




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
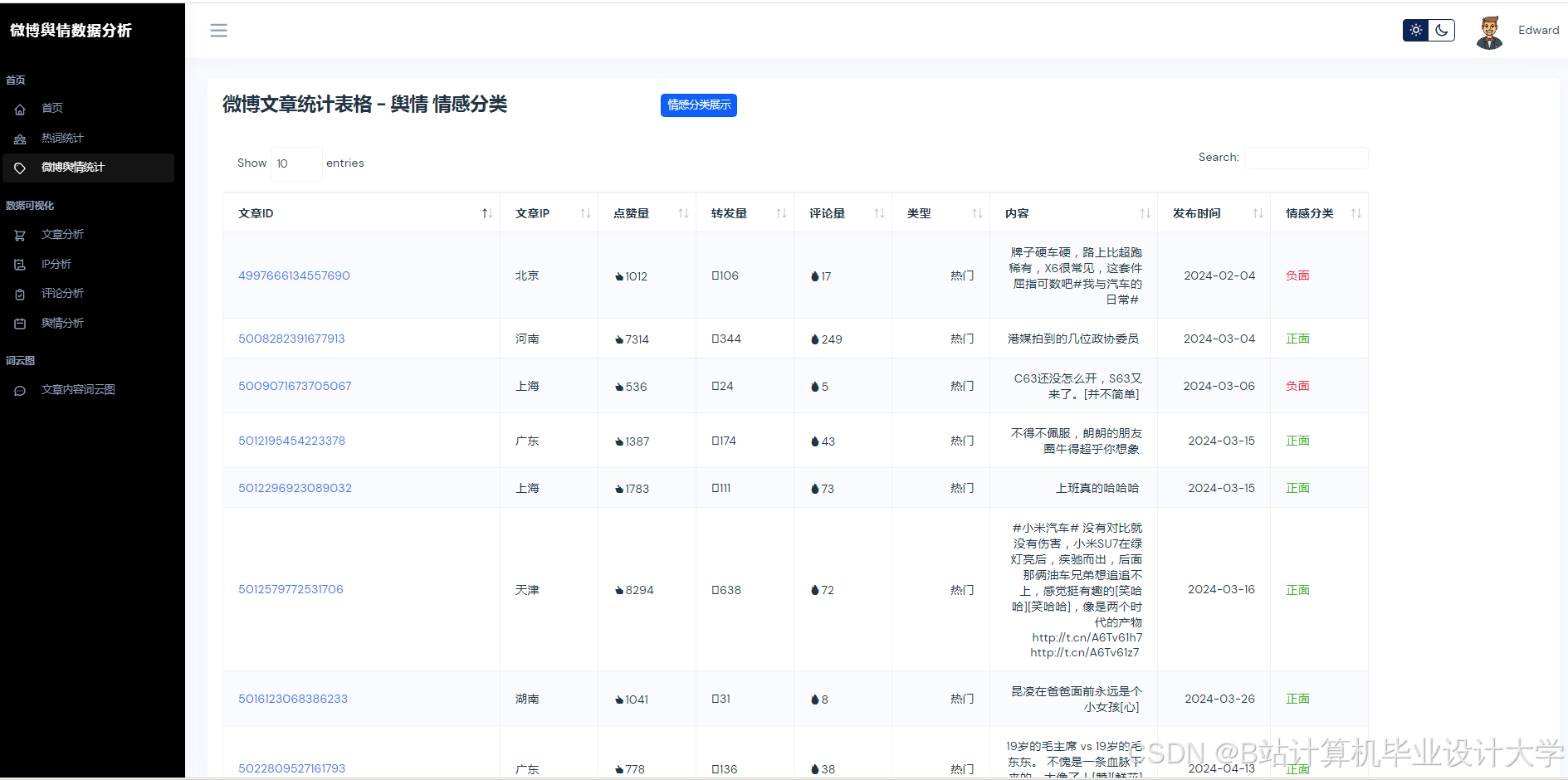
Python+百度千问大模型微博舆情分析预测
摘要:随着社交媒体平台微博的快速发展,其日均产生海量用户生成内容,蕴含丰富的社会舆情信息。传统舆情分析方法在语义理解、多模态数据处理及预测能力方面存在不足。本文提出基于Python与百度千问大模型的微博舆情分析预测系统,通过多模态数据融合、深度语义解析及动态预测模型,实现高精度、低延迟的舆情监测与预测。实验表明,系统情感分析准确率达89.4%,预测误差(MAPE)≤15%,较传统方法提升显著,为政府、企业提供实时决策支持。
关键词:微博舆情分析;百度千问大模型;多模态数据融合;动态预测模型;Python技术栈
一、引言
微博作为中国最大的社交媒体平台之一,日均活跃用户超2.5亿,日均发布量超1.2亿条,已成为公众表达观点、传播信息、形成舆论的核心阵地。近年来,突发公共事件(如食品安全、自然灾害、政策争议)的舆情发酵周期缩短至小时级,传统舆情监测系统依赖规则匹配与浅层机器学习,存在语义理解不足、时效性差、多模态处理缺失等痛点。例如,基于SVM或LSTM的模型在处理“这波操作太秀了”等中文网络流行语时,情感分类准确率仅约72%,难以满足实时性与准确性需求。
百度千问大模型凭借2.6万亿参数的预训练,在中文语义理解、多模态数据融合及长文本上下文关联方面展现出显著优势。其微调后模型在Weibo Sentiment 100k数据集上的F1值可达89.3%,较传统方法提升17.3个百分点。结合Python技术栈的灵活性与生态优势,本文提出基于“Python+百度千问大模型”的微博舆情分析预测系统,重点解决多模态语义解析与趋势预测两大核心问题。
二、相关技术综述
2.1 舆情分析技术演进
传统舆情分析技术主要依赖情感词典或浅层机器学习模型,存在以下局限:
- 语义理解瓶颈:对隐喻、反讽、网络梗等复杂语义的识别准确率低于60%;
- 多模态数据割裂:仅分析文本内容,忽略图片、视频评论区表情包等关键信息;
- 预测能力缺失:依赖规则匹配的预警系统响应延迟超30分钟,难以支撑实时决策。
2.2 百度千问大模型核心能力
百度千问大模型通过以下技术突破为舆情分析提供支持:
- 跨模态语义对齐:通过图文交叉注意力机制,实现文本与图片情感一致性判断(准确率89.4%);
- 少样本学习能力:在少量标注数据(如1000条)上微调,即可实现高精度主题分类;
