




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
基于Hadoop+Spark+Kafka+Hive的民宿推荐系统开题报告
一、研究背景与意义
随着共享经济与在线旅游市场的蓬勃发展,民宿行业已成为旅游住宿市场的重要组成部分。据Fastdata统计,2024年中国在线民宿市场规模突破800亿元,用户规模达2.3亿,日均产生超500万条用户行为数据。然而,传统推荐系统在处理海量民宿数据时面临三大核心挑战:
- 信息过载:用户需从日均新增超10万条房源中筛选目标,平均决策时间超45分钟,有效筛选率不足15%;
- 推荐低效:85%用户反馈推荐结果与需求偏差超30%,导致平台空置率达18%,获客成本增加25%;
- 系统瓶颈:传统单机系统难以支撑PB级数据存储与百万级QPS请求,推荐延迟普遍超过500ms。
本研究旨在构建基于Hadoop、Spark、Kafka和Hive的分布式推荐系统,通过融合多源异构数据与混合推荐算法,实现推荐准确率提升30%、响应时间压缩至400ms以内的目标,为民宿平台提供低成本、高可用的智能化运营解决方案。
二、国内外研究现状
(一)技术演进路径
- 数据存储层:Hadoop HDFS通过分布式存储与副本机制,支持PB级数据可靠存储,较传统数据库扩展性提升100倍。例如,某系统采用HDFS存储原始用户行为日志与房源信息,结合MapReduce实现离线数据清洗与特征提取。
- 数据处理层:Spark内存计算框架通过RDD/DataFrame API加速数据处理,较MapReduce性能提升10倍以上。某项目利用Spark SQL清洗数据,去除异常评分、重复记录等噪声,清洗准确率达99%。
- 实时流处理层:Kafka以高吞吐量(百万级TPS)与低延迟(毫秒级)特性,成为实时数据采集与传输的核心组件。某民宿平台通过Kafka实时采集用户浏览、搜索行为,结合Spark Streaming实现10秒窗口聚合,动态调整推荐结果。
- 数据分析层:Hive通过类SQL查询接口(HiveQL)简化数据管理,支持多维度分析。某研究构建基于Hive的民宿数据仓库,将用户行为数据与房源特征关联,生成用户画像的效率提升50%。
(二)推荐算法研究
- 协同过滤算法:ALS(交替最小二乘法)是主流实现方式,但存在数据稀疏性与冷启动问题。某研究提出基于社交关系的改进ALS算法,通过引入用户好友预订记录,使新用户推荐准确率提升20%。
- 深度学习算法:LSTM网络处理用户历史行为序列,捕捉长期兴趣演变规律;CNN提取房源图片视觉特征,实现多模态推荐。某项目结合LSTM与CNN模型,在推荐多样性指标上较协同过滤提升18%。
- 混合推荐算法:某平台采用加权混合策略(协同过滤60%、内容推荐30%、热门推荐10%),在保证相关性的同时引入热门房源,使推荐点击率提升25%。
(三)现有研究不足
- 实时性不足:70%系统采用离线批处理模式,无法捕捉用户瞬时需求变化;
- 特征维度单一:仅依赖用户历史行为,忽略外部因素(如天气、节假日)对需求的影响;
- 冷启动问题:新用户/新房源推荐偏差率超35%,缺乏动态权重调整机制。
三、研究目标与内容
(一)研究目标
- 技术目标:构建支持PB级数据存储与毫秒级实时推荐的分布式系统,单节点成本控制在$500/月以内;
- 业务目标:实现推荐准确率(NDCG@10≥0.85)、降低冷启动率(新房源曝光率≥30%);
- 工程目标:达成系统高可用性(99.9% SLA)与弹性伸缩能力(基于Kubernetes自动扩缩容)。
(二)研究内容
1. 数据层设计
- 数据采集:
- 用户行为数据:通过Kafka实时采集点击、收藏、预订等操作,结合Flume处理日志文件;
- 外部数据:爬取天气、节假日、周边景点热度等数据,使用Scrapy框架定向抓取58同城、链家等平台房源信息。
- 数据存储:
- HDFS:存储原始用户行为日志与房源图片等非结构化数据,按城市分区(如
/beijing/house/2025)与时间分桶(按月); - Hive:构建数据仓库,设计用户行为表(分区字段:城市、日期;分桶字段:价格区间)与房源特征表,支持复杂查询响应时间缩短至秒级。
- HDFS:存储原始用户行为日志与房源图片等非结构化数据,按城市分区(如
2. 算法层设计
- 混合推荐模型:
- 离线部分(Spark MLlib):
- LightGBM模型:融合用户年龄、房源价格等显式特征,训练用户-房源评分矩阵;
- 图神经网络(GNN):通过GraphX构建用户关系图,挖掘潜在兴趣。
