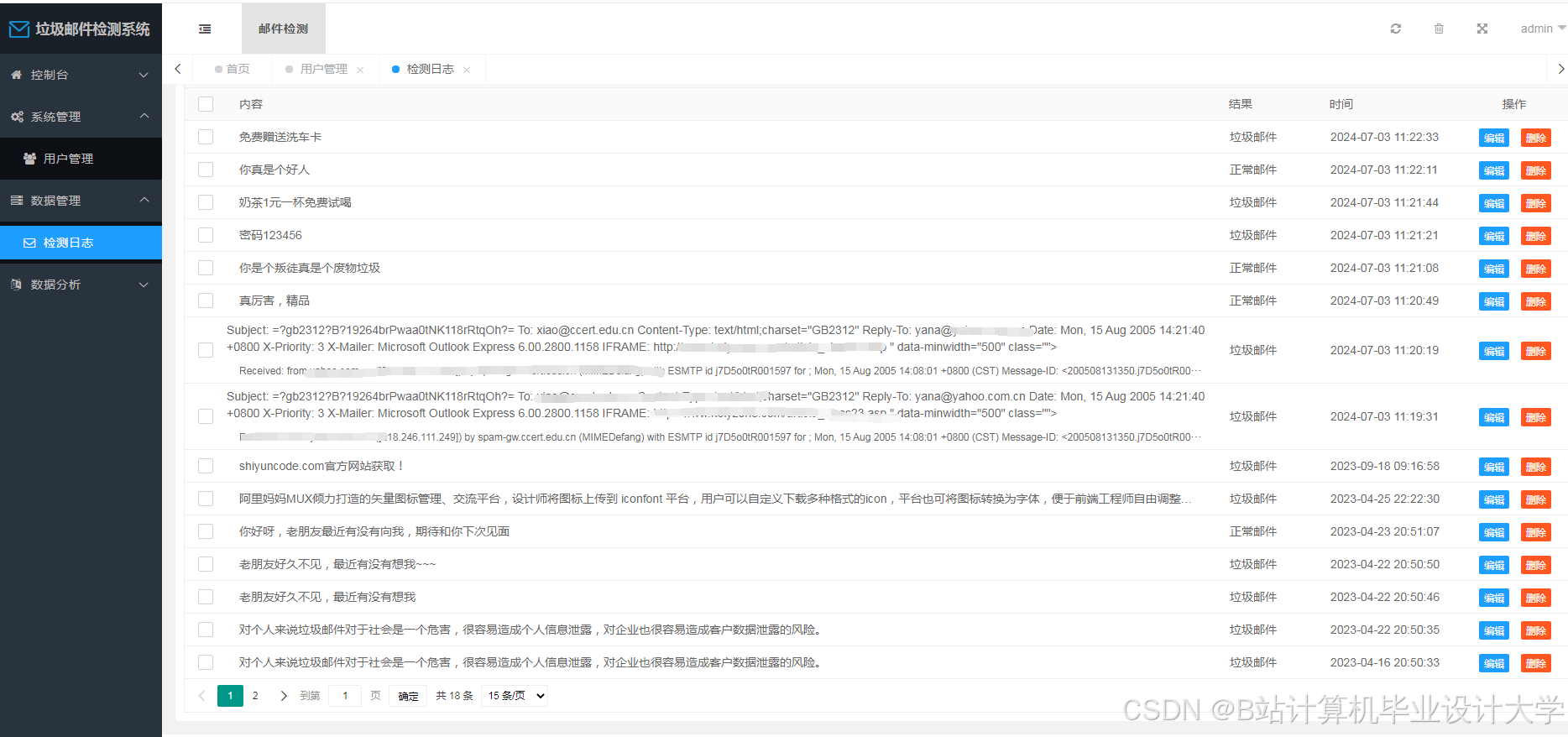
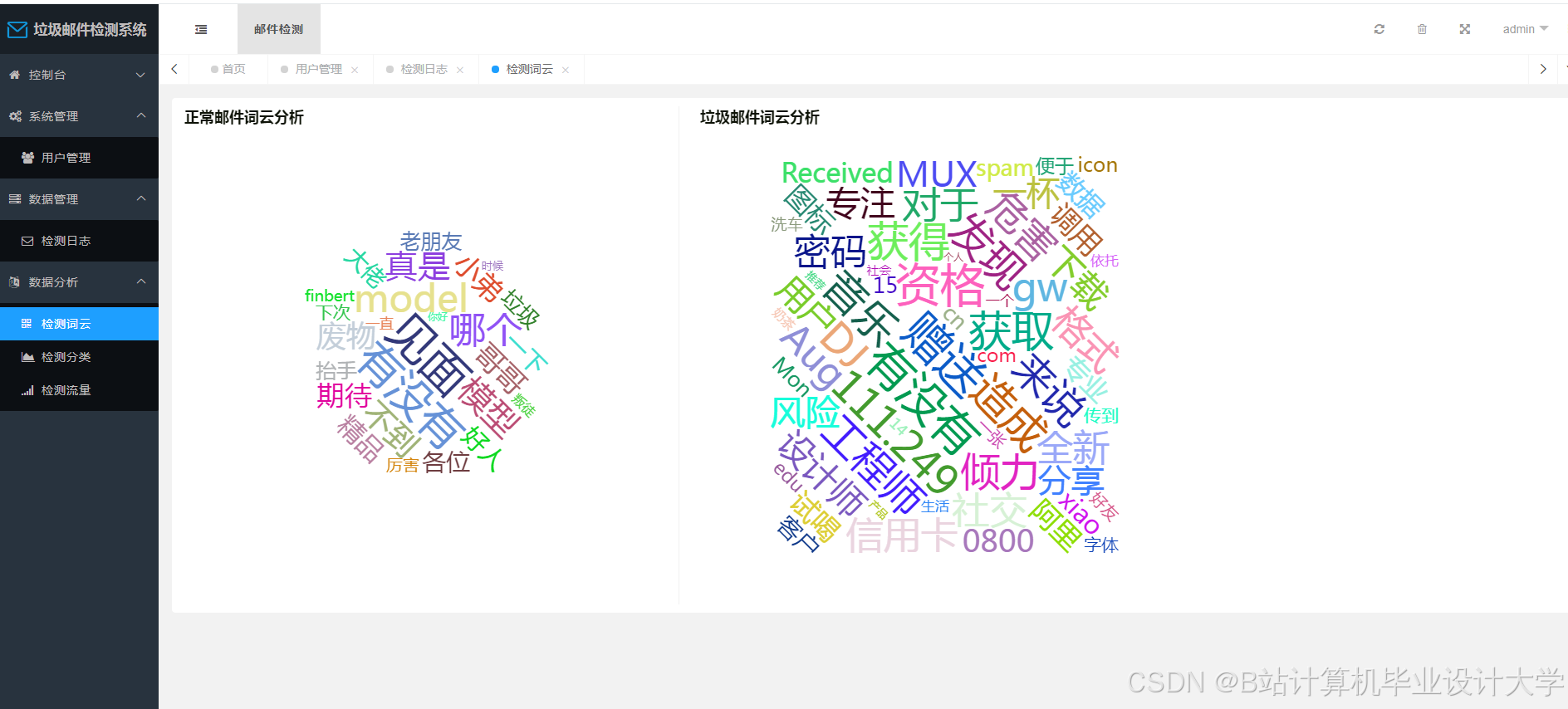
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