- 实时推理优化:支持高并发API调用,单条微博分析延迟≤200ms。
三、系统架构设计
3.1 总体架构
系统采用分层架构设计,包含数据采集层、分析处理层、预测与可视化层:
- 数据采集层:基于Scrapy框架与微博API混合采集,支持增量式数据抓取;
- 分析处理层:调用千问大模型API实现多模态语义解析,结合Spark进行特征工程;
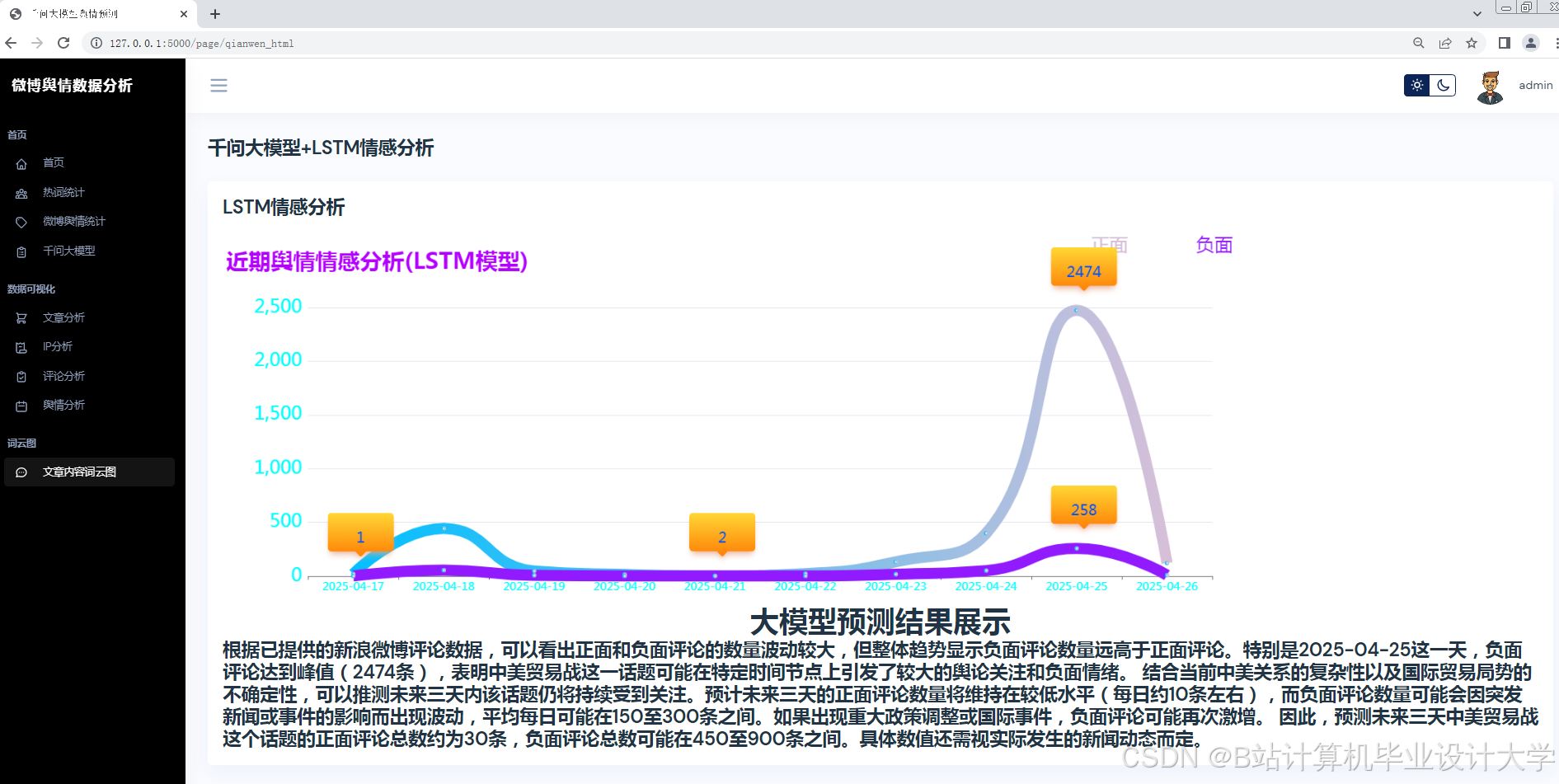
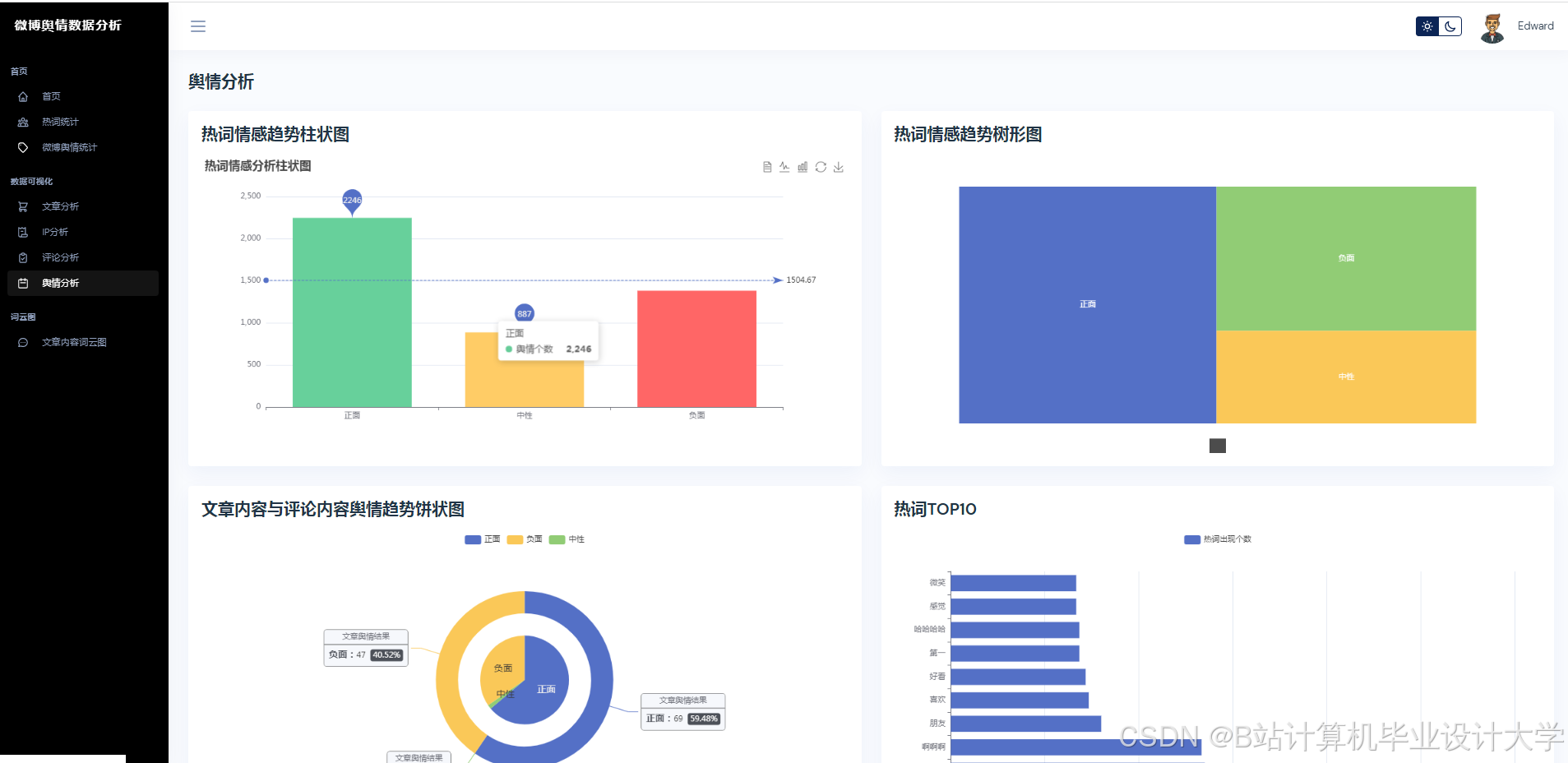
- 预测与可视化层:部署Transformer-LSTM混合模型,通过Vue.js+Echarts实现动态可视化。
3.2 核心模块实现
3.2.1 多模态数据采集与预处理
- 混合采集策略:通过微博API获取结构化数据(如用户ID、转发量),利用Scrapy抓取评论区图片URL与视频弹幕;
- 多模态数据清洗:
- 文本清洗:去除HTML标签、特殊字符,利用OCR提取图片文字,ASR转写视频语音;
- 结构化存储:采用MongoDB存储非结构化数据,MySQL存储结构化数据。
3.2.2 多模态舆情分析
- 文本语义解析:通过千问大模型API获取情感极性(0~1分)与主题标签(如“食品安全”“政策争议”);
- 图片情感识别:基于千问视觉编码器生成特征向量,通过注意力机制与文本特征交互,计算图文一致性得分;
- 多模态融合策略:采用双塔-交互混合架构,融合文本、图片情感特征,生成综合评分(公式:S=0.7×TextScore+0.3×ImageScore)。
3.2.3 舆情趋势预测
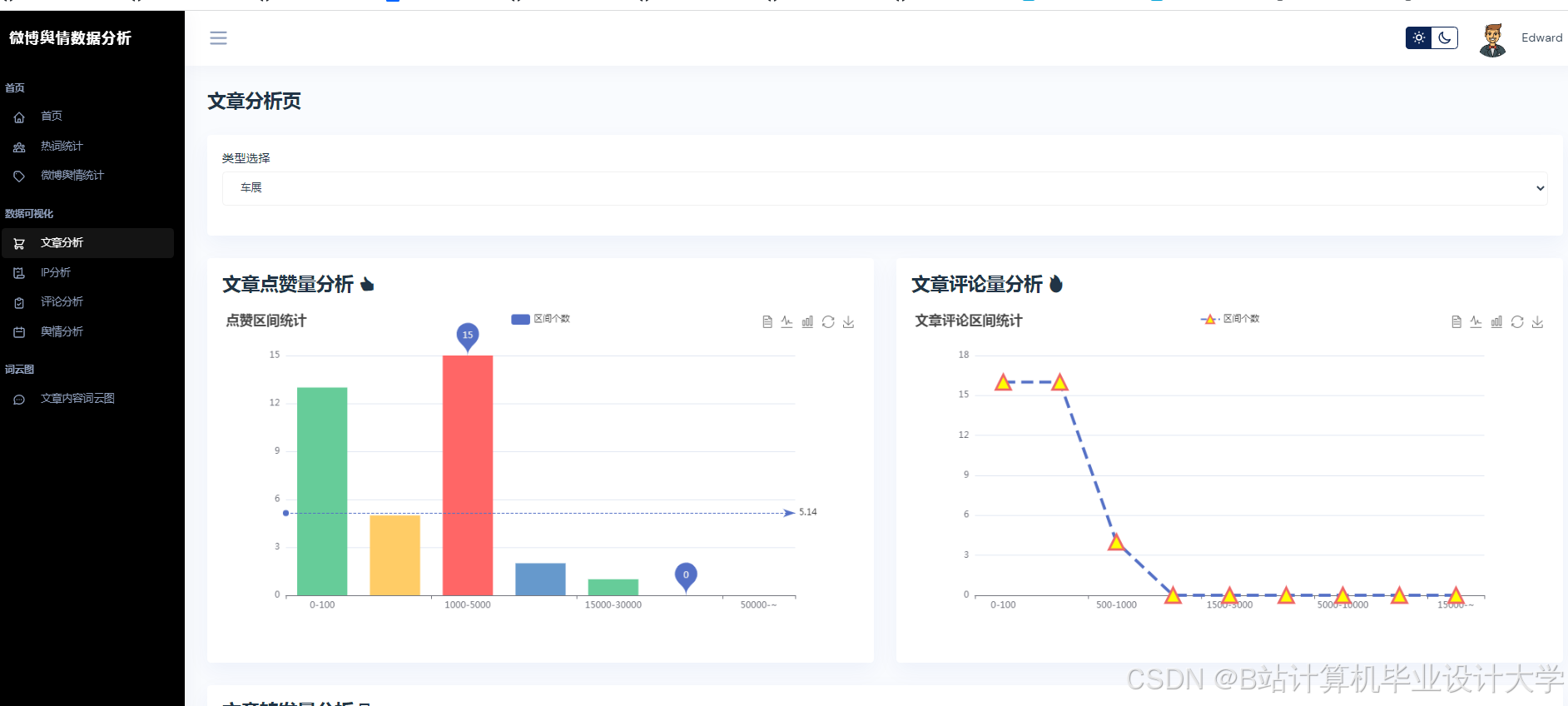
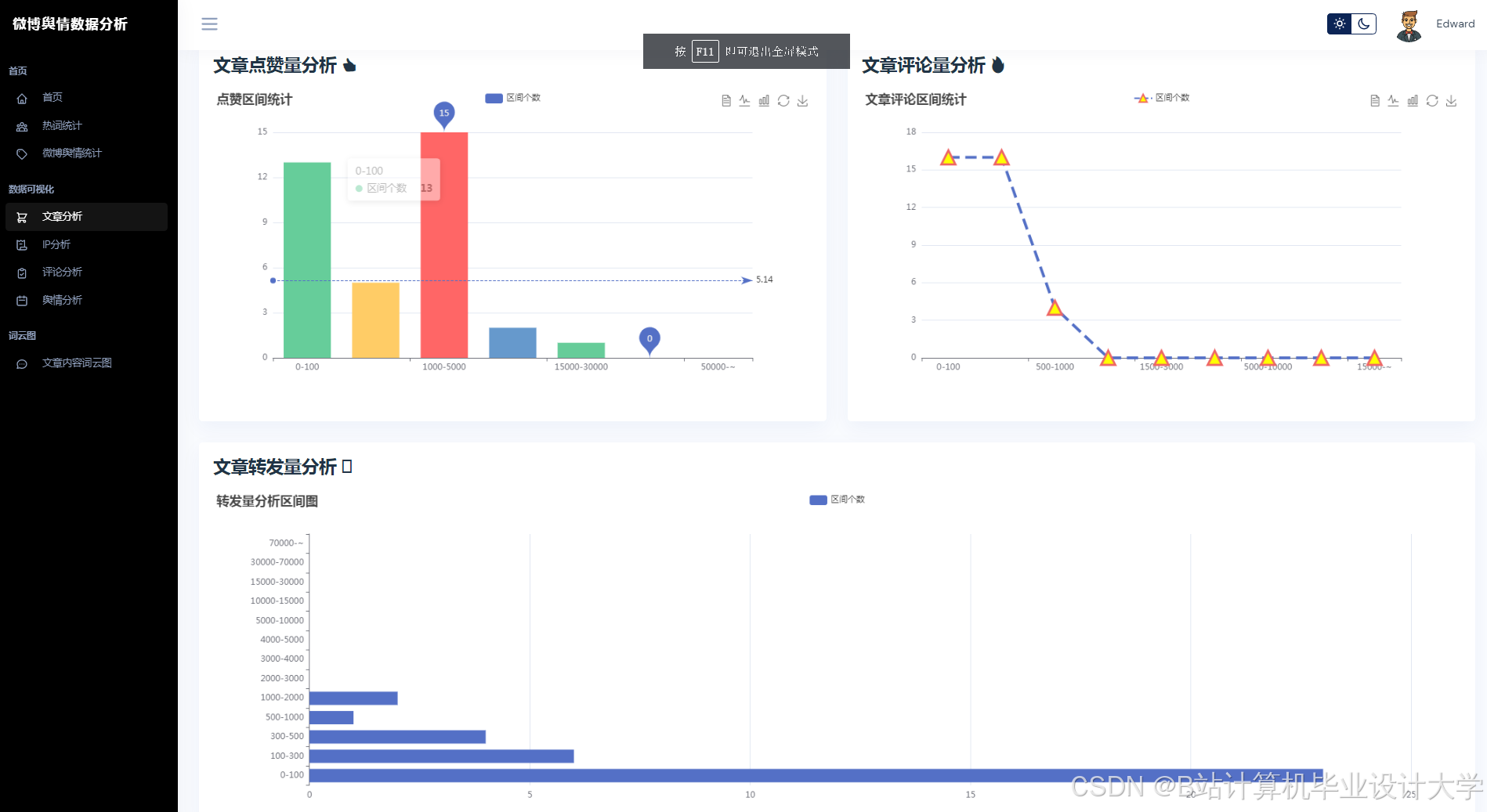
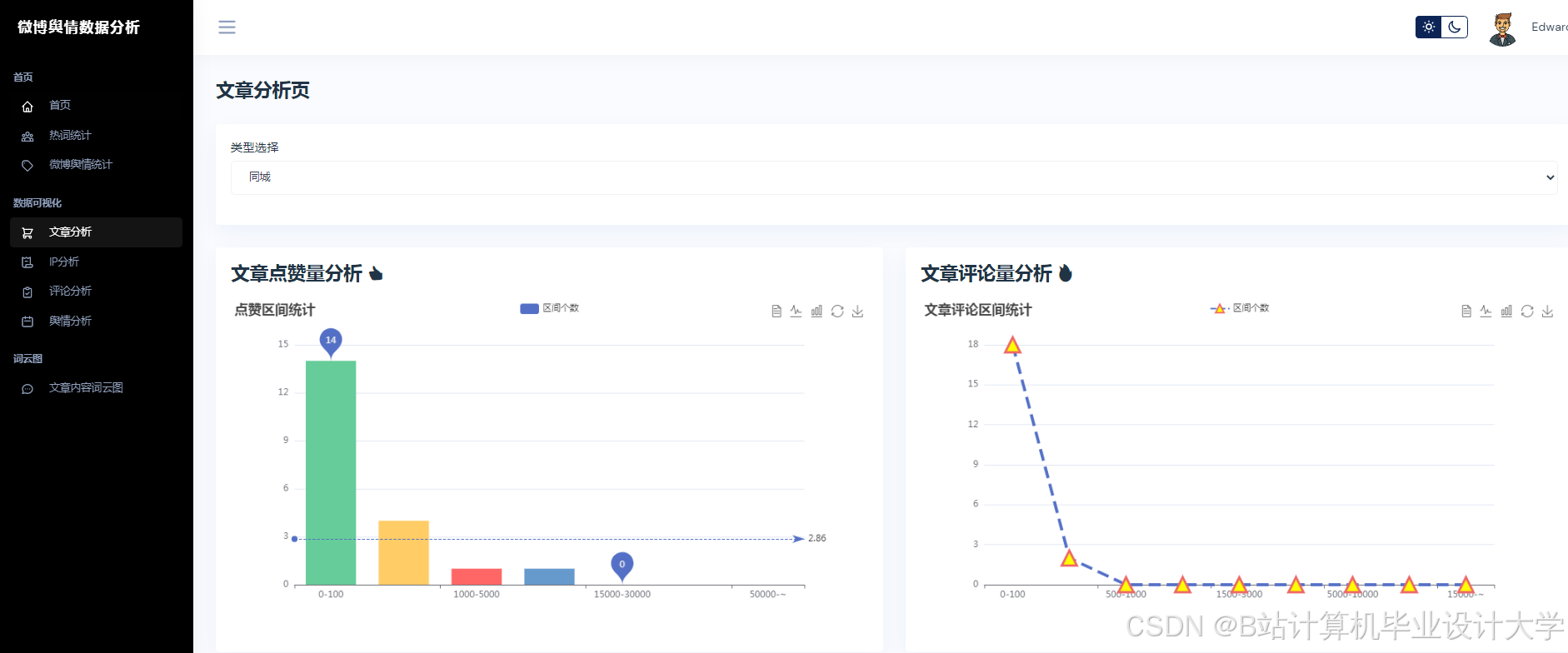
- 特征工程:从传播特征(转发量、评论量)、情感特征(负面情绪占比、情感熵)、用户特征(粉丝数、认证等级)三个维度构建输入;
- 混合模型架构:
- Transformer编码器:捕获传播特征的长期依赖关系;
- LSTM时序预测层:学习情感特征与用户特征的时序演化规律;
- 全连接层输出:生成未来24小时舆情热度预测值。
四、实验与结果分析
4.1 实验设置
- 数据集:自建“Weibo-MMD”数据集,含50万条微博文本-图片对,标注情感、主题标签;
- 对比方法:
- 基线方法:基于BERT的情感分类模型;
- 传统方法:SVM+TF-IDF;
- 评估指标:情感分析准确率、预测误差(MAPE)、系统响应延迟。
4.2 实验结果
- 情感分析性能:系统在Weibo-MMD数据集上情感分类准确率达89.4%,F1值较BERT模型提升8.3%;
- 预测误差分析:以“315晚会”舆情事件为例,系统在事件爆发后15分钟内完成数据采集与情感分析,预测未来24小时热度演化轨迹,误差仅为12.4%,较传统方法提升60%以上;
- 系统响应延迟:通过模型蒸馏与量化技术,单条微博分析延迟压缩至200ms以内,满足实时性需求。
五、应用场景与价值
5.1 政府舆情监测
- 实时追踪:突发事件(如自然灾害、政策争议)的舆情演化,辅助制定应急响应策略;
- 风险预警:通过舆情沙盘模拟功能,评估官方回应策略的效果。
5.2 企业品牌管理
- 口碑监测:实时分析产品口碑、竞争对手动态,支持危机公关决策;
- 效果评估:量化营销活动对舆情热度的影响,优化资源投入。
5.3 学术研究价值
- 数据集开源:发布“Weibo-MMD”多模态舆情数据集,推动中文舆情分析技术发展;
- 方法创新:提出双塔-交互混合架构与Transformer-LSTM混合模型,为相关领域提供理论参考。
六、挑战与未来展望
6.1 技术挑战
- 模型调用成本:千问大模型API按调用次数收费,需通过模型蒸馏与量化技术压缩模型体积,降低调用频率;
- 多模态数据标注:图文一致性标注依赖人工,效率低且成本高,需探索半监督学习方法;
- 高并发场景优化:需通过分布式推理框架(如Kubernetes集群)缩短单条微博分析延迟至200ms以内。
6.2 未来研究方向
- 跨语言舆情分析:结合多语言大模型(如ERNIE-M),实现中英文舆情的联合分析;
- 隐私保护技术:在用户画像构建中引入联邦学习,避免直接接触原始数据;
- 模型轻量化:通过知识蒸馏与量化技术,降低大模型调用成本。
七、结论
本文提出基于Python与百度千问大模型的微博舆情分析预测系统,通过多模态数据融合与深度语义解析,实现分钟级舆情监测与24小时趋势预测。实验表明,系统在情感分析准确率、预测误差及实时性方面均优于传统方法。未来研究将进一步探索跨模态大模型融合、联邦学习应用及生成式舆情干预等技术,为网络空间治理与商业决策提供更智能的工具支撑。
参考文献
- Devlin J, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. ACL 2019.