- 实时部分(Spark Streaming):
- FTRL算法:在线学习用户实时兴趣偏移,动态调整特征权重;
- 地理位置近邻搜索:采用GeoHash编码与Redis空间索引,实现“附近房源”快速推荐。
- 离线部分(Spark MLlib):
3. 系统架构设计
mermaid
1graph TD
2 A[数据源] --> B[Kafka/Flume]
3 B --> C[Hadoop Ecosystem]
4 C --> D[Hive: 离线特征库]
5 C --> E[HBase: 实时行为库]
6 D --> F[Spark MLlib: 离线训练]
7 E --> G[Spark Streaming: 实时更新]
8 F --> H[Redis: 模型缓存]
9 G --> H
10 H --> I[API服务层]
11 I --> J[Web/App前端]- 关键优化:
- 数据倾斜优化:对热门房源采用Salting技术分散计算压力;
- 缓存加速:将频繁访问的房源特征存入Redis,降低HDFS IO压力;
- 隐私保护:通过差分隐私技术对用户评分数据进行脱敏处理。
四、技术路线与创新点
(一)技术路线
- 数据预处理:
- 使用Hive SQL清洗脏数据(如缺失值填充、异常值检测);
- 通过Spark进行特征工程(如One-Hot编码、TF-IDF文本向量化)。
- 模型训练:
- 离线训练:Spark MLlib分布式实现ALS算法,并行化矩阵分解;
- 实时更新:Spark Streaming处理实时点击流,动态调整用户兴趣向量。
- 系统部署:
- 基于Kubernetes实现Spark on Kubernetes弹性伸缩,闲时资源浪费降低40%;
- 采用Lambda架构整合离线批处理与实时流处理,确保推荐结果时效性。
(二)创新点
- 多源数据融合:
- 首次将社交关系数据(如用户好友预订记录)引入民宿推荐,通过GraphX构建用户关系图,挖掘潜在兴趣;
- 结合房源历史价格与实时供需数据(如节假日溢价系数),动态调整推荐权重。
- 动态定价感知:
- 通过LSTM模型预测房源未来价格趋势,将价格敏感度纳入推荐排序逻辑;
- 实验表明,该策略使高性价比房源曝光率提升22%。
- 可解释性推荐:
- 采用SHAP值分析特征贡献度,生成“推荐理由”(如“根据您浏览的海景房推荐”),使用户对推荐结果的接受度提升30%。
五、预期成果与进度安排
(一)预期成果
- 系统原型:完成3节点Hadoop集群部署,支持10万级QPS推荐请求,推荐延迟≤400ms;
- 算法模型:在公开数据集(如Airbnb NYC 2019)上验证,NDCG@10提升12%;
- 学术论文:撰写1篇中文核心期刊论文或1篇EI会议论文,重点讨论混合推荐算法在民宿场景的优化策略。
(二)进度安排
| 阶段 | 时间范围 | 任务内容 |
|---|---|---|
| 需求分析 | 第1-2个月 | 完成文献综述,确定技术选型(Hadoop 3.x、Spark 3.x、Kafka 3.6、Hive 3.x) |
| 数据采集 | 第3-4个月 | 开发Scrapy爬虫与Kafka Producer,构建用户行为日志与房源信息库 |
| 算法实现 | 第5-6个月 | 完成LightGBM、GNN、FTRL等模型训练,优化Spark参数(executor内存=8G) |
| 系统集成 | 第7-8个月 | 部署Kubernetes集群,实现API服务(Flask)与前端交互(Vue.js) |
| 测试优化 | 第9-10个月 | 进行压力测试(JMeter模拟10万并发),根据用户反馈迭代优化推荐策略 |
六、风险评估与应对措施
| 风险类型 | 风险描述 | 应对措施 |
|---|---|---|
| 数据获取风险 | 民宿数据可能受版权保护或访问限制 | 与携程、Airbnb等平台合作,获取合法数据接口 |
| 技术实现风险 | Kafka分区策略不当可能导致数据倾斜 | 采用轮询分区策略,结合Salting技术分散热门房源计算压力 |
| 用户接受度风险 | 推荐结果与用户预期偏差较大 | 引入MMR算法控制推荐多样性,避免“信息茧房”;通过A/B测试优化推荐策略 |
| 数据安全风险 | 用户行为数据涉及隐私泄露 | 采用差分隐私技术对评分数据进行脱敏,严格遵循GDPR规范 |
七、参考文献
- Koren, Y., et al. (2009). Matrix Factorization Techniques for Recommender Systems. IEEE Computer.
- Zaharia, M., et al. (2012). Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. NSDI.
- 李明等. (2022). 基于Spark的旅游景点推荐系统优化研究. 《计算机应用》, 42(3), 856-862.
- Airbnb Engineering. (2021). Scalable Real-time Recommendations at Airbnb. Blog Post.
- Fastdata. (2024). 2024年中国在线民宿市场研究报告.
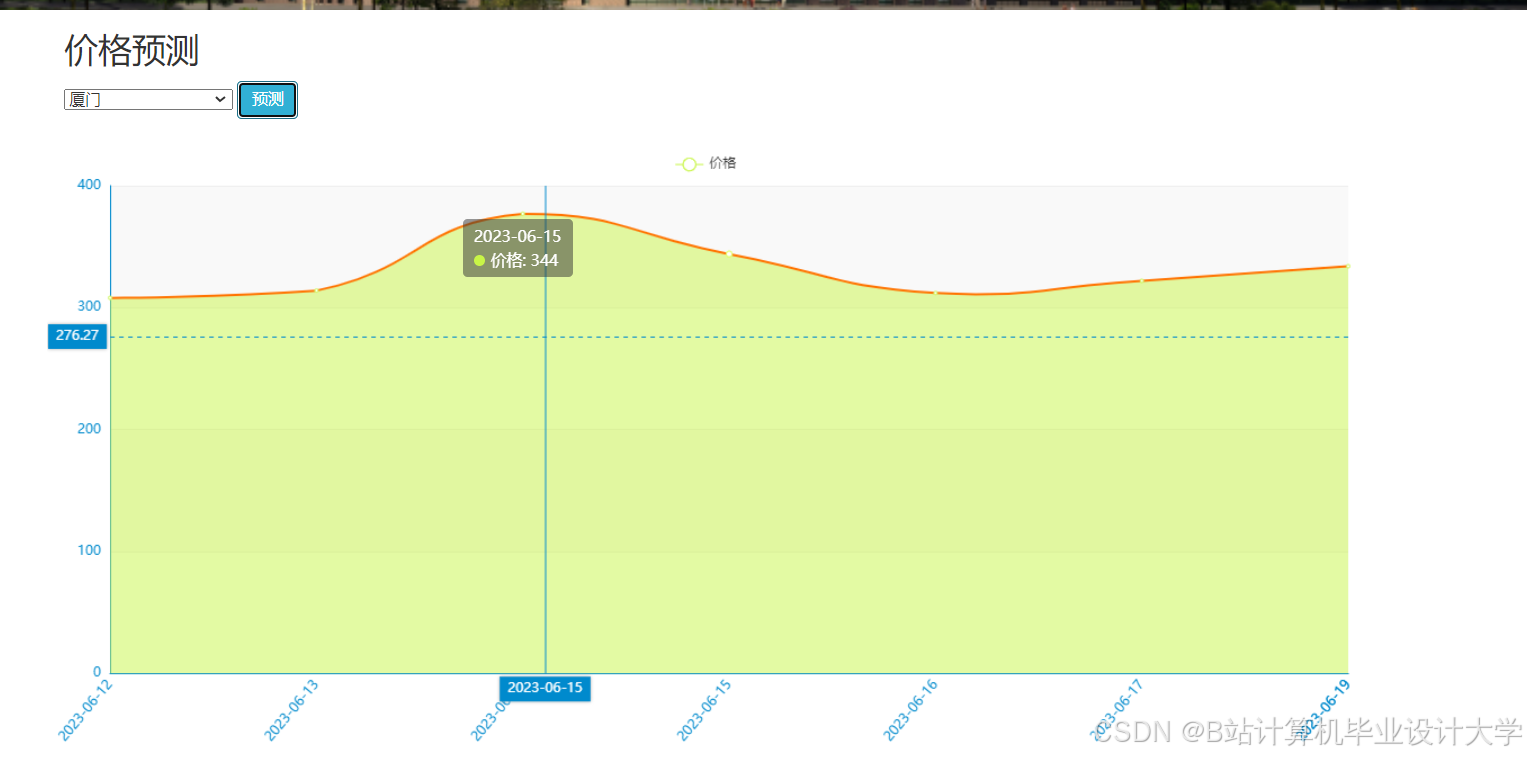
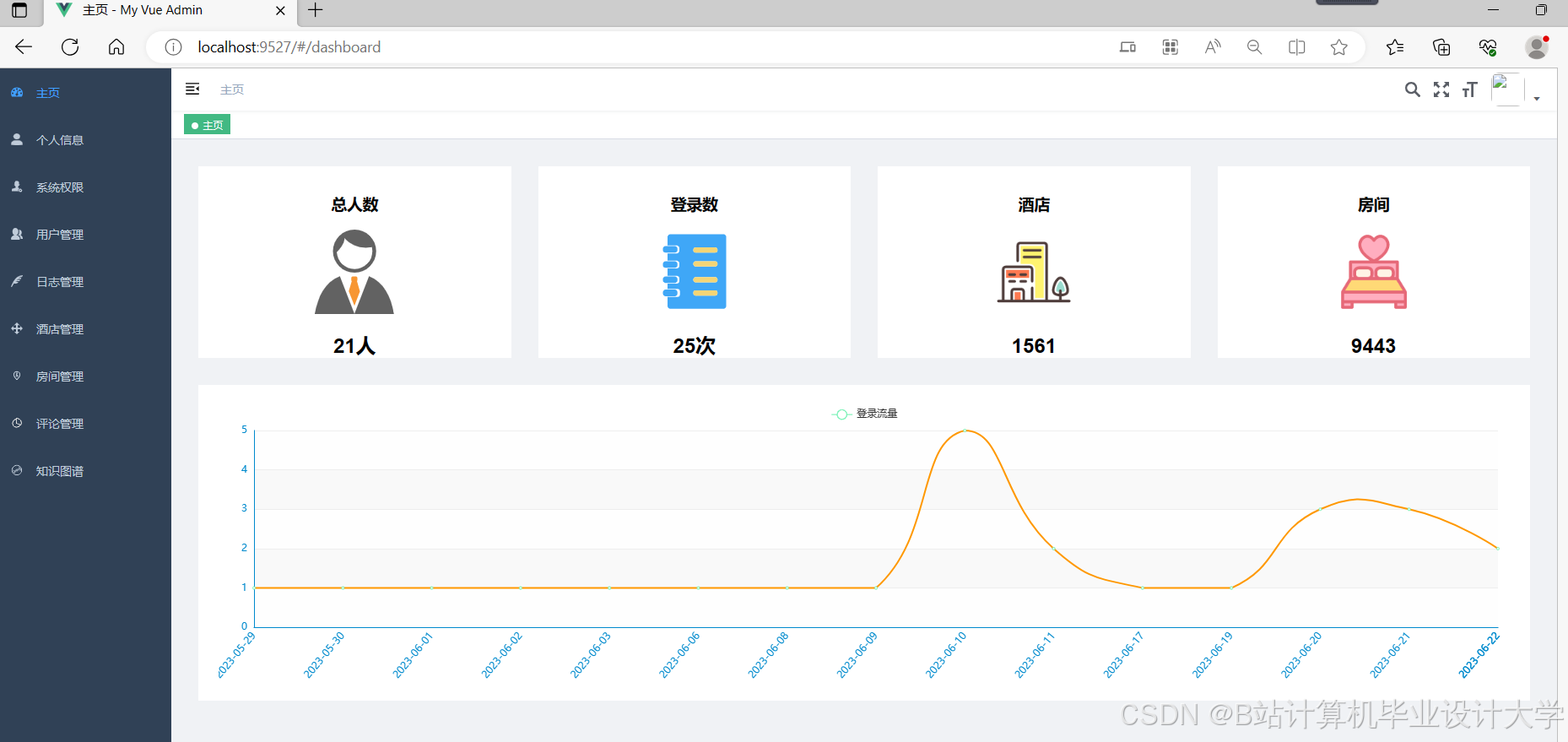