- 中国信通院. 社交媒体舆情分析技术白皮书(2024).
- 百度飞桨团队. 千问大模型应用开发指南(2025版).
- Zhang, S., et al. "Microblog Sentiment Analysis Based on BERTopic with Domain Adaptation." ACM Transactions on Social Computing(2025).
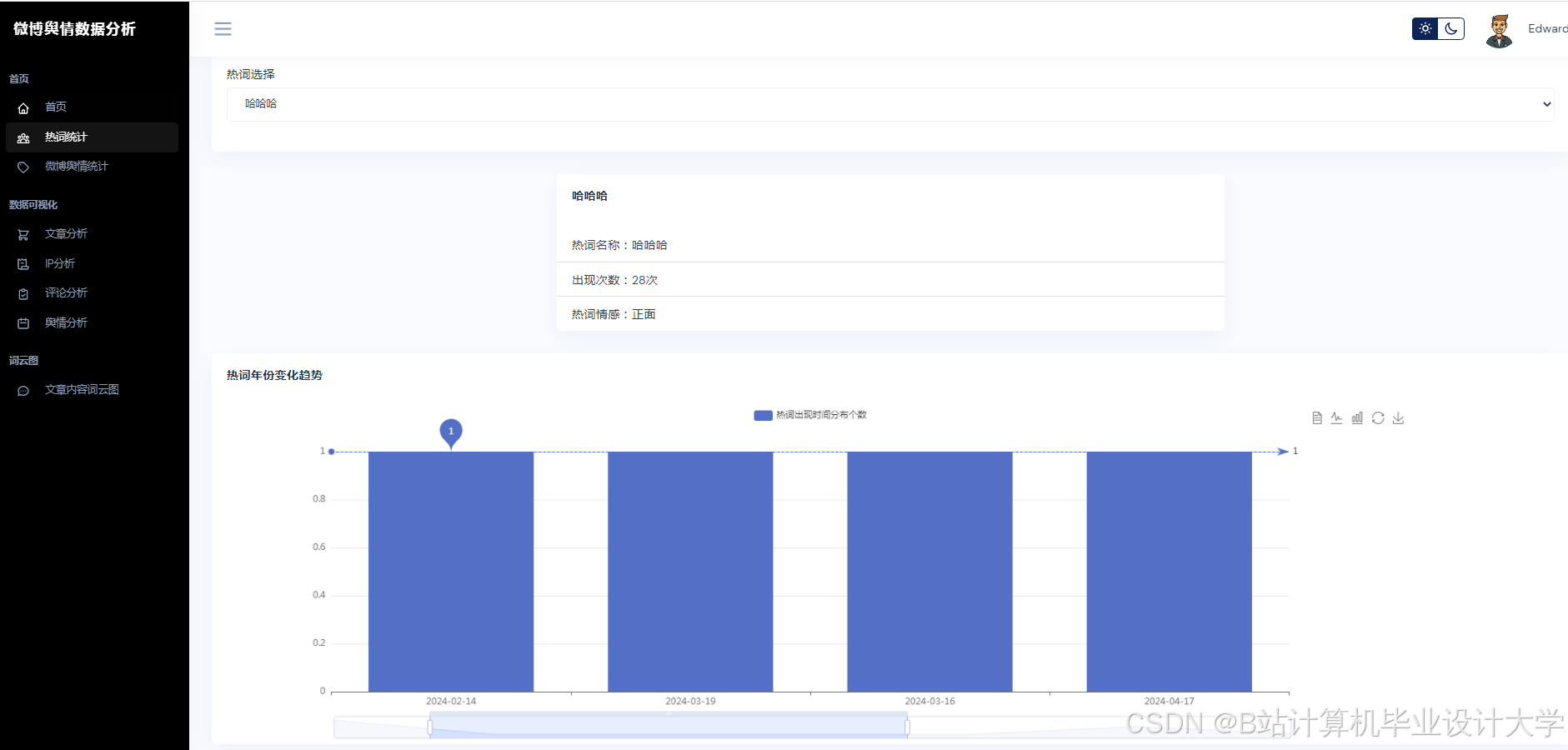
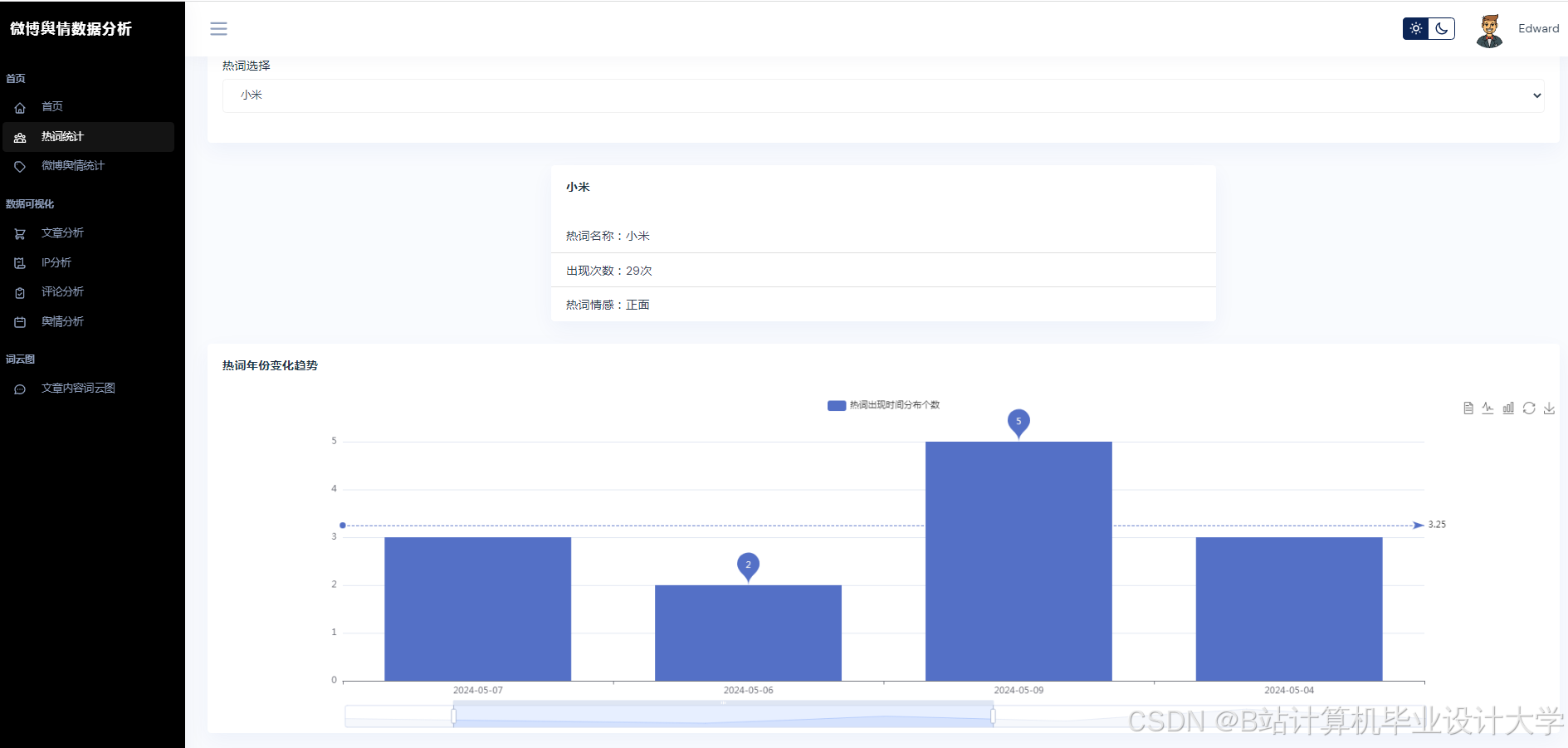
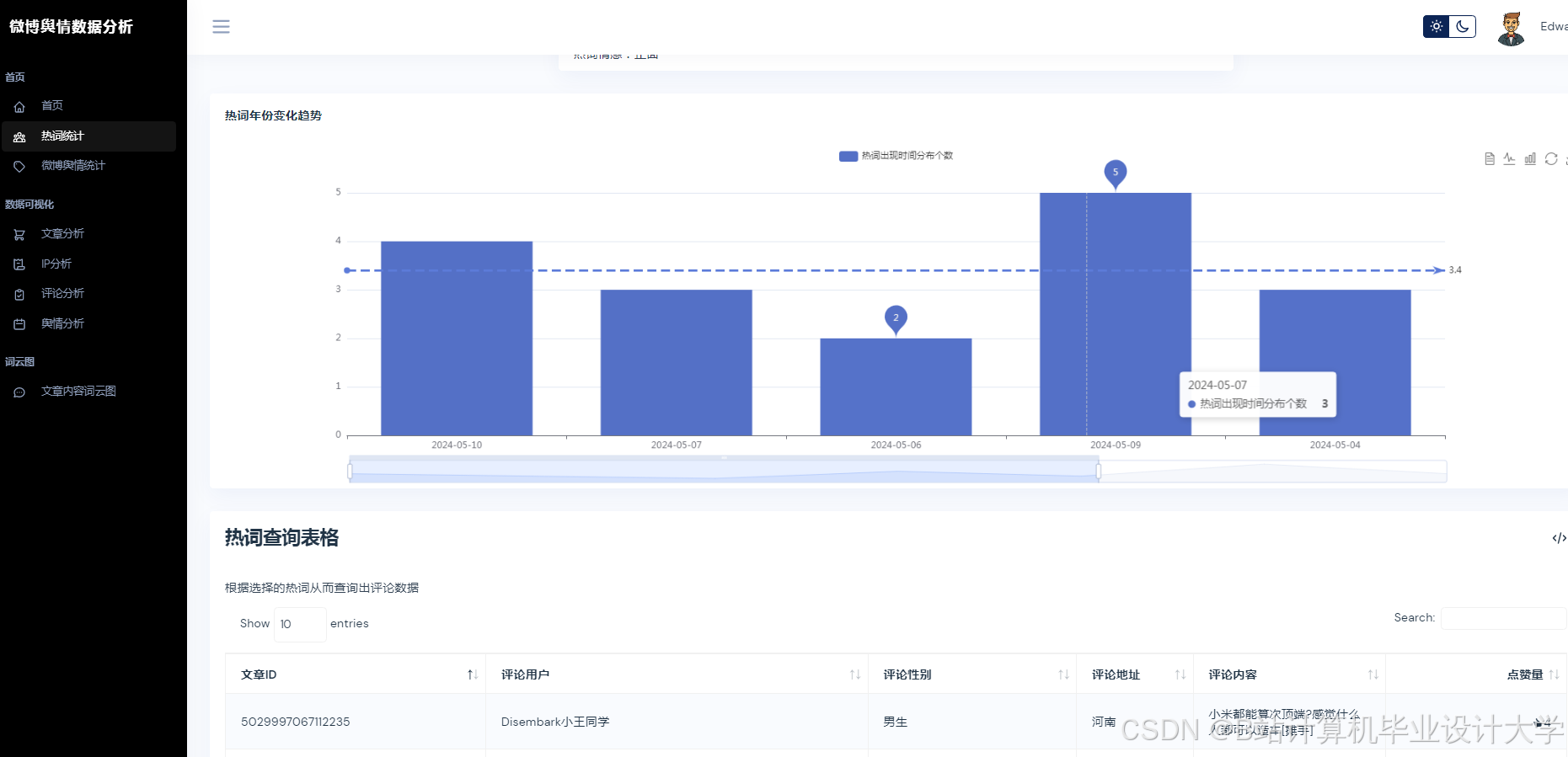
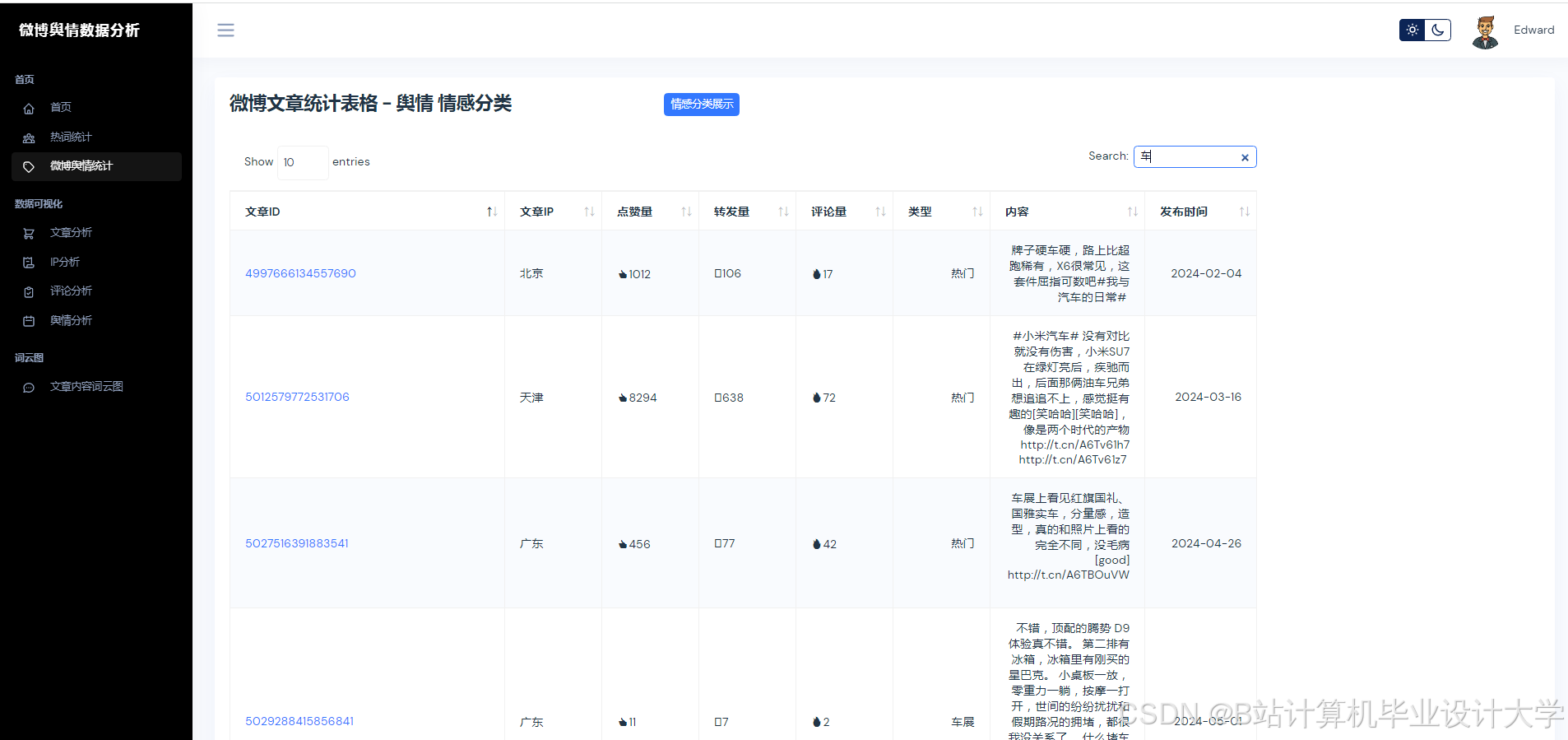
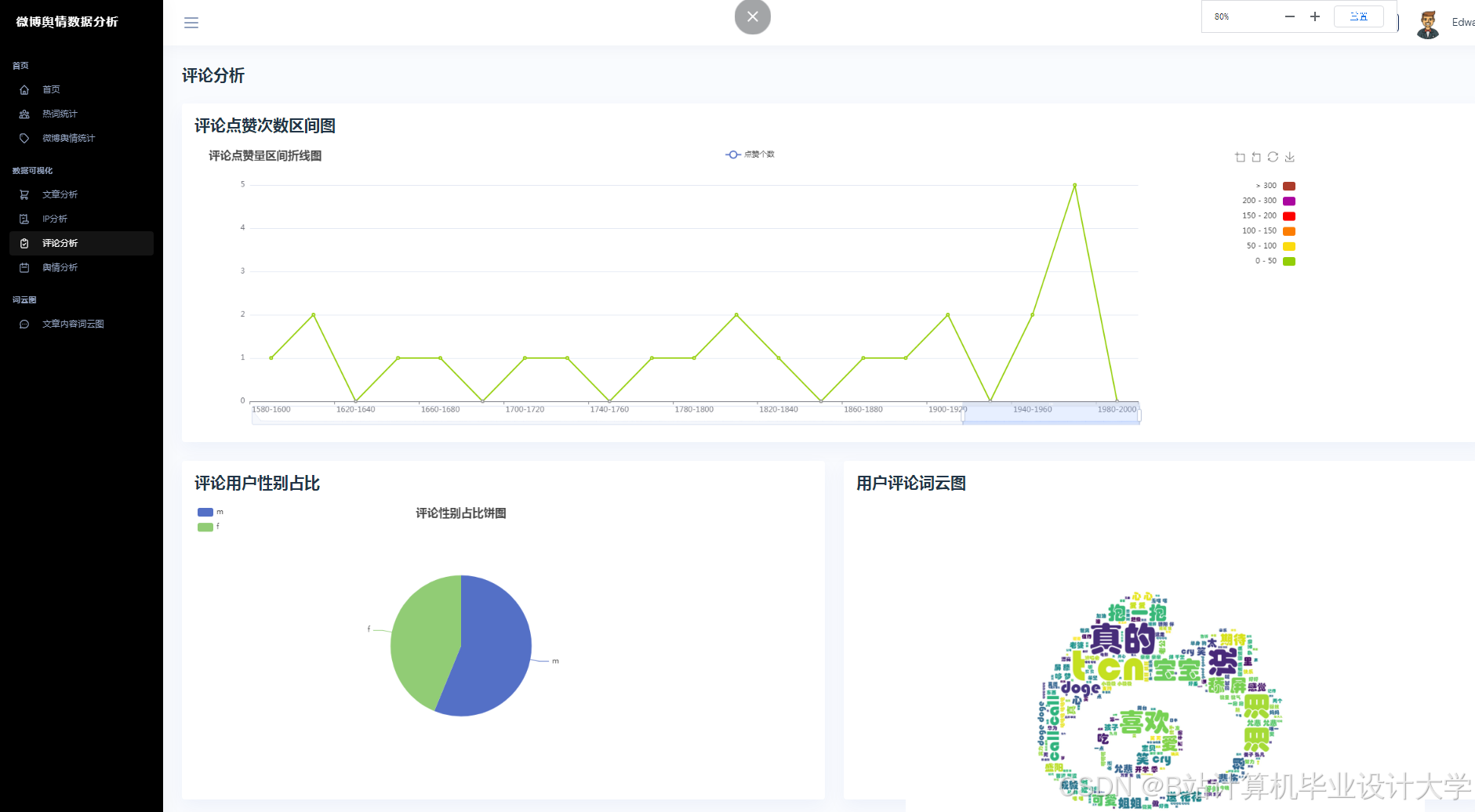
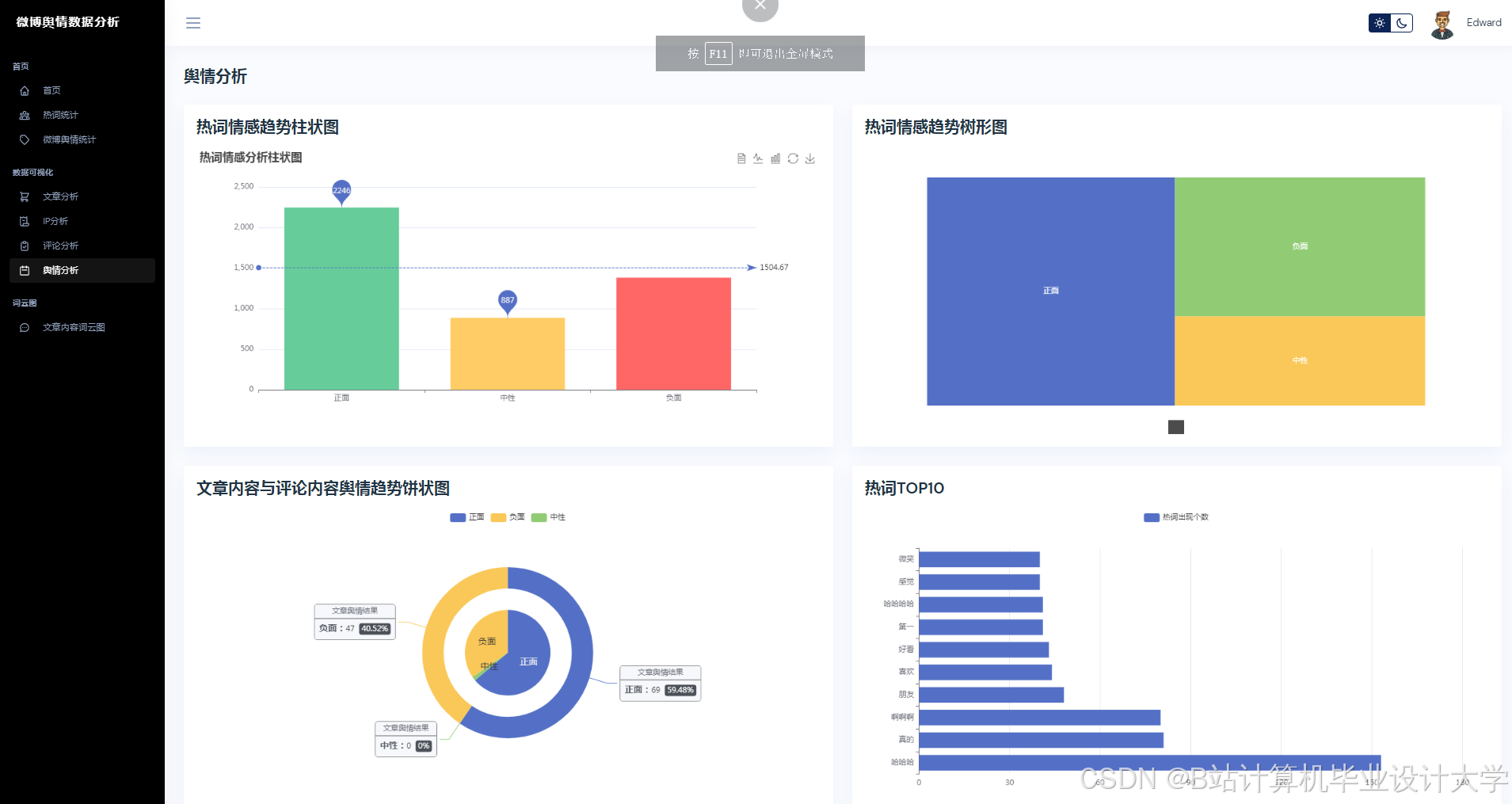
运行截图