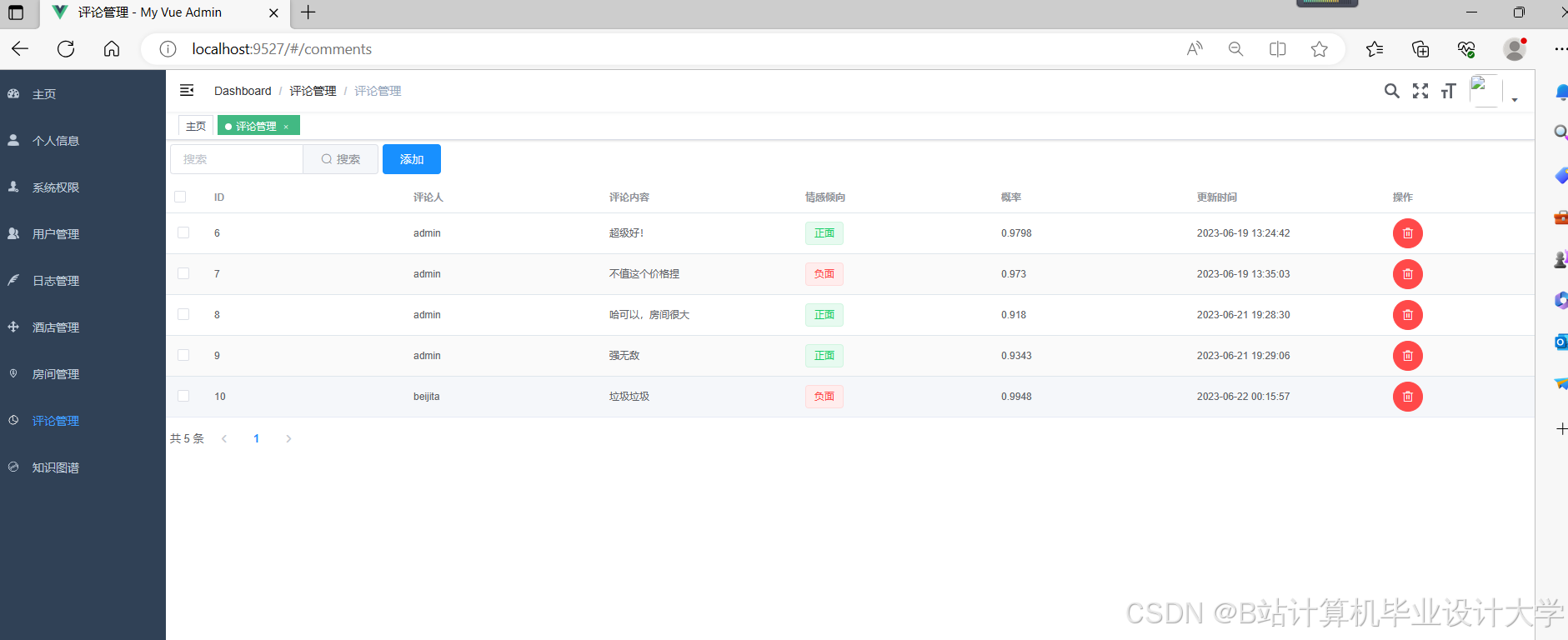
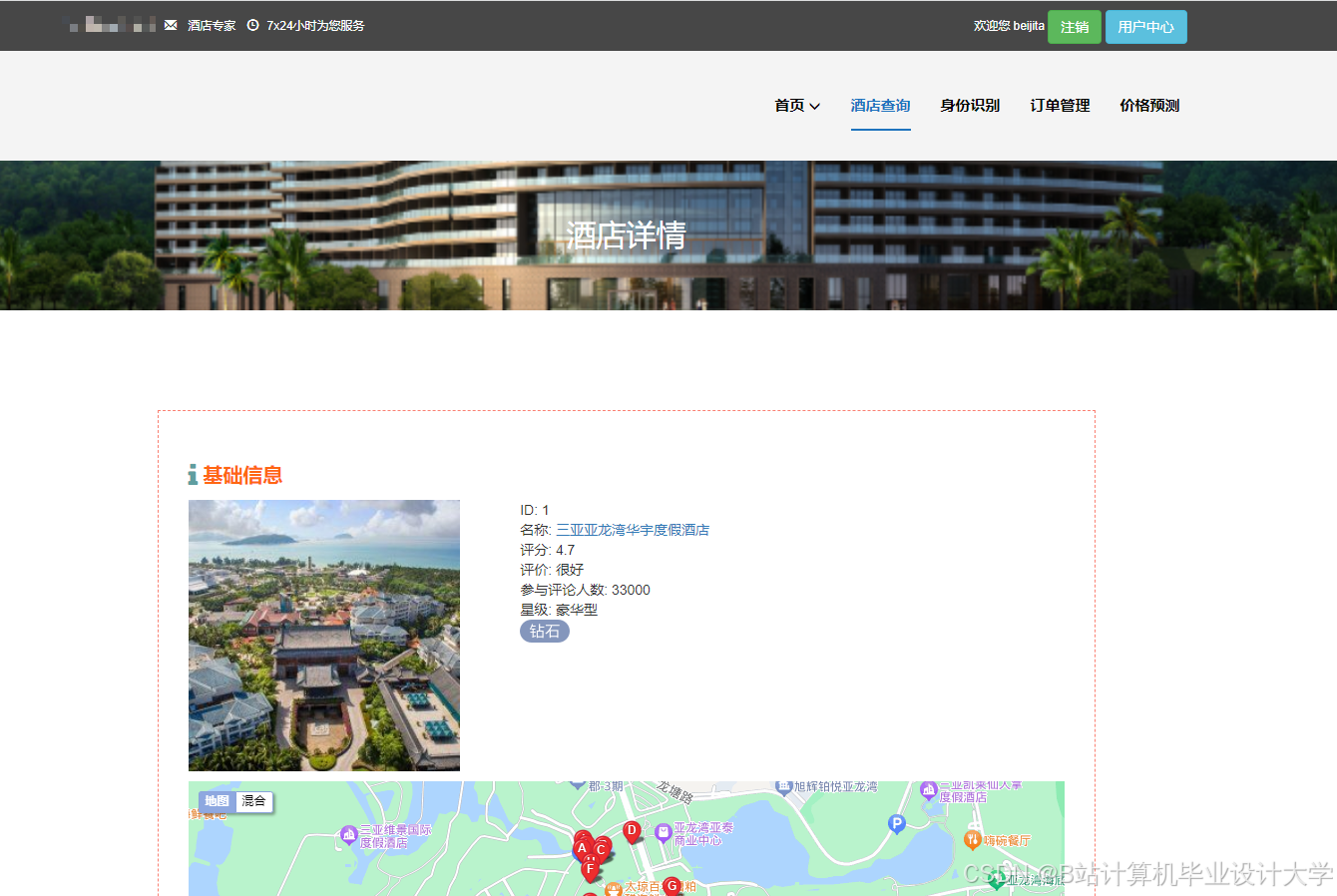
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