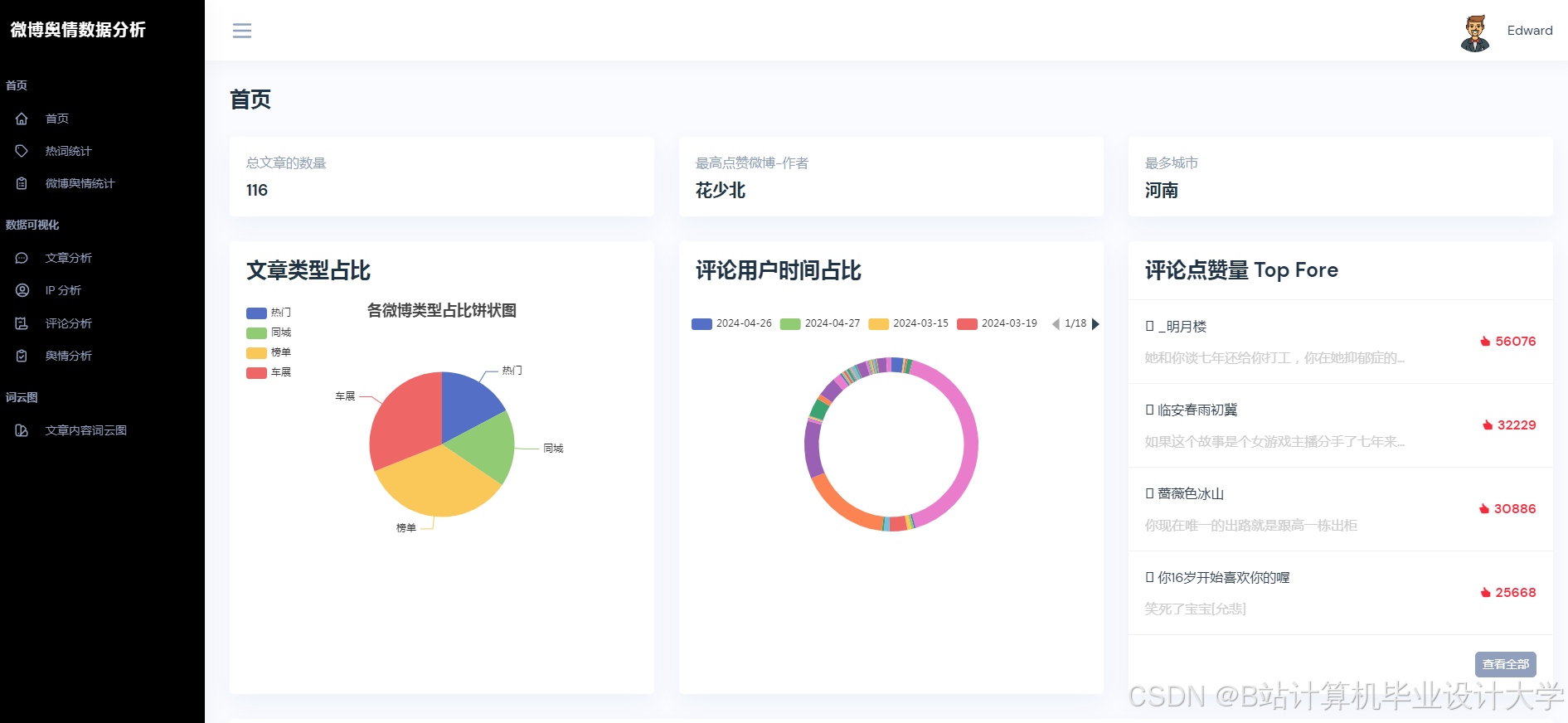
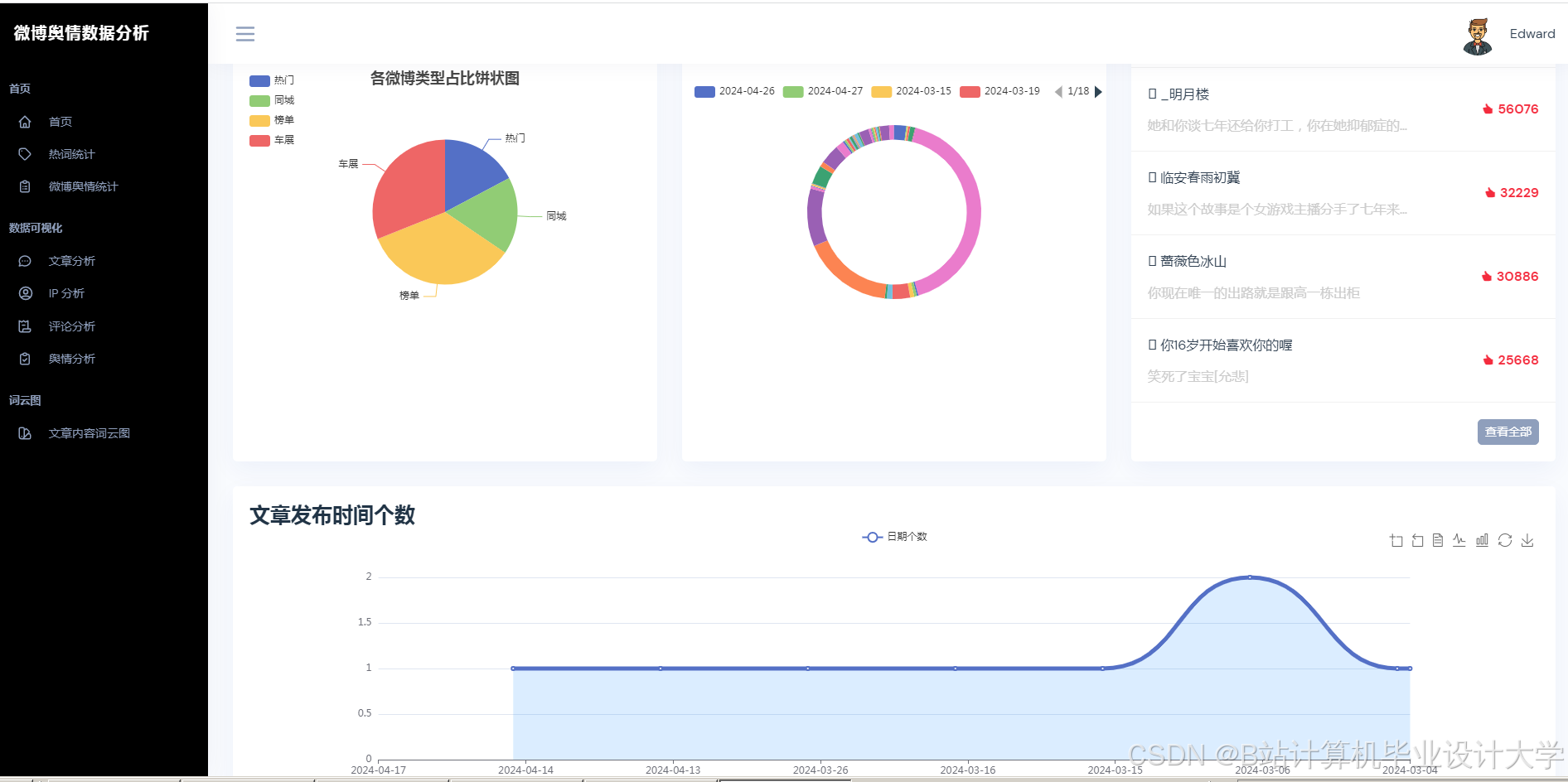

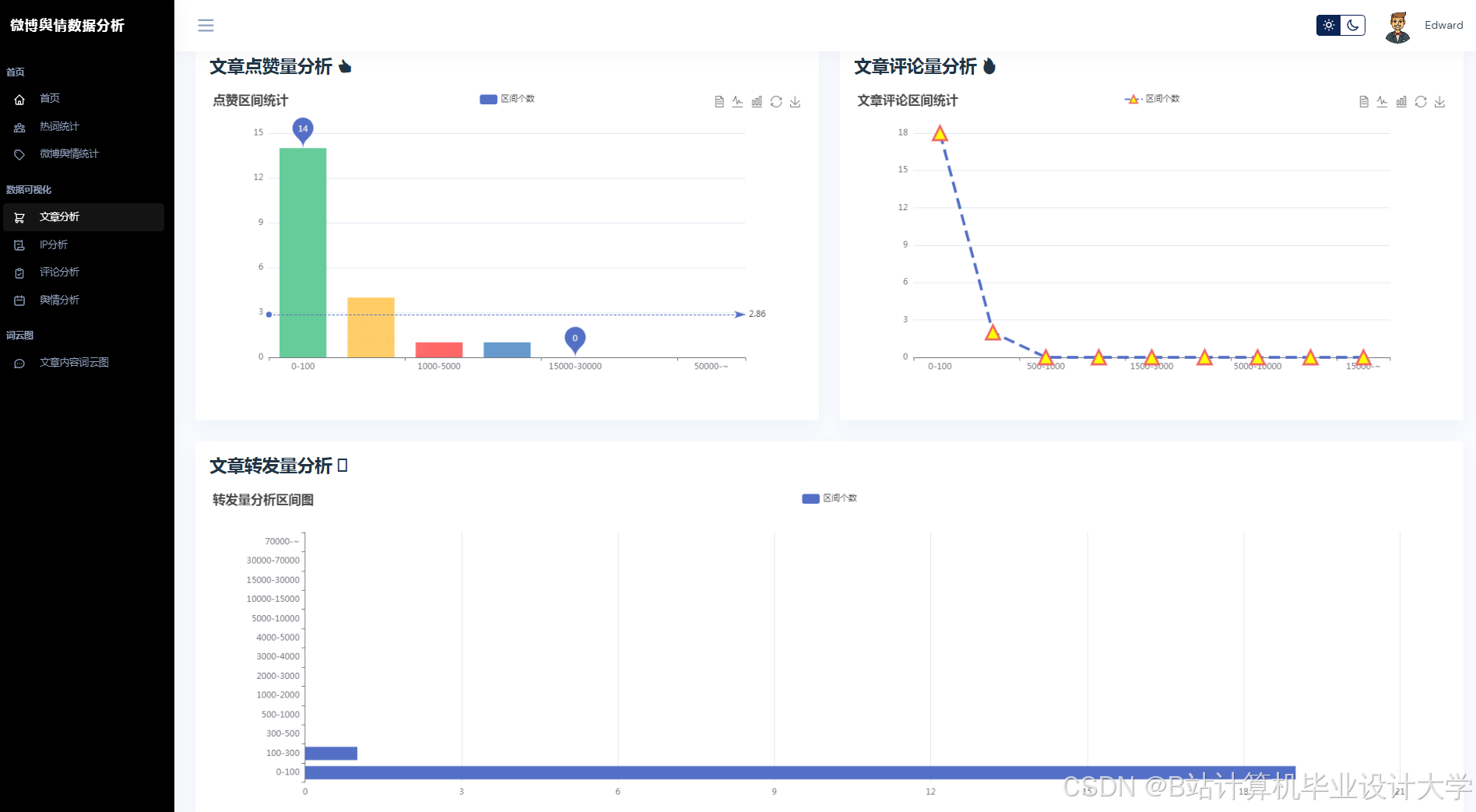
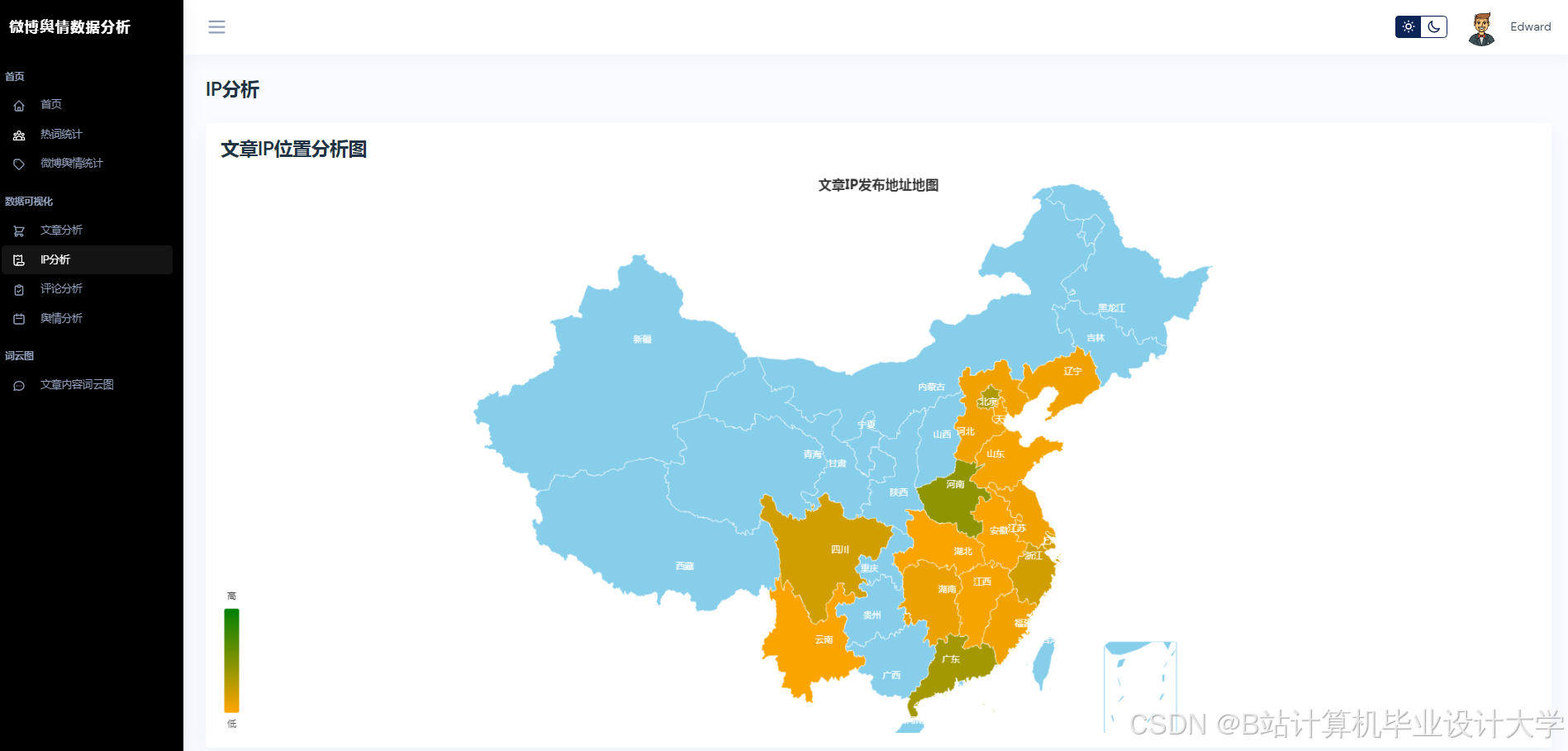
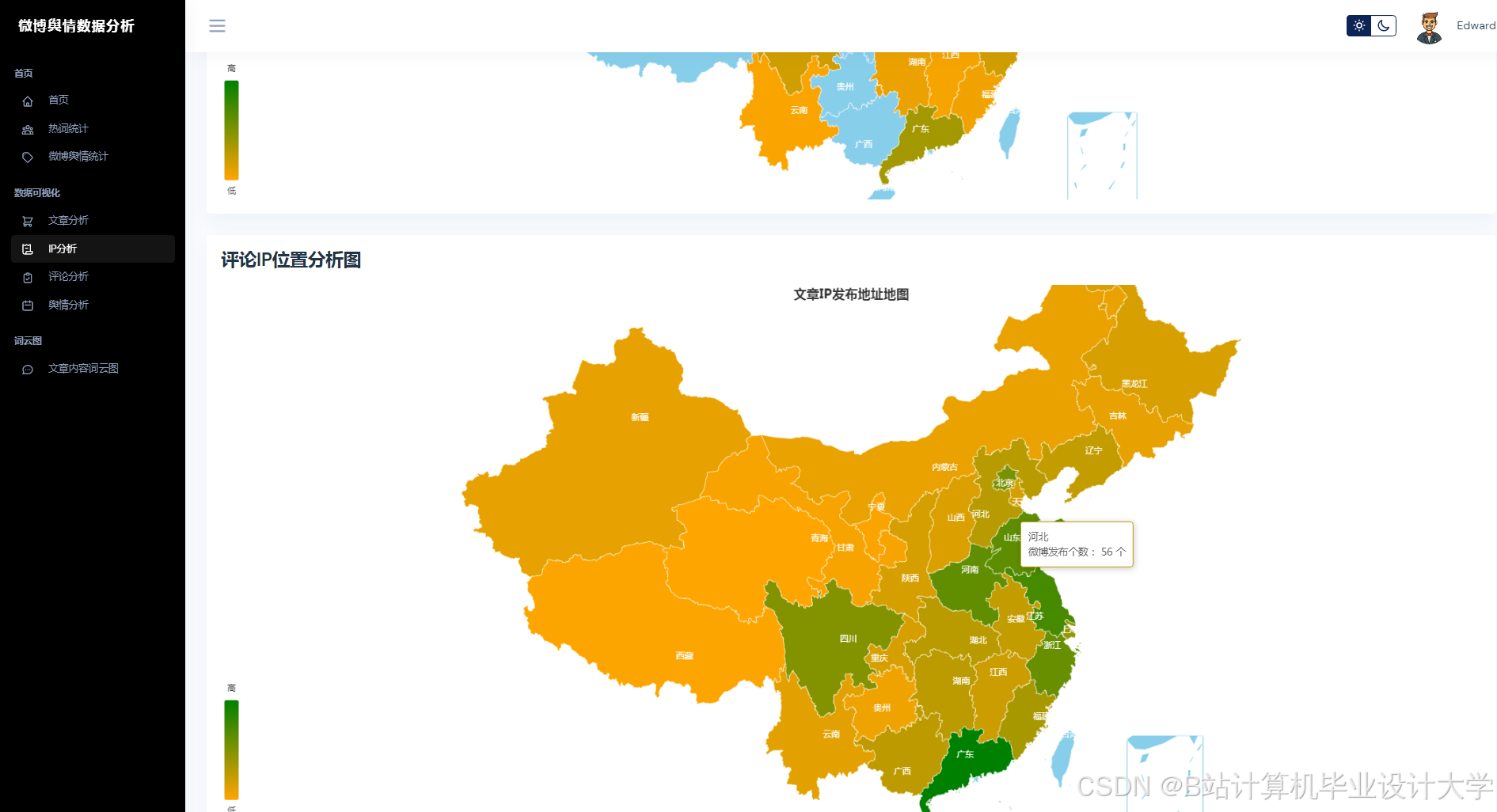
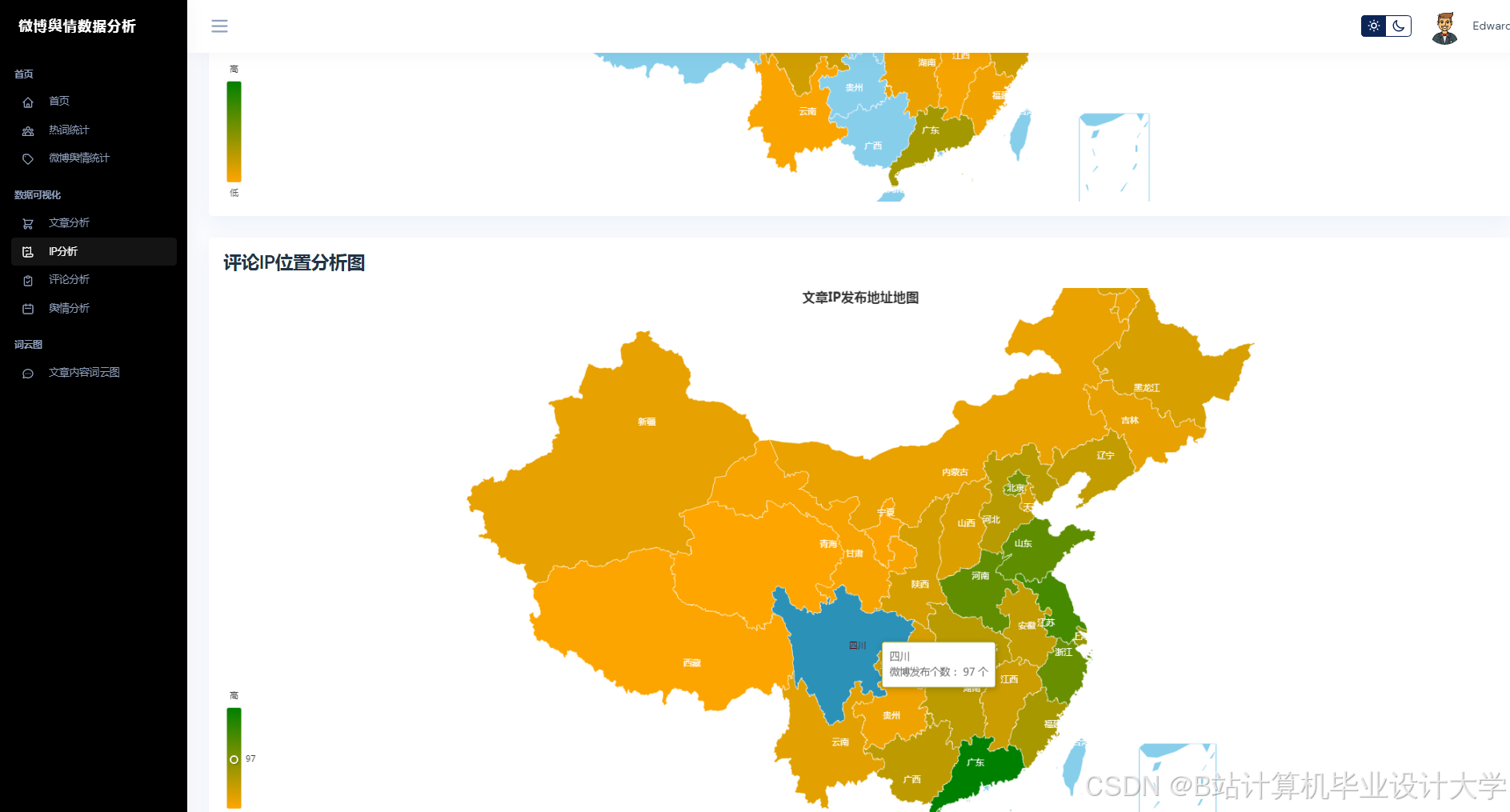

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











